In this post we’ll take you through the logical steps to configure Okta System logs conversion into parquet files in OCSF (Open Cybersecurity Schema Framework) format and storing them with Amazon Security Lake:
- Design of the solution
- How to set up AWS Glue resources and their role in Okta System logs
- How to set up data conversion in AWS Firehose Delivery Stream
- How to send data to Amazon Security Lake?
- The End Result
Being early adopters in the tech space in general and security in particular, we integrated Okta with AWS a while ago, as soon as this became available. Initially, it was launched for the Ohio us-east-2 region only, which is why we built our Okta System logs aggregation platform in the Ohio region.
The Open Cybersecurity Schema Framework (OCSF) is a collaborative open-source effort between AWS and partners.
The role of an Identity Provider
An enterprise Identity Provider (IDP) plays a critical role in managing access to digital resources within an organisation. An IDP is responsible for authenticating users and providing them with access to the resources they need to do their jobs, while also enforcing security policies and ensuring compliance with regulatory requirements. Okta is a cloud-based identity management platform that provides secure access to applications and data from any device or location. It offers a range of identity and access management (IAM) solutions to help organisations manage user identities, secure access to applications, and automate workflows.
The design of the solution
Core components of the solution:
- AWS EventBridge is a service that makes it easy to build event-driven applications at scale. It allows you to create, route, and process events from various sources and targets using event rules and targets, making it a powerful tool for integrating and automating workflows within your AWS environment.
- An EventBridge event bus is a messaging channel that allows events to be sent and received within your AWS environment.
- An EventBridge event rule is a configuration that defines the criteria for processing events in your AWS environment. It acts as a trigger for an action to be taken when an event occurs that matches the specified criteria.
- AWS Lambda is a serverless compute service that allows you to run your code without provisioning or managing servers. It lets you run your code in response to events, for example new login with Okta.
- AWS Glue plays a critical role in data transformation when used with Amazon Kinesis Data Firehose. Amazon Kinesis Data Firehose is a service that enables you to ingest, transform, and deliver real-time streaming data to various destinations, including Amazon S3, Amazon Redshift, and Amazon Elasticsearch. The combination of AWS Glue and Amazon Kinesis Data Firehose enables you to build real-time data pipelines that can transform and deliver streaming data to various destinations, making it easier to analyse, visualise, and derive insights from your data in near real-time.
- S3 is a highly scalable, durable, and secure object storage service that can store virtually unlimited amounts of data. Using S3, you can store all types of data in their native format, including logs, sensor data, images, videos, and documents, and organise them into logical data sets using prefixes and object tags.
- Amazon Security Lake is a central repository that collects and stores security data from various sources, allowing you to gain insights into your security posture, detect and respond to security threats in real-time, and comply with security and regulatory requirements.
Before you ingest Okta system logs with Amazon Security Lake, ensure that you have completed all of the steps defined in this Okta Documentation. The process of sending Okta Logs to Amazon EventBridge is straightforward and shouldn’t take long once you have the required access. On completion of these steps, you should have an Okta EventBus and an event rule that listens to your Okta EventBus.
For EventBridge rule #1, we have chosen AWS CloudWatch as the target so that we can see data in near real-time in a human-readable format on every successful login within Okta in a log group. Every log stream contains complete data on each successful login with Okta.
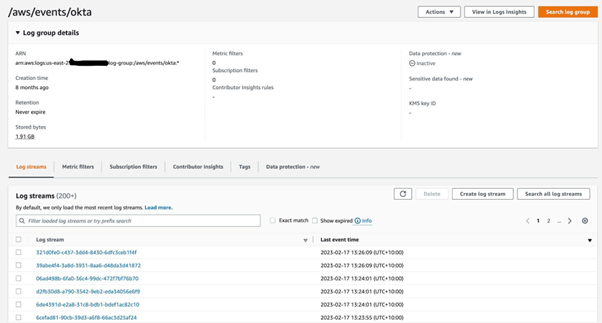
EventBridge rule #2 triggers Lambda on every event received from Okta. Lambda’s goal is to convert Okta logs to OCSF format and call the AWS Firehose delivery stream with a put-record request. Lambda’s code: https://gist.github.com/julia-ediamond/7b78591011e630bc28c28a8029b8a862
How to set up AWS Glue resources and their role in Okta System logs
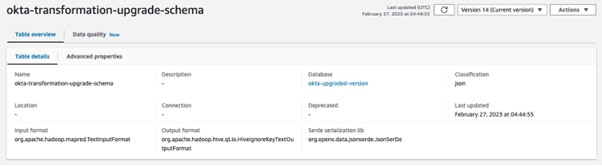
A Glue table will store a Schema Configuration and Kinesis Data Firehose will look it up to parse Okta logs before sending them to the S3 bucket. Database creation is straightforward and requires only providing a name for it. The Glue table requires more configuration and this is what the end result should look like:
Fields in a Glue schema should be identical to the original JSON because the schema defines the structure of the data and how it should be interpreted. If the schema is not identical to the original JSON, there is a risk that some of the data may be lost or incorrectly interpreted.
If the fields in the Glue schema are different from the original JSON, Glue may not be able to correctly parse the data and may generate errors. In addition, downstream processes that consume the data may expect the fields to be named and structured in a particular way, and if the schema is not consistent with the original JSON, these processes may fail or produce incorrect results.
This is what our schema looks like in the console:
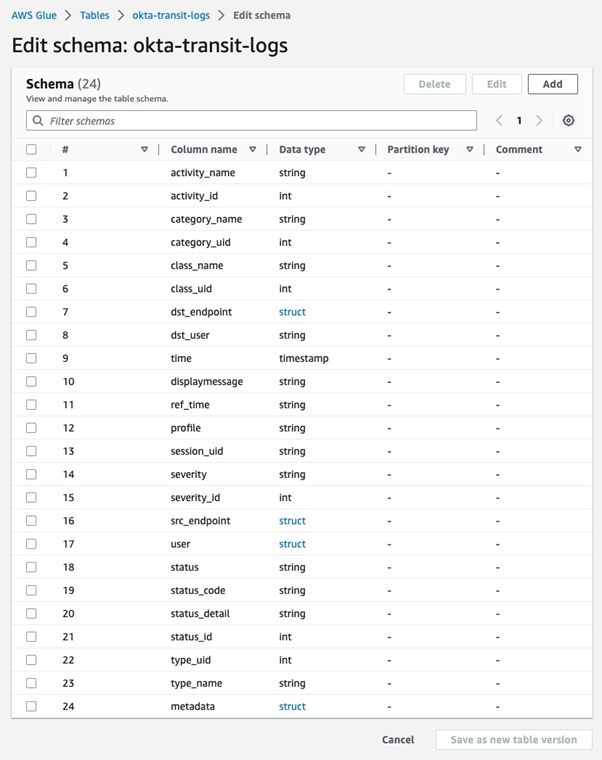
Schema in JSON:
[
{
"Name": "activity_name",
"Type": "string",
"Comment": ""
},
{
"Name": "activity_id",
"Type": "int",
"Comment": ""
},
{
"Name": "\tcategory_name",
"Type": "string",
"Comment": ""
},
{
"Name": "category_uid",
"Type": "int",
"Comment": ""
},
{
"Name": "class_name",
"Type": "string",
"Comment": ""
},
{
"Name": "class_uid",
"Type": "int",
"Comment": ""
},
{
"Name": "dst_endpoint",
"Type": "struct<hostname:string,ip:string,instance_uid:string,interface_id:string,svc_name:string>",
"Comment": ""
},
{
"Name": "dst_user",
"Type": "string",
"Comment": ""
},
{
"Name": "time",
"Type": "timestamp",
"Comment": ""
},
{
"Name": "displaymessage",
"Type": "string",
"Comment": ""
},
{
"Name": "ref_time",
"Type": "string",
"Comment": ""
},
{
"Name": "profile",
"Type": "string",
"Comment": ""
},
{
"Name": "session_uid",
"Type": "string",
"Comment": ""
},
{
"Name": "severity",
"Type": "string",
"Comment": ""
},
{
"Name": "severity_id",
"Type": "int",
"Comment": ""
},
{
"Name": "src_endpoint",
"Type": "struct<hostname:string,ip:string,interface_id:string>",
"Comment": ""
},
{
"Name": "user",
"Type": "struct<type:string,name:string,email_addr:string>",
"Comment": ""
},
{
"Name": "status",
"Type": "string",
"Comment": ""
},
{
"Name": "status_code",
"Type": "string",
"Comment": ""
},
{
"Name": "status_detail",
"Type": "string",
"Comment": ""
},
{
"Name": "status_id",
"Type": "int",
"Comment": ""
},
{
"Name": "type_uid",
"Type": "int",
"Comment": ""
},
{
"Name": "type_name",
"Type": "string",
"Comment": ""
},
{
"Name": "metadata",
"Type": "struct<original_time:string,version:string,product:struct<vendor_name:string,name:string>>",
"Comment": ""
}
]
This is what the edit mode looks like in the console: 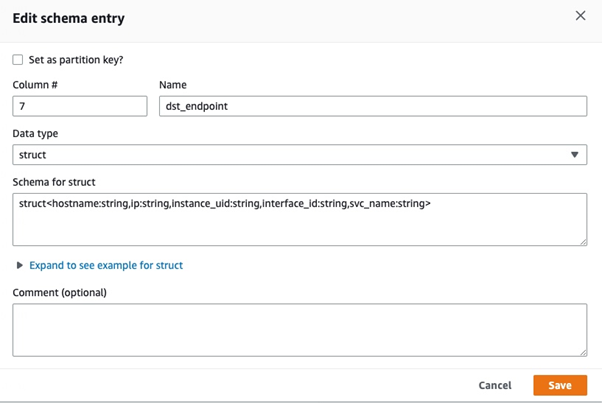
You can add as many data items as you need. The main thing here is to keep the naming consistent with your original Okta logs JSON, as naming data fields differently will cause errors.
How to set up data conversion in AWS Firehose Delivery Stream
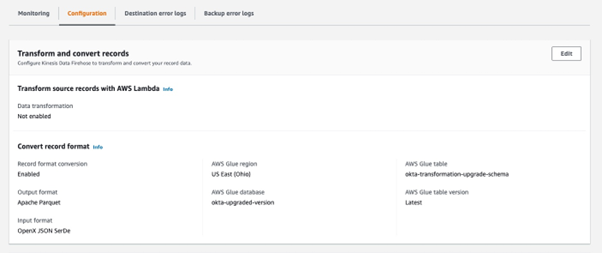
Parquet is a data file format for efficient data handling. This is also the only format suitable for Amazon Security Lake. Here’s a simplified overview of using AWS Kinesis Firehose to convert data into Parquet format:
- Firehose receives data from a data source and buffers it until it has accumulated a certain amount of data or a certain amount of time has passed.
- Firehose then performs data conversion by transforming the data into Parquet format. Firehose uses a combination of compression, encoding, and other techniques to optimise the data for storage and query performance.
- Once the data is converted into Parquet format, Firehose delivers it to the destination that you have specified, such as an Amazon S3 bucket.
- You can then use various tools and services to query and analyse the data in Parquet format.
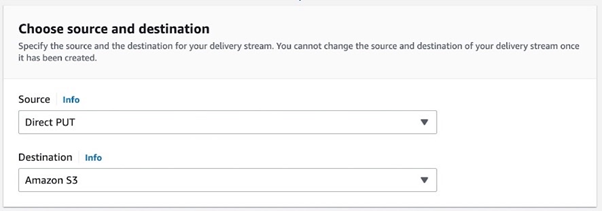
To create a Firehose delivery stream, choose the source and destination. We use it with a direct PUT, which requires a Write request from a producer application, a Lambda in our scenario. Firehose will require a Glue database with a Glue table to store the schema.
How to send data to Amazon Security Lake?
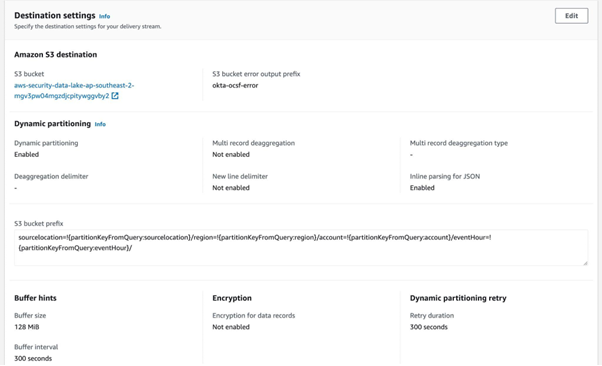
The destination for streaming data is going to be an S3 bucket managed by Amazon Security Lake.
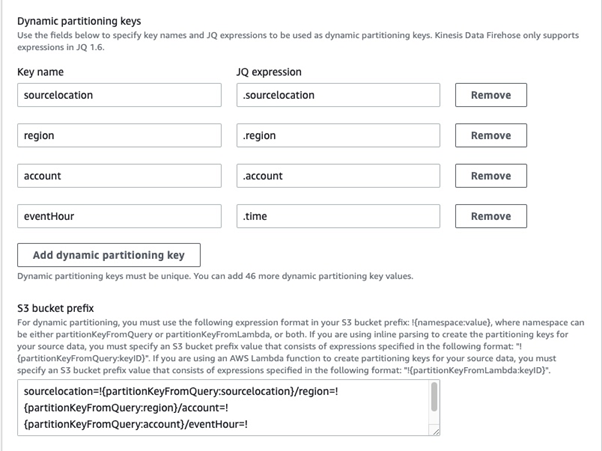
Amazon Security Lake requires dynamic partitioning. In simple words, dynamic partitioning is the process of dynamically creating subdirectories in a directory structure to store data based on the values of specific columns in the data. Data objects must be partitioned by region, AWS account, year, month, day, and hour. Objects should be prefixed with “<source
location>/region=<region>/accountId=<accountId>/eventHour=<yyyyMMddHH>/“.
<source location> is the location provided to the customer by Amazon Security Lake when the customer registers the custom source. All S3 objects for the given source are stored under this prefix, and the prefix is unique for this source.
<region> is the AWS region to which the data is uploaded. For example, data first written to the customer’s Amazon Security Lake bucket in the us-east-1 region should use “us-east-1”.
<accountId> refers to the AWS account ID that the records in the partition pertain to.
<eventHour> is the UTC timestamp of the record, truncated to hour, and formatted as the 10-character string “yyyyMMddHH”. If records specify a different timezone in the event
timestamp, the timestamp must be converted into UTC for this partition key.
The S3 bucket error output prefix is a prefix for Kinesis Data Firehose to use when delivering data to Amazon S3 in error conditions.
When adding dynamic partitioning, this is how we did it:
We also chose to enable source record backup, as it provides an extra layer of protection for the data stored. By replicating data to a secondary location, you can minimise the risk of data loss. As Firehose uses S3 to backup all or failed data, we created another bucket called okta-logging-backup with the S3 backup bucket prefix source_records/
After filling in all fields and hitting the Create delivery stream button, you will most likely run into an error.
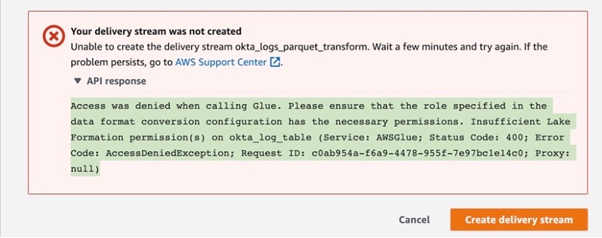
Why do I get an AWS Lake Formation error despite the fact that I haven’t created it?
Good question! This is the error we have spent a fair bit of time solving. First of all, when you create a Glue resource you get AWS Lake Formation by default. It is an additional layer that sits on top and manages Glue resources, their principles and permissions. It is a service that makes it easier to set up, secure, and manage data lakes on AWS. AWS Glue is a data processing service that helps transform data into a format that can be stored and analysed in a data lake, while AWS Lake Formation is a service that helps create and manage the data lake itself. AWS Lake Formation and AWS Glue are both services that are used in the creation and management of data lakes on AWS. While AWS Glue is primarily used for data processing and transformation, AWS Lake Formation provides a set of tools and features to help create and manage the data lake itself. If you go to the Lake Formation console and click Data Catalog in the menu on the left, you will find your newly created Glue database and table sitting there.
What is the role specified in data format conversion configuration?
Open CloudTrail, wait a couple of minutes, refresh and open the most recent event called CreateDeliverySteam. If you read the event record, you can see dataFormatConversionConfiguration and roleARN specified there. This role is being created along with Delivery Stream and you need to grant it permissions in Lake Formation to manage the Glue table.
- Keep the window with your Firehose delivery stream open, so you don’t have to fill in all the fields again.
- In the new window open the AWS Lake Formation console, and click the Data lake permissions tab on the left.
- Click the Grant button on the right.
- In the Grant data permissions window click on the IAM users and roles dropdown and choose the role with the ARN mentioned in your dataFormatConversionConfiguration. Choose Named data catalogue resources.
- From Databases select your Glue database
- In Tables select your Glue table.
- In both the Table permissions and Grantable permissions tick Super.
- Click the Grant button.
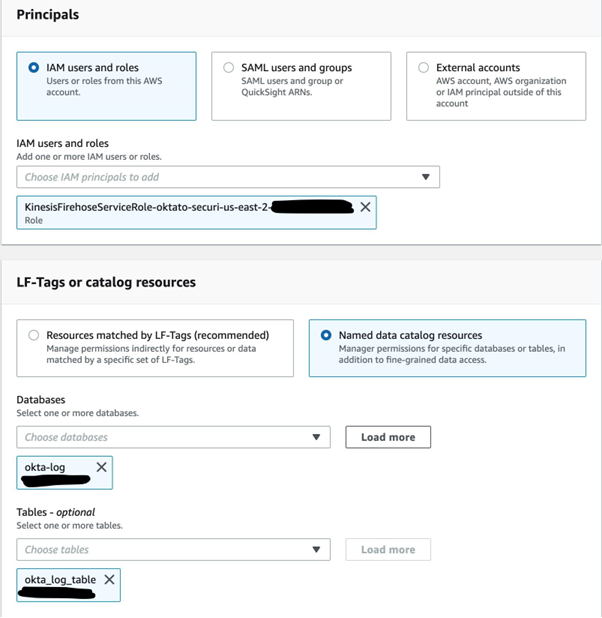
Now the permissions for the Glue table have been sorted and you can go back to the Firehose delivery stream window exactly where you left off and click Create delivery stream button again. It will take a moment and you should see that your delivery stream has been created and has the active status with a green tick.

To trigger the Okta system log conversion, generate an Okta event by signing out from your Okta and signing in back. Wait a few minutes, and then check the S3 bucket that you have set as a destination in Firehose. On success, you should see that Firehose has created a new folder sourcelocation=aws.partner/ as we partitioned it. If you go into it, you will see a newly created record in parquet format.
How to check that Okta logs conversion works correctly?
- Tick the box next to your parquet file
- Click Actions
- From the dropdown choose Query with S3 Select
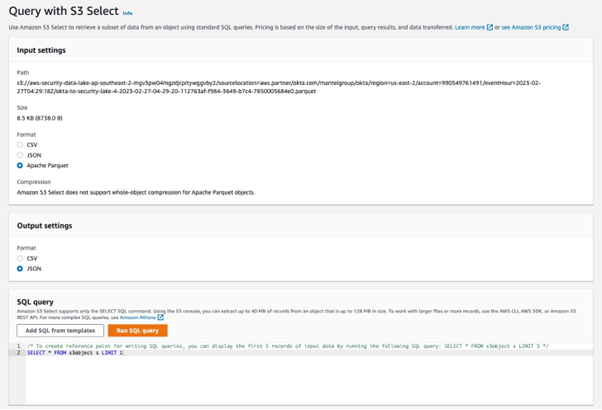
- Click Run SQL query
- In Query results you will see the contents of your parquet file
The End Result
Now that we have configured Okta log ingestion into Amazon Security Lake, each time when somebody authenticates with Okta, it will trigger the system logs conversion process and new records will be written to the S3 bucket that is managed by Amazon Security Lake.
The documented solution applies a ClickOps approach suitable for development and testing. For a production implementation we recommend the use of infrastructure as code.
Having Okta logs in a Security Lake can help them with:
- Better security: When companies store Okta logs in Security Lake, they can see if someone is trying to get into the system without permission. This helps them to quickly stop security problems.
- Meeting compliance obligations: Many companies have compliance obligations they need to follow, like HIPAA or GDPR. By putting Okta logs in one place, companies can more easily meet their compliance obligations.
- Learning more: Companies can look at the Okta logs to learn things, like which programs people are using and how often. This can help them save money and find new ways to improve.
- Keeping everything together: When companies keep all the Okta logs in one place, it is easier to manage them. It also makes sure they don’t lose the data.
- In short, having Okta logs in a security data lake can help companies be more secure, follow rules better, learn more, and manage their data better. By putting all the logs in one place, it is easier to see everything that is happening, which helps companies stay safe and make good choices.
Setting up a security data lake can be a complex process that requires expertise in security, data management, and cloud infrastructure.
CMD Solutions offers consulting and advisory services to help organisations design and implement Security Lake on AWS. Our experts can provide guidance on best practices for security, data management, and cloud infrastructure. We also can provide a range of services, from architecture design to implementation and ongoing support.
