Published May 30, 2022
Cricket Australia’s goal was to explore the value and possibility of accurately predicting elite batting performance in One Day International cricket (ODI) based on junior performance data. In practical terms, coaches wanted to explore if advanced analytics could assist them to identify which junior players may have the potential to become elite professional players in the future.

The situation
Cricket Australia’s goal was to explore the value and possibility of accurately predicting elite batting performance in One Day International cricket (ODI) based on junior performance data. In practical terms, coaches wanted to explore if advanced analytics could assist them to identify which junior players may have the potential to become elite professional players in the future. We didn’t explore predictions of elite ODI bowling success due to the short time frame of the project.
The approach
We completed a Data Science project over four weeks with the Cricket Australia High Performance team. Our objective was to identify the most relevant characteristics (features) of junior players that might predict elite ODI batting performance using analytics and data science techniques. To do this, we analysed the following data sets:
My Cricket Data:
- Junior and senior player data from every innings across every club and level in Australia
- This dataset was used as features in the machine learning modelling
Pathways Data:
- Data from players who have been selected in an elite ‘pathways’ squad
- This dataset was used to firstly determine whether a player had made the elite ODI Australian team, and then to match their elite data to their My Cricket junior performance data.
Results
Descriptive statistics
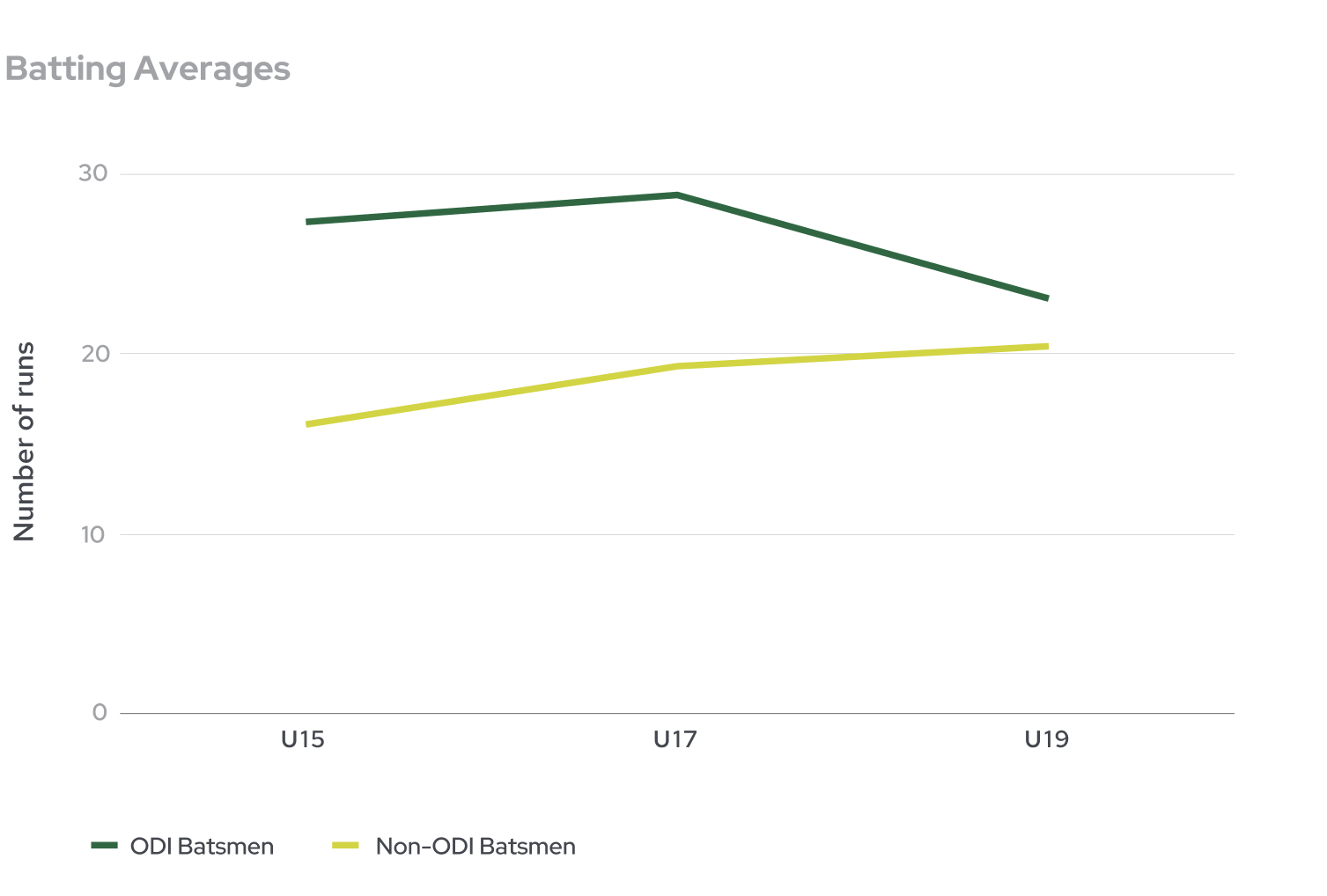
We found that junior players from U15s to U19s who made ODI teams tended to have higher (but not statistically-significant) batting averages.
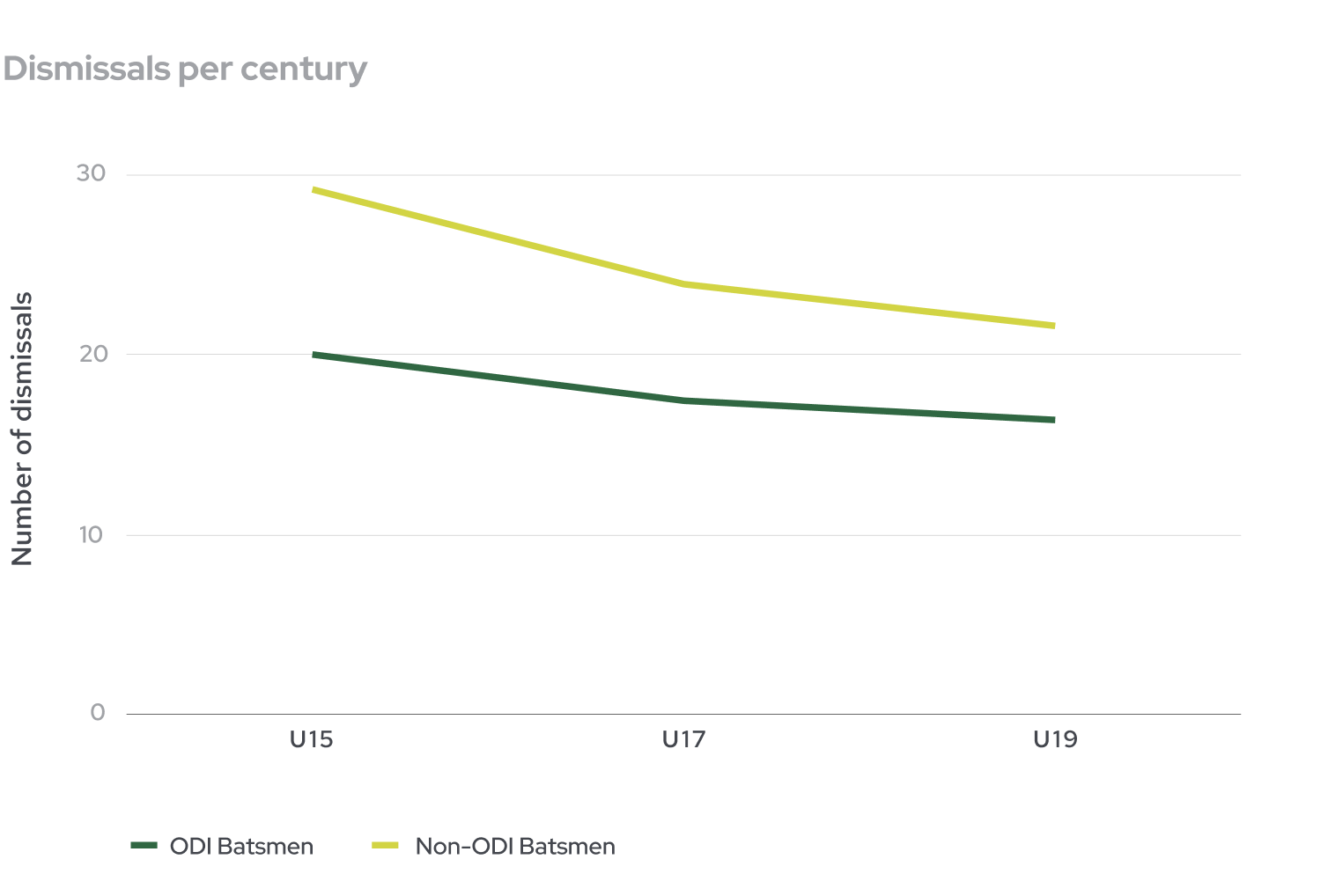
There was also an obvious difference (albeit non-statistically significant) between the number of dismissals per century scored. We found that the junior players who went on to be selected in ODI teams were dismissed less per century scored, indicating they were scoring centuries more frequently and/or scoring centuries in more ‘not out’ innings.
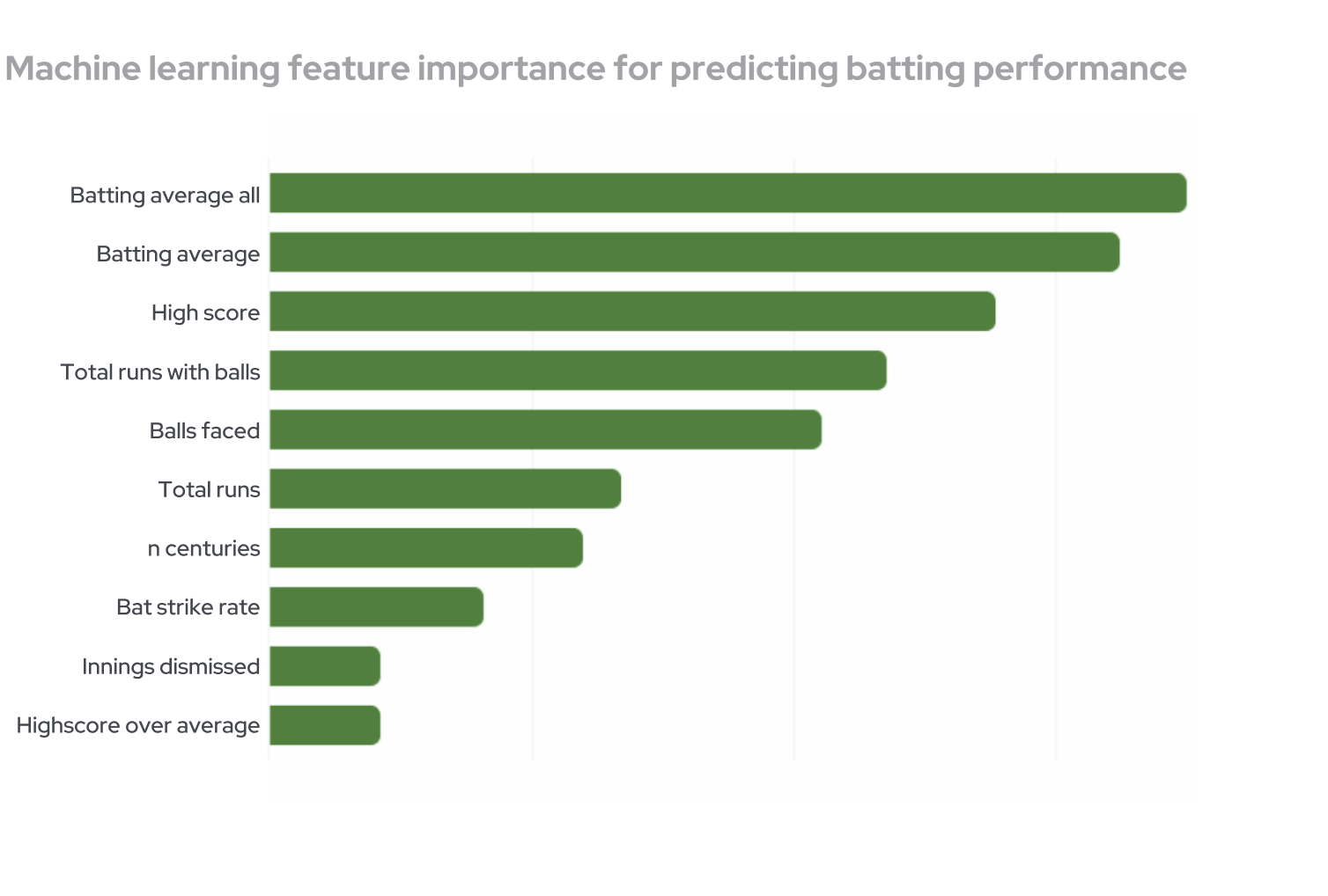
Machine learning
Using machine learning2, we found that the most predictive characteristics that relate to batting performance are batting average (‘Batting avg all’ is the total runs divided by total innings, compared to the traditional ‘Batting avg’ calculation of total runs divided by total innings where dismissed), high score, total runs ( ‘Total runs with balls’ is the total runs divided by total balls faced), and total balls faced (indicating that better batters tend to face more balls in their career). While there were data limitations with properly differentiating between elite and non-elite players, these findings can still provide coaches with insights on which characteristics to prioritise when making decisions on which players to offer development contracts.
Business outcomes
Mantel Group provided Cricket Australia with insights derived from a pilot data science project aiming to identify the characteristics in junior cricketers that are related to elite ODI batting performance. To build this data-driven decision making into their selection processes, we recommended building a management dashboard that surfaces the relevant predictive metrics for each junior player to enable selection decisions for representative squads. To improve machine learning predictions, we also recommended identifying a more homogenous group of players who face more comparable playing conditions to those faced by elite players.
Critical to the project’s success was early engagement with the cricket subject matter experts (SMEs) to agree on the business problems, and also the technical SMEs to understand the data and limitations. It was also beneficial to have deep and early engagement with Cricket Australia’s data scientists to understand their previous work and feature selection and engineering to build off and prevent repetition of previous work.
1 https://www.cricketaustralia.com.au/about/our-strategy
2 We have used random forest models for “feature selection”. Random forest models are a powerful type of ensemble model, which combines the results of a number of decision-tree models, using independent random samples of the data (bootstrapping).
