Here’s a No-Ops take on applying modern Site Reliability Engineering (SRE) principles to developing an auto-healing capability for Dataflow pipelines in production on The Google Cloud Platform. In this article, we’ll take a look at setting up a reliable, automated job maintenance framework to intercept and attempt to restart failed Dataflow jobs with a fixed number of retries armed with exponential backoff. We’ll also explore gathering metrics around frequency, periodicity and seasonality of job failures for analytics and automated continuous improvement of the incident response doctrine.
Dataflow is fully managed and scales beautifully
What a beautiful product to execute the open sourced Apache BEAM pipelines so efficiently in a fully automated way. No need to plan for capacity, no need to set up and manage a compute cluster, no need to perform any VM maintenance activities. We don’t even need to think about autoscaling and Dataflow truly delivers on its promise of efficient execution with optimum performance/speed at minimal cost.
It even provides all the metrics around CPU and memory usage across its cluster of GCE nodes, and also useful trends with network, IO, throughput and latency. What’s not to like?
Dataflow works beautifully, as long as the pipelines keep running smoothly
Every once in a while the pipeline/job runs into issues. Maybe the network connectivity experienced a glitch and the database connection was not reliably retried, or maybe the target database table was still being created and took a few milliseconds longer before the pipeline attempted to access it.
In a classic scenario, perhaps a new pipeline was deployed that hounded most of the compute, disc & memory resources leaving very little for already running pipelines to share; so stable jobs running quietly in the background failed to autoscale and crashed.
Or, in rare instances, the project may run out of quotas to autoscale, or even a change in GCP level privileges (IAM/Service accounts) prevented a pipeline from performing some operation mid-flight. Even GCP APIs can time out internally.
Anything that can fail, will fail in the wild. After all, everything is code written by developers!
Dataflow offers manageable risk
It is safe to accept that eventually even the most stable Dataflow pipelines that have been running for a long time will encounter some sort of failure that is beyond the scope of coding business logic within them. Yes, we can try-catch exceptions and we can also smarten-up the pipeline-setup to reliably retry connections with timeouts and exponential back offs.
However, all resilient error-handling will eventually be at the mercy of the underlying infrastructure, which is GCP tenancy and networking. And regardless of how well thought these countermeasures may be, eventually all these fail-safe approaches can do only so much, and they can and will fail.
Can crashing Dataflow pipelines automatically heal themselves?
Typically we manually sift through logs on Cloud Logging, most often we don’t understand the error (it is usually something to do with networking/IO). So we manually restart the pipeline and pretty much 99% of the time this fixes the problem. The age-old tried and tested restart is our best friend.
Very rarely do we see obvious logs pointing to errors in logic that prompt a code or configuration change; as those aspects would have been addressed to a great degree during development of the pipelines. And thankfully, this can be automated to a great extent.
Dataflow allows us to automate administration via API calls
Everything happens through API calls in GCP, and Dataflow follows suit. Let’s attempt to automate this trivial manual recovery operation on GCP.
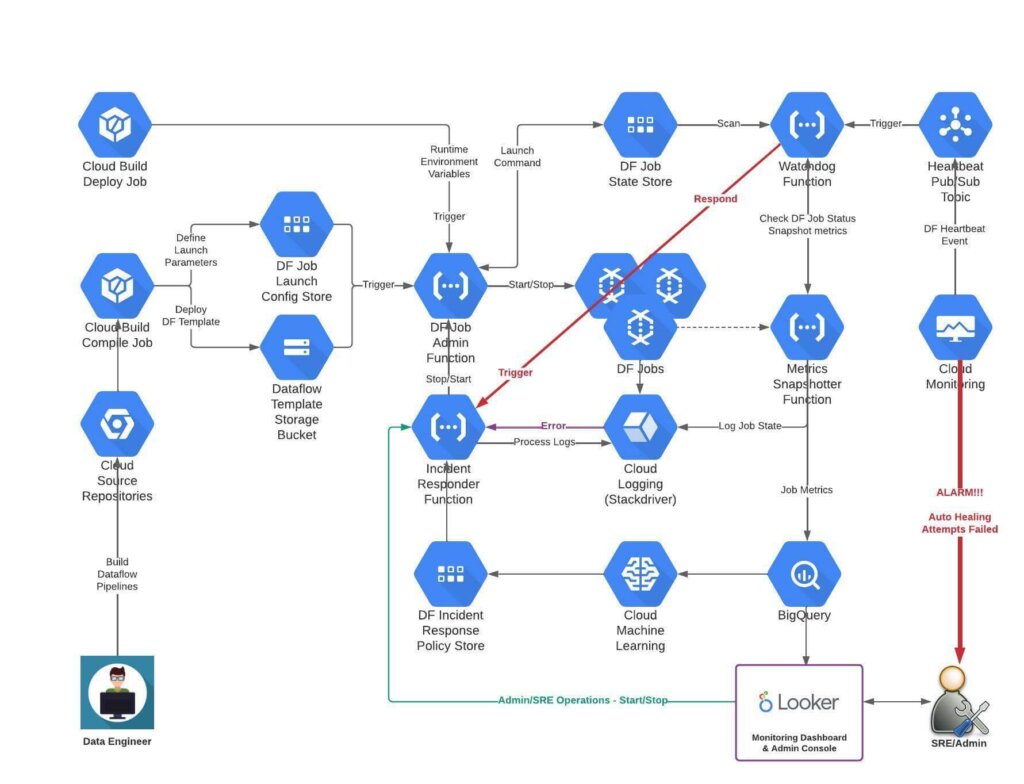
High level design illustrated. Implementation details have been omitted for the sake of brevity.
We love Dataflow indeed. Google Cloud Platform reminds us of LEGO blocks!
But, is it robust? Is it flexible & modular? Does it scale? Let’s go back to the basics of Google’s recommended best practises for a robust system architecture to review our solution design. The following sections outline the best practises as they are applied in this design.
Decouple Lifecycle Stages
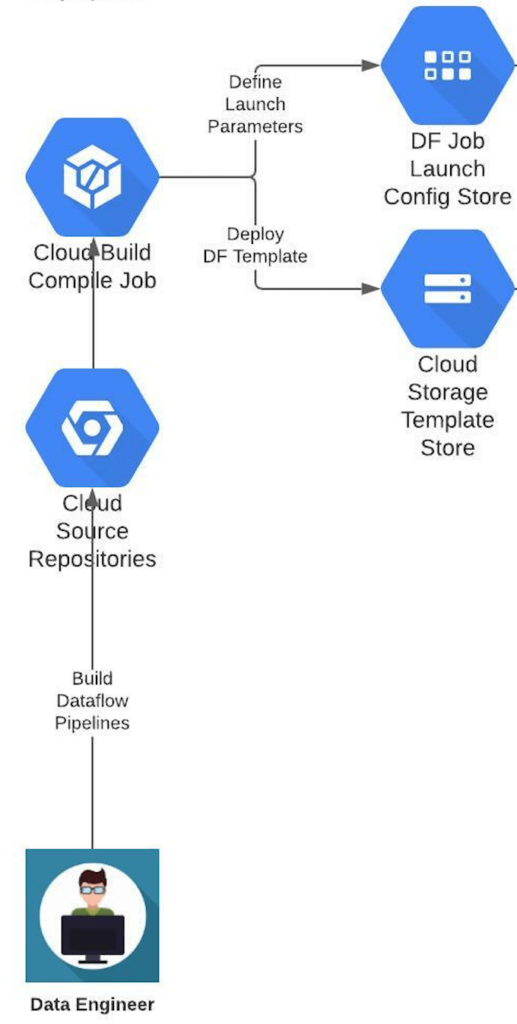
Decouple Dataflow pipeline creation from execution.
It is a classic architectural principle and this is THE reason Spring IOC even exists. Treat all workloads (Dataflow pipelines) as reusable components so that they end up being disposable and replaceable. The cattle vs pets analogy, is at the very heart of highly scalable cloud based computing. Stop putting Dataflow jobs on a pedestal and instead, treat them all alike – like just any other data processing workload in a black box that can be started, stopped, terminated and restarted without having to know anything about their internal specifications.
Enforce that all Dataflow pipelines be compiled into a Dataflow template only through a CI build job. Get the CI build job to create a launch configuration for the Dataflow job, so that parameters can be injected at run time during execution.
Apply Inversion of Control
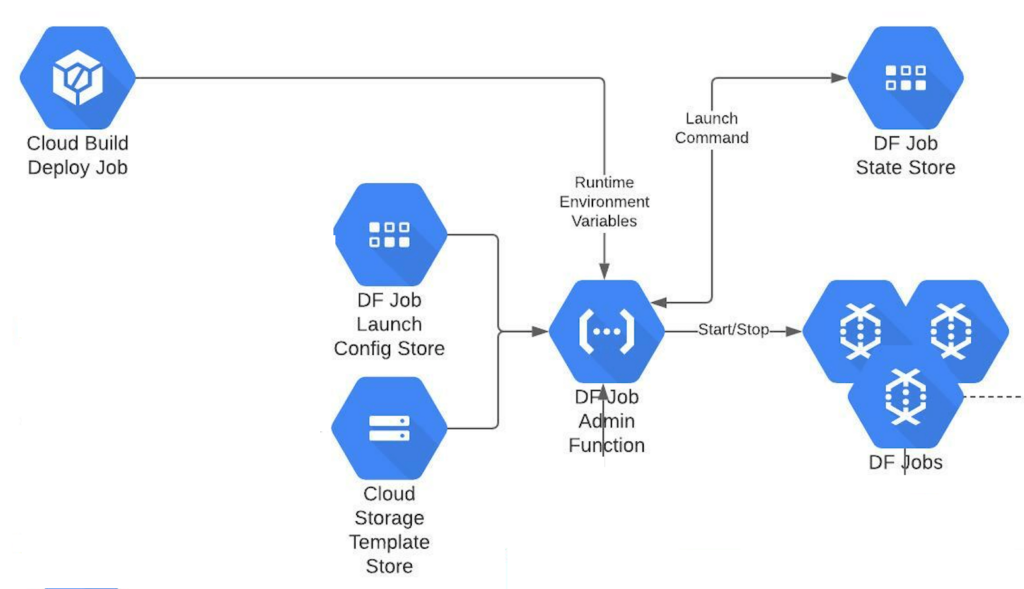
Externalise the launch configuration by turning the Dataflow job launch command into a parameter. This makes the action to trigger any dataflow pipeline a generic operation. This allows our framework to treat all Dataflow jobs alike and to perform administrative operations uniformly. The control now doesn’t lie within Dataflow jobs, but instead in the configuration that is externalised. By abstracting business logic within Dataflow Templates, this design leverages Object Composition and also conceptually honours the Liskov’s Substitution Design Principle (pipelines sort of implement templates).
A single Cloud Function acts as the Dataflow job administrator, and performs all operations – execution of Dataflow jobs from templates, draining jobs, terminating jobs and restarting jobs. This is possible due to the externalisation of launch command and parameters from the job itself. The run time state of all Dataflow jobs can thus be maintained in Datastore.
Leverage Dependency Injection
Encapsulating the entire operation of launching a Dataflow job in a configuration allows us to inject the operational dependency as a set of runtime parameters. The launch configuration thus turns into a command object when executed. Environment variables and any other parameters such as Dataflow cluster specifications can be injected into the launch configuration to complete the job-launch command at run time.
This way, the same Dataflow template can be executed across several environments, just by specifying the corresponding platform/environment variables at the time of launching. This is a true embodiment of “build once, run anywhere” philosophy.
A distributed team of developers can build more & more pipelines in a uniform way, without worrying about how the system will cope/scale. A clear win through CI and CD – not only does the solution scale, even the team can scale as needed, without having any impact on the SRE team and their practices.
Embrace Open/Closed Principle
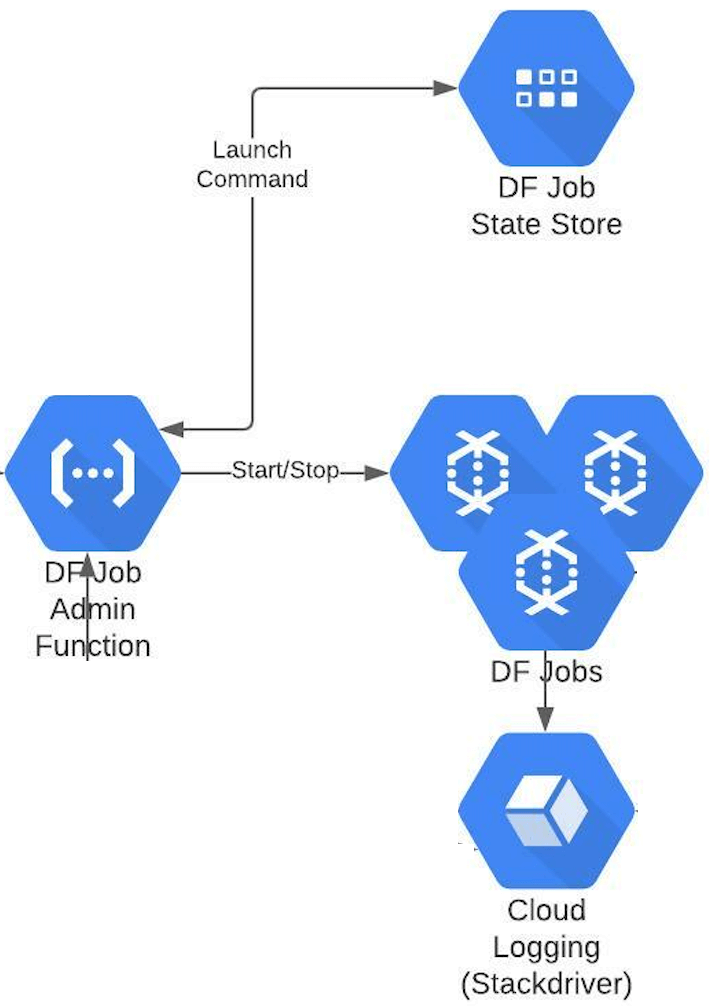
Prohibit the execution of Dataflow jobs directly. Only allow Dataflow job execution from Dataflow templates that are prebuilt & deployed. Set up IAM policies and product configuration to allow Dataflow job execution to be triggered only programmatically from the Job Administrator Cloud Function. While this closes the execution framework for any modification, it leaves the system open for extension – it can scale by adding any number of Dataflow jobs, as long as they’re driven by a template and can be programmatically executed – Open/Closed Design Principle.
Given launching a Dataflow job reduces down to injecting runtime parameters into a launch configuration, there is nothing special or different about launching one Dataflow job from another.
Inculcate Response to Stimuli
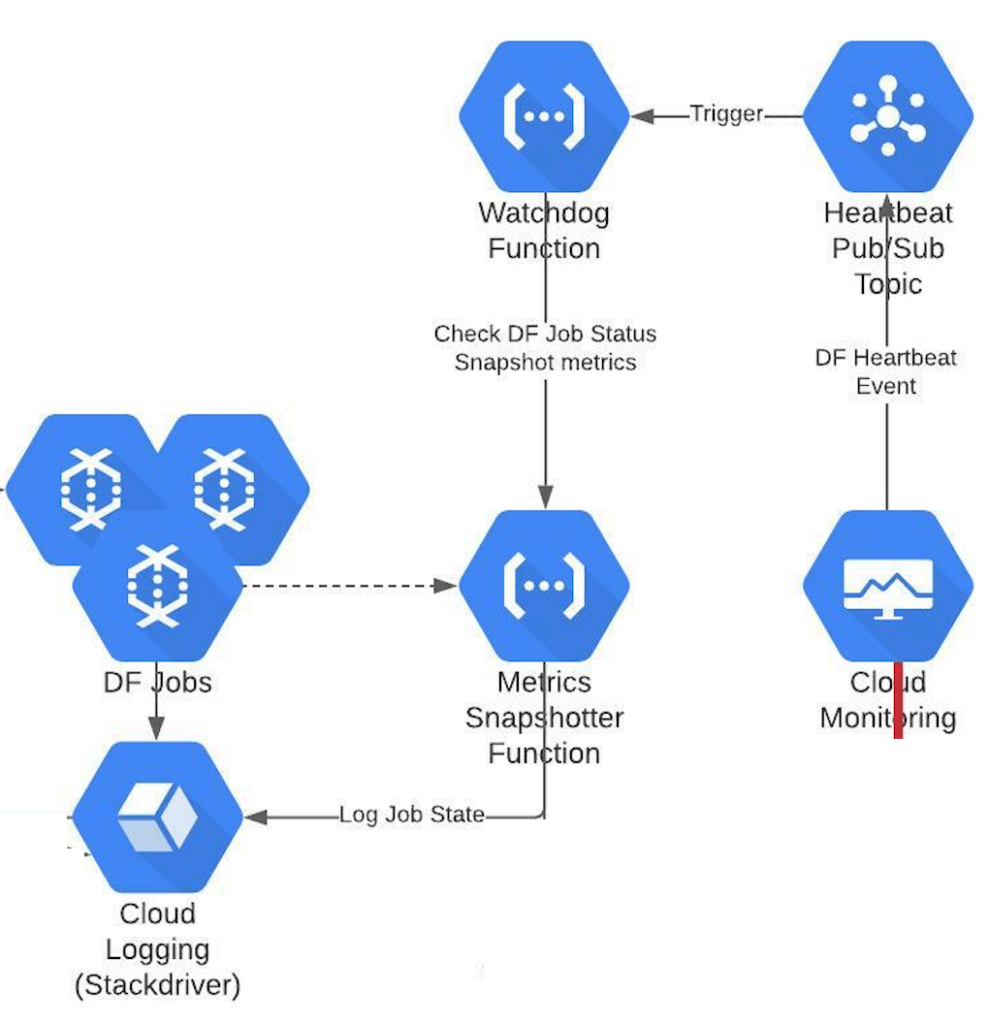
Embrace an event driven, micro services based asynchronous design. Perform Dataflow lifecycle events – job start, job drain and job termination as a response to key operational events such as failure and metric logs. This decouples “what to do with a dataflow job” from “when to do”. Given “how to do it” has already been externalised into a configuration, now it’s only a matter of stringing these pearls together.
Set up Cloud Monitoring to publish Dataflow heartbeat events to a Pub/Sub topic and trigger a Cloud Function to periodically take a snapshot of of resource consumption and performance metrics of Dataflow jobs and log to Cloud Logging (formerly Stackdriver)
Upgrade to No Operations
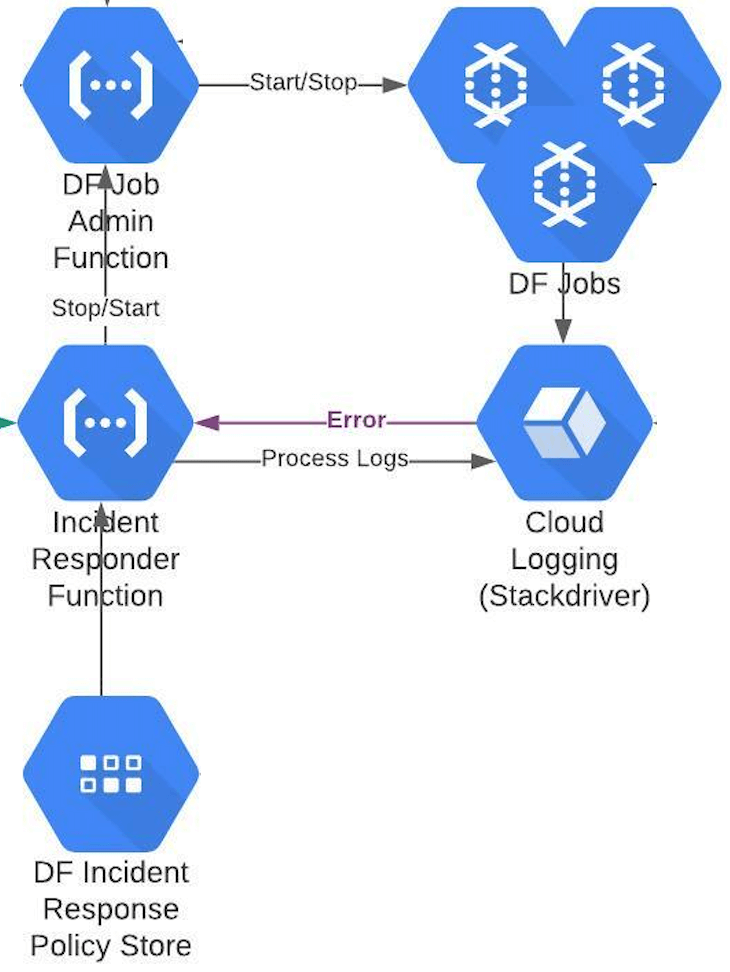
Intercept any errors appearing in Stackdriver and automatically respond to the incident by using a predefined response policy maintained as a configuration in Datastore. A typical response strategy is to drain the Dataflow job, terminate the job if it doesn’t drain within a timeout period, and then to start the job fresh. Of course this policy can grow & scale with need.
Since launch configuration & parameters are already available in the State Datastore, a delegation to DF Job Admin Function can be made just with the job name. The DF Job Admin Function can look up the job launch command from Datastore and execute it as a brand new job.
Remember to set a fixed number of retries with exponential backoff to avoid getting stuck in an infinite restart attempt loop. Give up auto-healing after “n” number of attempts, which then becomes a valid reason to alert the SRE team.
Never Cry Wolf
Only raise alerts when all attempts to automatically recover have failed. An avalanche of low value alerts muffles the critical ones and overwhelms the SRE team through constant bombardment. Reduce the noise that the SRE team has to go through. Follow Alerting Best Practises to reduce low-value alerts that not only kill the valuable SRE time, but also make them numb to alerts if too many get raised frequently. Raise only serious scenarios that can’t be automatically dealt with, as this is where real human potential can be applied. Attempt to automate as many recoveries as possible through metrics based alerting.
Ideally, serious alerts from the past should eventually get downgraded to automatically handled scenarios in the future, thereby reducing the kind of failures the SRE team repetitively handles manually.
Enable Continuous Improvement
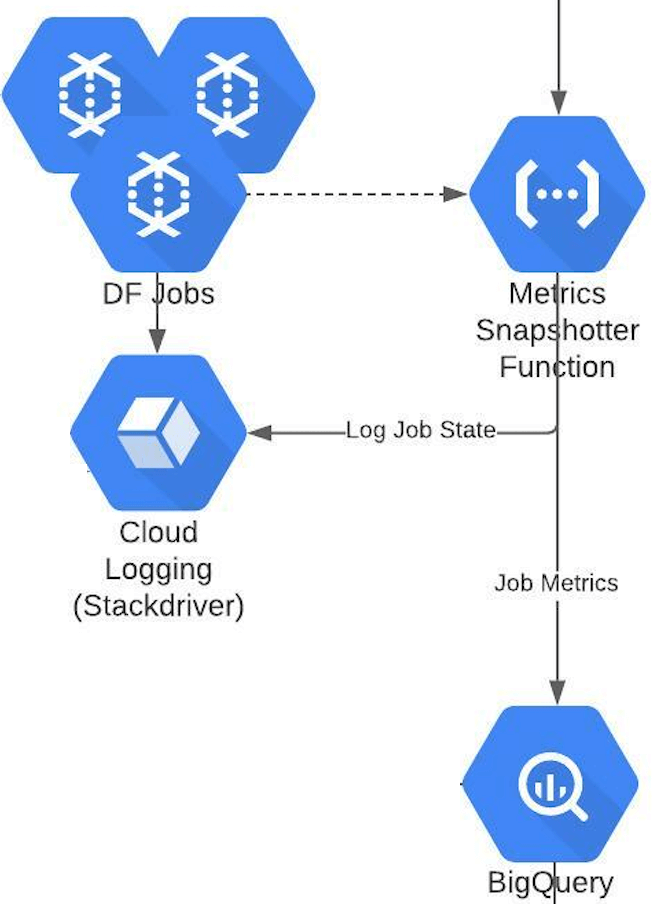
Journal everything; the key to process improvement starts with measurement. Data is the basis for all optimisation, so capture all Dataflow job metrics – errors, logs, a snapshot of all metrics from the compute nodes – CPU, Disc, memory utilisation/load. Capture other parameters at the time of failure, such as metrics of other Dataflow jobs running, in order to cross-correlate GCP resource statistics. Capture seasonality – time of the day, day of the week, week of the year, etc. Build a timeline – record which job fails how often and how long it takes to recover it.
Record how many attempts are required to recover each Dataflow job. Apply these learnings to improve the incident response policy.
Reduce Incidents down to Automated Maintenance
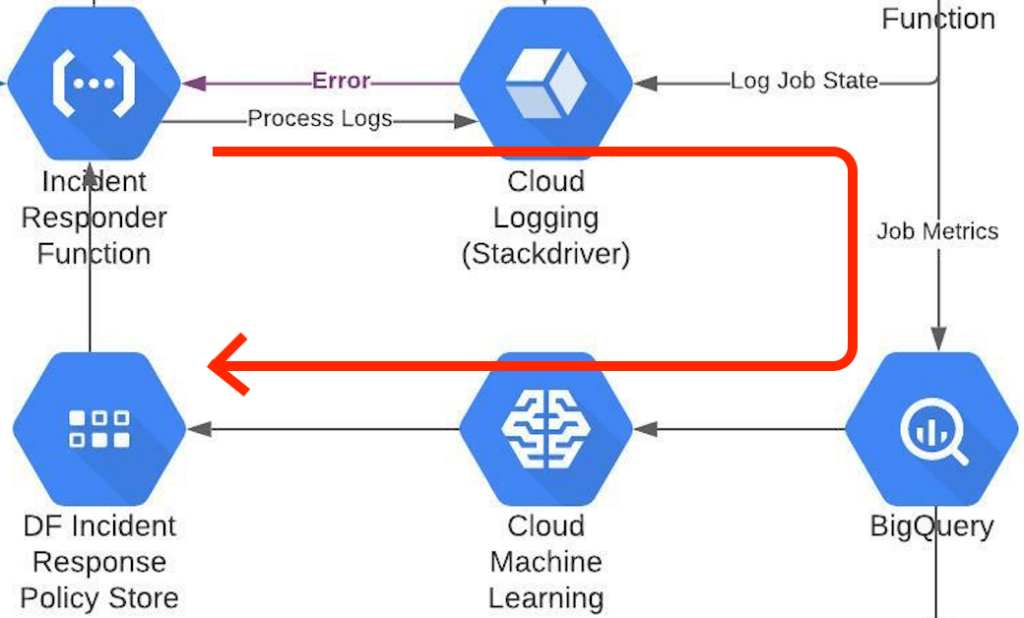
All job metrics & snapshots, when acquired over a period of time, serve as valuable insights into the usage of GCP resources and Dataflow in general. Apply Machine Learning and AI to unlock avenues to improve the automated incident response policies. Learning from the job execution metrics over time, tweak the Dataflow job parameters (e.g. machine type, disc, memory and node population, etc.) periodically upon successive job restarts. Leverage Google’s Recommendation Engine.
Create a feedback loop for the framework to improve itself and measure successive improvements.
Democratise Data
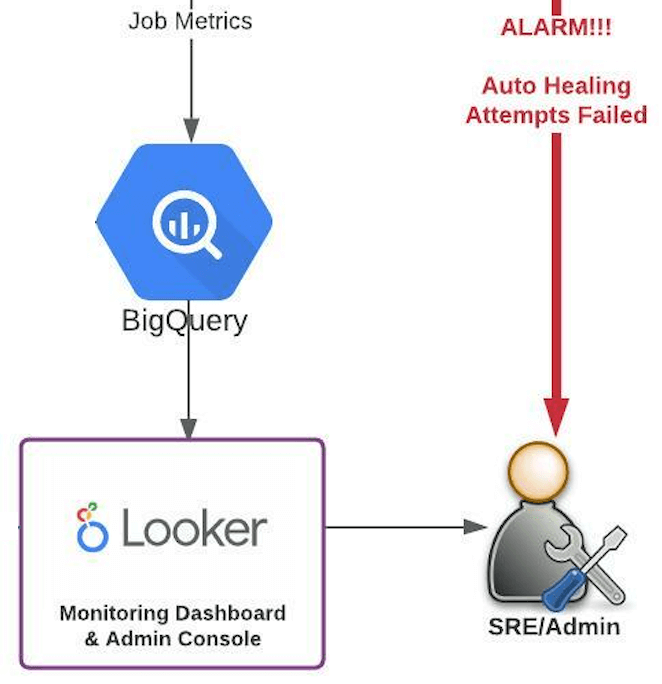
Model the Dataflow job metrics along with resource metrics and autohealing metrics to deduce a measure of efficiency (e.g. uptime, reliability score, etc.). Visualise job metrics, health, uptime & maintenance requirements on a powerful BI platform such as Looker.
With the dashboards available to SREs, drive administrative actions straight from within Looker – e.g. restart a particular Dataflow job.
Present all the reliability metrics associated with each Dataflow job – uptime, reliability score, maintenance durations, frequency & periodicity of failures, seasonality of errors, etc.
Plot and compare changes in these metrics over time to give a measure of the efficiency of the automated recovery policy governance.
Whoa, we adore Dataflow!
There’s so much more we can do with Dataflow on the Google Cloud Platform. Transient failures are also an inevitable aspect of computing; and anticipating the possibility of transient failures is a prudent approach to a well architected system. A resilient design not only embraces failures, but also puts in place dependable measures to assist in troubleshooting and recovery. As the system grows and the number of pipelines balloons from few to dozens to hundreds, an auto-healing framework built on a robust No-Ops foundation becomes absolutely indispensable to utilise the valuable time of your SRE/Ops team efficiently.
Decoupling the 3 lifecycle stages of Dataflow jobs (Pipeline development, Job instance creation, Dataflow job execution) allows for each stage to scale independently.
- The development team can grow/shrink to scale without having any impact on other existing pipelines and the SRE team.
- Dataflow jobs get onboarded/offboarded automatically at scale, irrespective of the development team and/or SRE team.
- The SRE team is able to manage Dataflow jobs at scale regardless of the size of the development team or number of Dataflow pipelines that exist in the system.
Happy Learning.
Dheerendra Nath
Principal Consultant at Kasna | Google Cloud & Big Data Architect
