
Let’s get started
In this post, we’re going to get you started on Databricks, but first let’s take a quick look at the history of big data space. Spark has become the de facto standard tool for processing big data in the last few years or so. In a nutshell, HADOOP was too slow, clunky and hard to use. Spark execution engine is much faster and reliable. No more writing complicated map-reduce jobs that are hard to maintain and slow like a turtle. Spark provides high level APIs easy to use which can be written in Scala, Java, Python, SQL and R. So whatever your skillset or role, there is a good chance that you can be productive on Spark in a short period of time. Also Spark comes with a bunch of nice batteries included. If you have an ML or graph analytics problem, Spark ML or Graphx are there to help.
Since the dawn of the big data age many companies have provided their own flavours of big data tools. Two of the major players are Hortonworks and Cloudera which merged into a single company a few years ago. MapR was also a key player. But one other company really stands out when it comes to Spark. Its name can be even considered a Spark synonym to some extent and that is Databricks. It creates many other data-related technologies in addition to Spark and it really embraces open source software. Databricks is available on AWS, Azure and GCP and integrates seamlessly with other services on such platforms. This post will use Databricks community edition but the same workflow applies identically if you prefer to use Databricks with a cloud provider account.
In this post, Databricks will be used to show an end to end hello world Spark application. The tutorial is divided into two parts where the first part will set up the stage to run a simple hello world example and the second part will demo some Spark and Databricks capabilities against a real world dataset.
Databricks has paid service plans for sure but it also provides a community edition for learning and experimentation. It’s still limited to a single node cluster but you get to play with notebooks and several other cool features you cannot get from a vanilla plain Spark installation.
Databricks is one of the easiest options to code/run Spark applications and other data and AI tools as well. Still, there are other options that could be useful in certain scenarios or at least good to know. Please have a look at the appendix in this post to learn more.
All source code from this tutorial is available below.
Setup Databricks Community Edition environment
To keep things simple, here are the general steps to get access to a Databricks Community Edition account.
Get a Databricks Community Edition account
1.
Navigate to https://databricks.com/try-databricks
2.
Fill the required details. A personal email is preferred because a company email here can cause issues later when you want to add yourself to the company Databricks account.
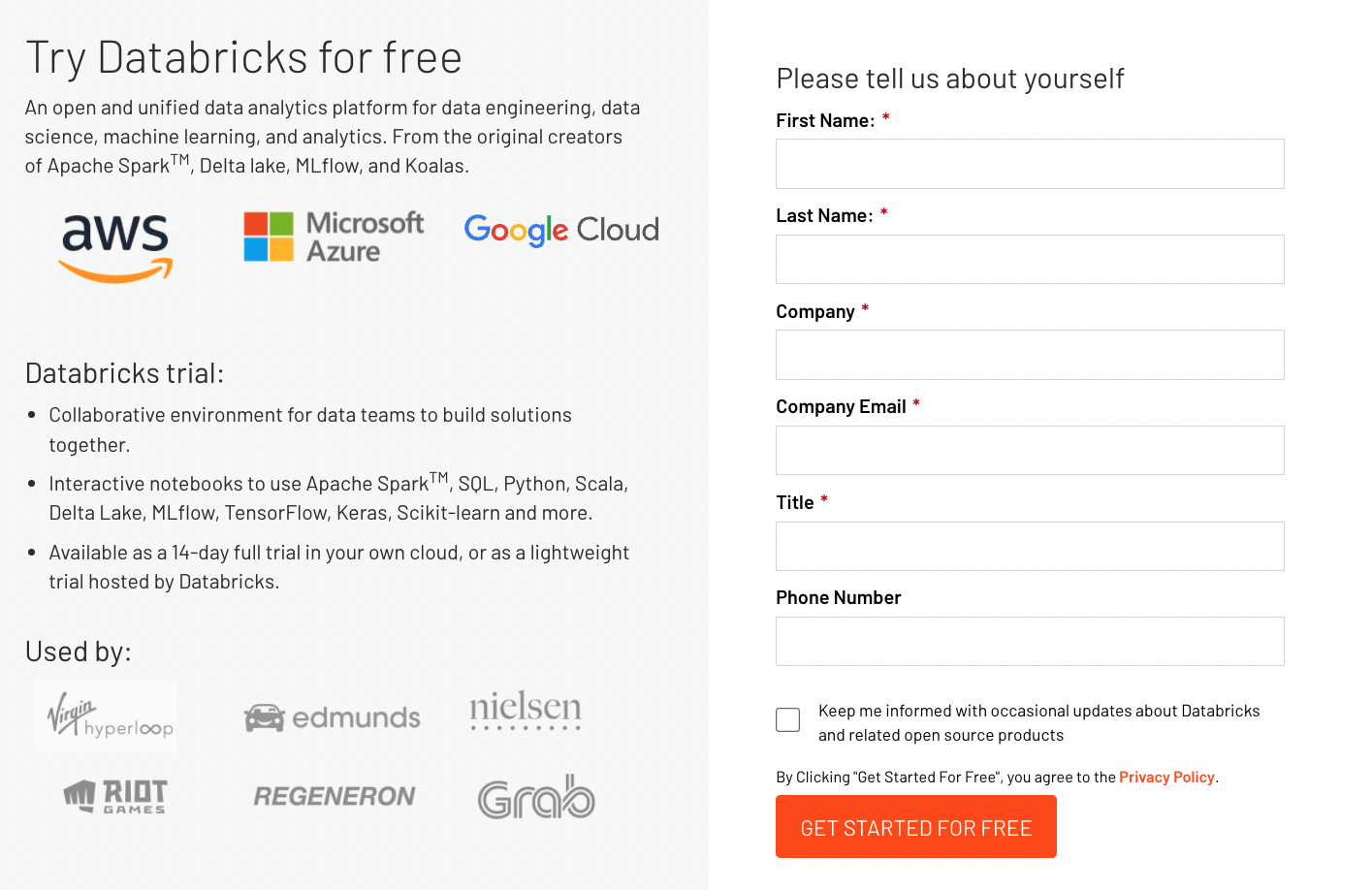
3.
Next step will be about choosing whether to use your own cloud provider account if you have one with AWS/Azure/GCP or use community edition from Databricks without a cloud provider account. It would be usually simpler to not rely on a cloud provider account, so click the link named “Get started with Community Edition”.
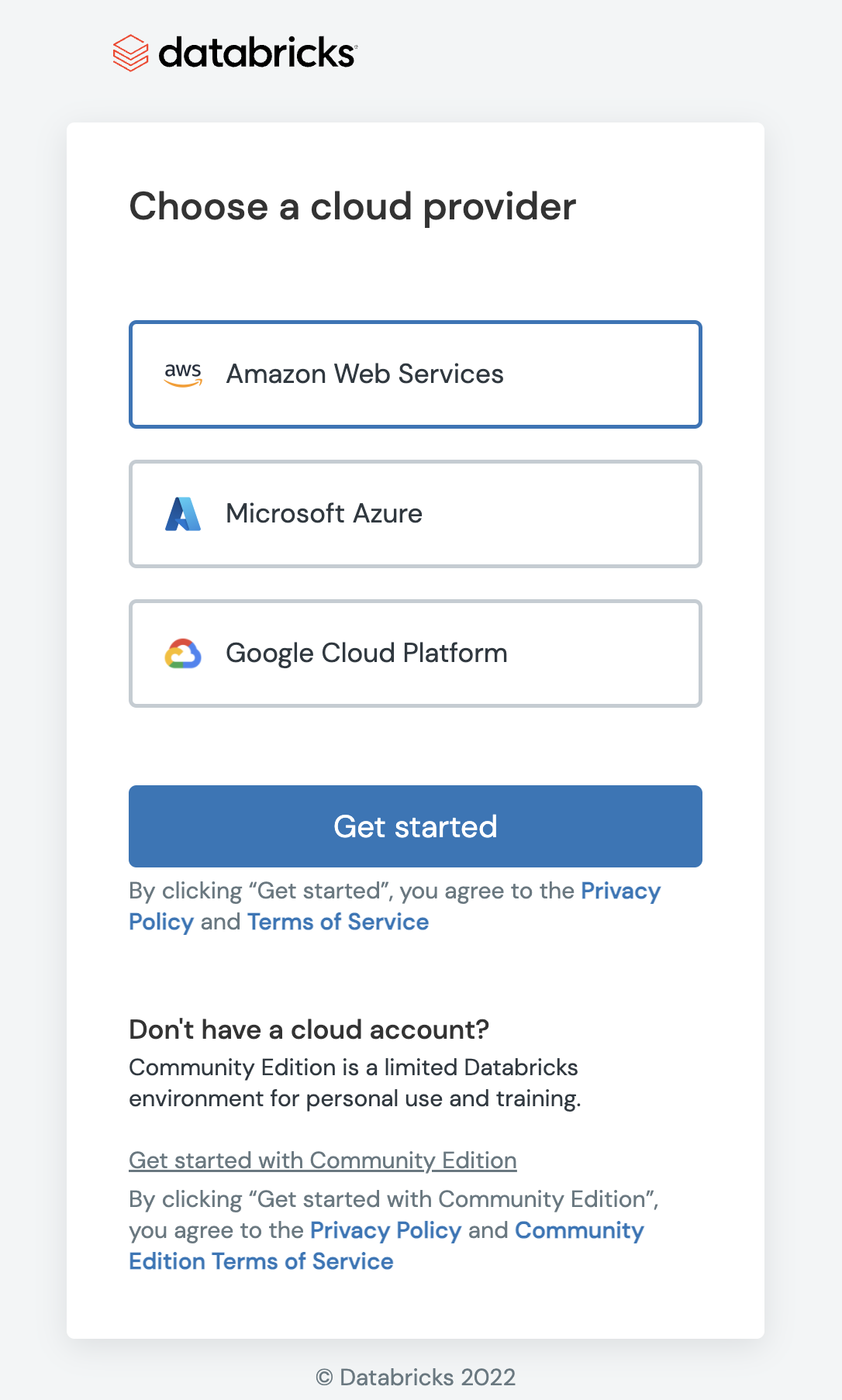
4.
You will get a confirmation email to verify your email address.
5.
Once confirmed you will need to create an account password and log in to your community edition workspace.
Prepare a Spark cluster in your workspace
1.
To run some Spark code, you will need to have a running cluster. A cluster is a group of machines that run your data processing jobs. Hover over the sidebar until you see a link named Compute and click it to open Compute page.
2.
From there, click Create Cluster button.
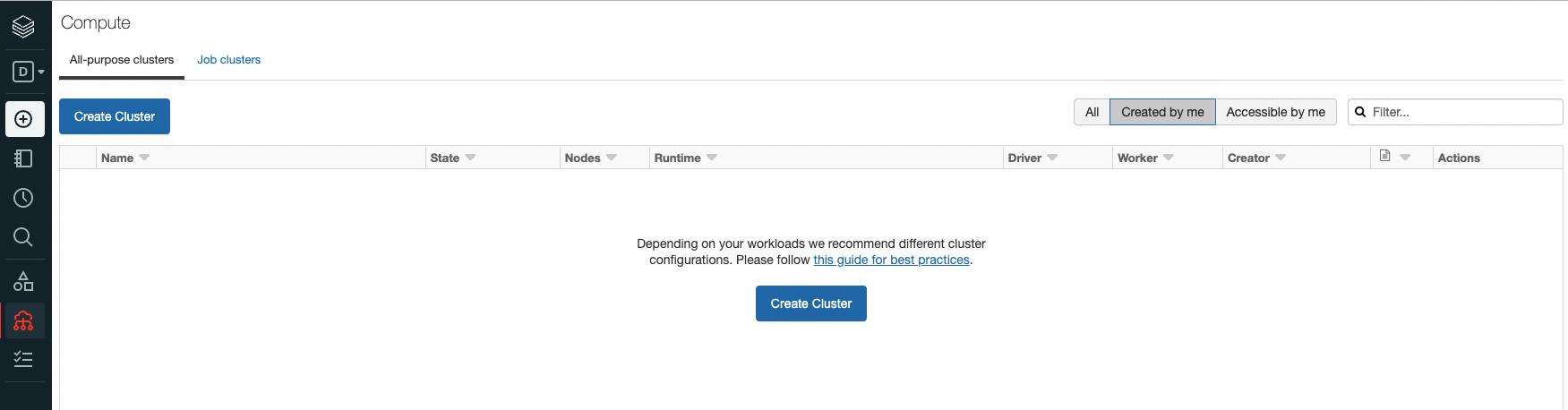
3.
Because a community edition is limited in terms of the amount of compute power you can use, create cluster page is fairly simple and just asks for a cluster name. You can stick with the default Databricks runtime version. But you can see that you will get 1 driver with ~16GB of memory and 2 cores. This is what they call a single node cluster.
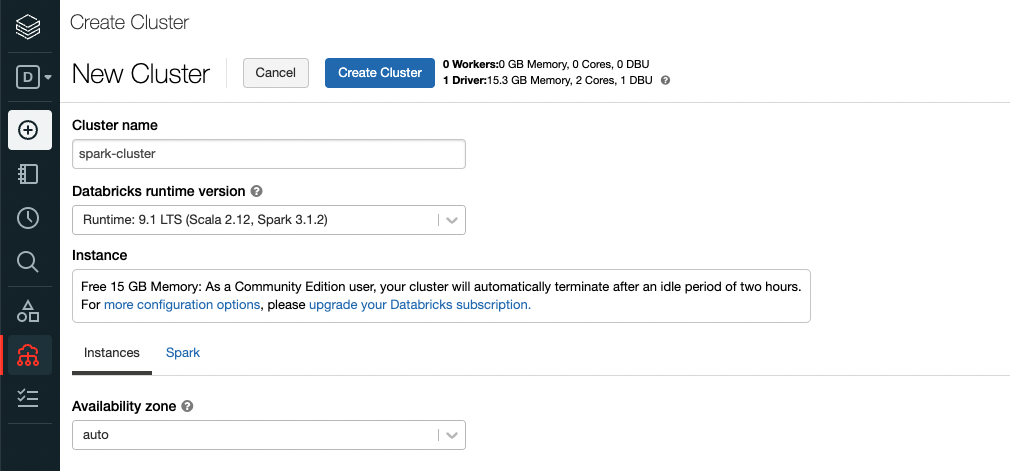
4.
To confirm all is good, create a new notebook from the link in the home page (reachable by clicking Databricks icon in the side bar) or from the plus button in the sidebar.

5.
Fill a name for the notebook and select the cluster just created. Python will be used throughout this tutorial but Scala, SQL and R are also available. You will also see how to use different languages in the same notebook.
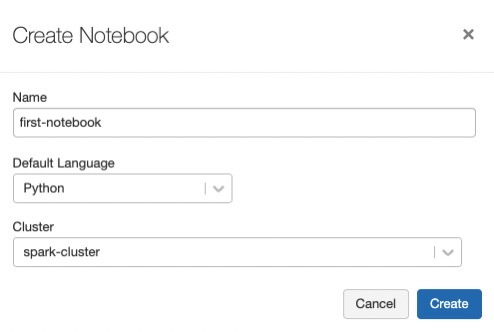
6.
In the first cell we can check the current Spark version because it is very useful to know what version of Spark is being used.

7.
This is a hello world post so let’s write a hello world statement. Notebooks on Databricks can run classic Python/Scala/R code so we can still use all the common constructs in our preferred language. For example, it’s totally fine to use list comprehensions or dictionaries in a Python notebook.
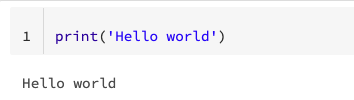
8.
Let’s try something simple like counting elements of a list in Python.

Well, that’s pretty basic but the key takeaway here is that for classic programming, you are limited by the compute power of a single machine. What would be the case if the list has a trillion elements. You may hit an out of memory exception because the list cannot fit in the memory of your machine or in best case cannot be processed in an acceptable time.
9.
That is where Spark shines as it uses a distributed processing model to handle such types of tasks. Let’s pull the text of The Adventures of Sherlock Holmes by Arthur Conan Doyle and try to find how many words are there. The below snippet shows how to load the textual content of the series from a web server, split it into words and print the first 40 words as a quick sanity check.

10.
Instead of calling a len function on the list directly, we will create something called an RDD (resilient distributed dataset) on top of the list to allow any processing to happen in parallel across multiple nodes in the cluster (or multiple cores if the cluster is a single machine). sc is an entry point to Spark that allows us to create an RDD from a list. There are many ways to create an RDD or Dataframe out of in-memory data or more commonly data stored on disk (Think S3 or Azure Data Lake Storage Gen2). RDD class has many functions to process the data and one of them is to count how many elements the RDD has.
11.
The word count of that novel is 110,675 as shown above. You can see that the output of the cell includes a Spark job which shows a stage with 8 tasks This is evidence that the count task has been divided into chunks which are handled by multiple cores on the same machine or more generally multiple machines if we have a multi-node cluster. If you are curious to know if the count value does make sense, here is the result from a Google search.

12.
The text preprocessing logic we used is very basic but the overall word count is near to the expected word count which means our Spark simple program is doing well.
