
Partnered with a large Australian Health Insurance provider seeking to deliver a cloud-native adoption program to achieve both the financial efficiency and security benefits associated with decommissioning infrastructure gain innovation benefits of using cloud-native services
The problem
The customer faced an increased rate of attrition amongst the most profitable age bracket due to cost concerns, and as such was driven to embrace innovation strategically for both retention and growth. Focus shifted from being a ‘payer of claims’ to a Payer to Partner (P2P) strategy that seeks to transform their role in the health care of customers delivering holistic health engagement, enhancing digital interaction, and elevating health outcomes.
Overview
The solution addressed the challenge of inefficient document processing across the customer’s business units. Initially, each unit relied on manual data extraction from submitted documents, or utilized individual, unit-specific automated tools. The customer had previously developed an Intelligent Document Processor (IDP) using AWS Textract for automated field extraction, but it was limited to the single business unit and faced accuracy issues.
To improve efficiency and accuracy, an enhanced “Vision IDP” was developed. This solution leverages multi-modal Large Language Models (LLMs) to provide superior field extraction. The Vision IDP is designed to be a generalized, centralized OCR service, capable of being extended to various business units across the customer. . It operates by inputting both raw OCR text and the original document image into a multi-modal model such as Claude 3 or GPT4. The IDP service is intended for widespread use throughout the customers business units.
Business requirements
- Straight through processing (STP) rate of 30%. For a document to meet STP requires any data extracted from it to pass all business rule checks applied. This business checks include data integrity checks (such as ensuring that sub totals add up to totals) as well as entity matching (ensuring customer number and name match to a database). It also requires a minimum set of fields to be present and successfully extracted. STP is therefore correlated to, but not entirely influenced by, the accuracy of the document extraction solution.
- All PII data remains in region (Australia). Customer invoices contain sensitive PII data that cannot leave Australia. This means that the models available for use were limited. Claude 3 was used over Claude 3.5 Sonnet for this reason.
- Throughput requirements. In production expects 280,000 invoices a month. On average we expect 30-50 invoices per minute, with a peak rate of around 100-600 invoices per minute. Load balancing…Currently, Claude 3 on-demand quotas are enough to meet these requirements.
- Integration into existing systems.
- Centralised service. The document extraction service needs to be stood up as a centralised service, accessible by multiple business units. This is because we expect the document extraction model to potentially be utilised across several use cases. The service therefore needs to be set up in a way that easily allows for the extraction of different document schemas and fields.
- Ability to hot swap LLMs. We expect LLMs development will continue into the future. The solution should not be specific to any single model, and must be able to be easily changed in the future. The barrier to testing new models should be low.
- Monitoring and transparency. Model performance needs to be logged and monitored. Any failure modes need to be able to be tracked and understood
The Dual-Input Solution
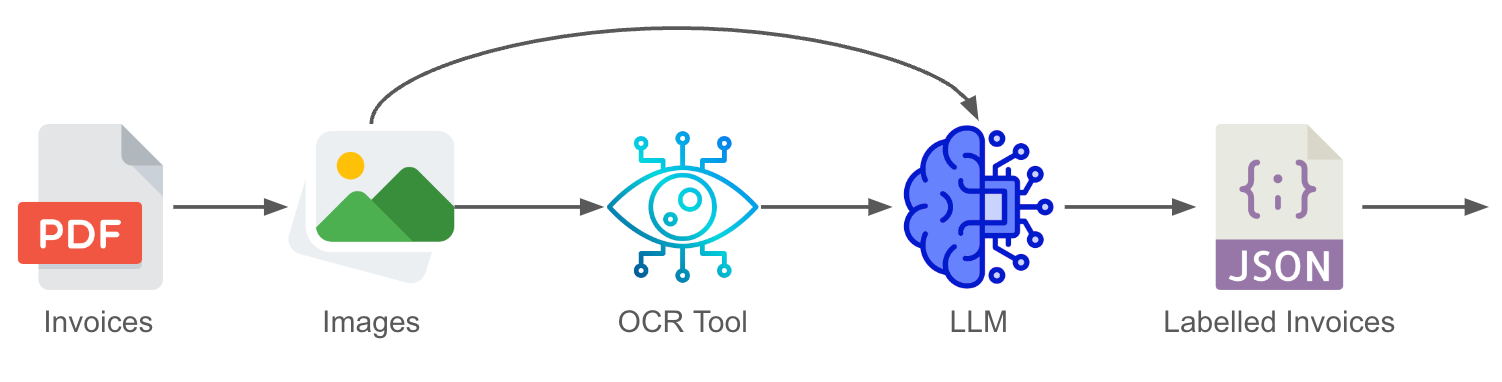
The processing pipeline used for the LLM document knowledge extraction solution.
Our document knowledge extraction solution leverages a combination of LLMs and Optical Character Recognition (OCR) technology to automate the process of structuring unstructured data from documents such as invoices. The process begins with the input of three simple components:
- A schema that defines the ideal output structure
- Field definitions that specify what data to extract
- The document itself
Preprocessing techniques are employed on documents to ensure images of pages extracted from the document are of the best possible quality. This transformation often includes sharpening images for enhanced text readability and/or rotating documents to ensure upright text orientation. These efforts ensure that the image is best placed for accurate text extraction.
Once preprocessing is complete, the resulting image(s) are passed to an OCR engine to extract the raw text contained in the document. OCR engines such as Tesseract receive images as input and return detected text within the image as an output. Both the text and the original document image are then fed into the LLM. This dual-input strategy is key: when passing only the image, the LLM can usually identify the fields in the correct locations but tends to misread characters. Conversely, when passing only the OCR text, while character accuracy improves, the LLM sometimes struggles with identifying field values due to a lack of spatial awareness (e.g., missing context from tabular structures or logos).
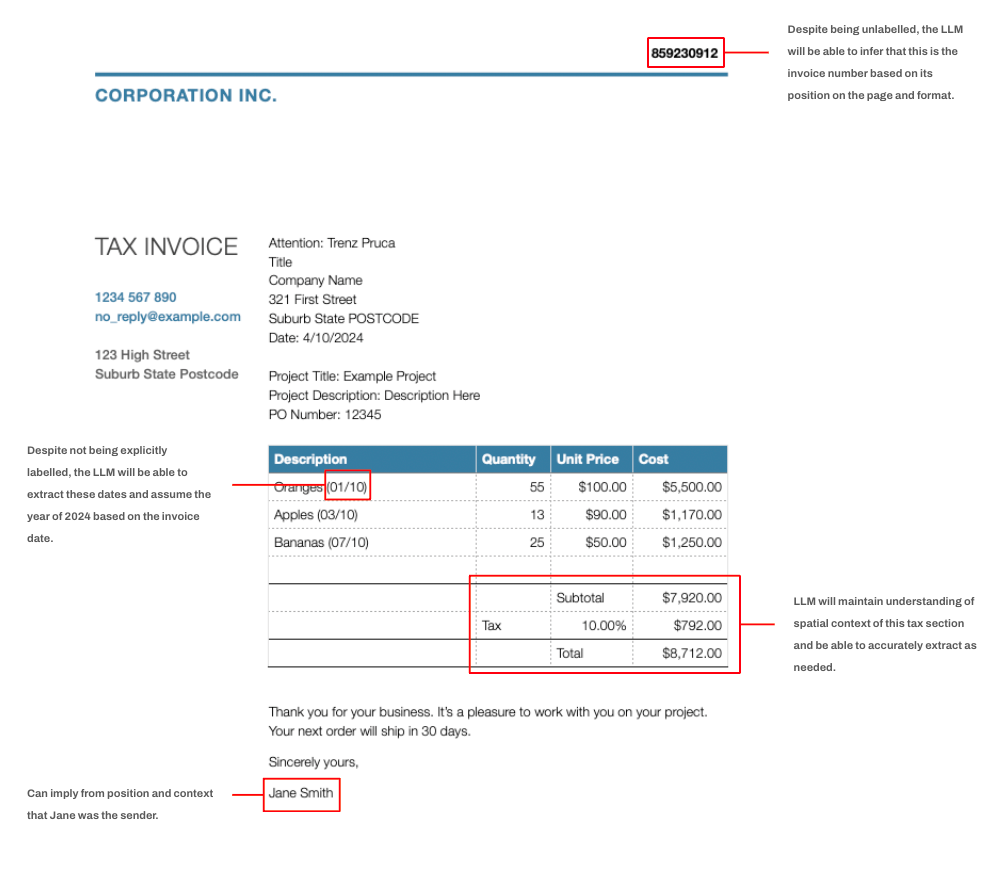
Examples of edge cases that might be difficult for a traditional document knowledge extraction solution to process correctly.
By providing both the image and the text, we achieve the best of both worlds—the LLM uses the image to accurately match fields and the OCR text to reliably extract characters.
This approach delivers several key benefits over traditional document knowledge extraction services:
- Superior accuracy: LLMs offer better accuracy by leveraging contextual clues within documents to identify fields that may not be explicitly labelled. They also excel at recognizing patterns based on field definitions and handling edge cases that rigid heuristic based systems often struggle with.
- Cost-effectiveness: Depending on the use case and the model employed, LLM-based solutions can be more cost-efficient than other alternatives due to the ever decreasing token.
- Generalisability: LLMs’ adaptability to new document types or business use cases is unparalleled. The processing logic is often predominantly contained within the natural language prompt, making it easy to update and maintain.
- Direct output into the required format: The LLM can be instructed to produce results directly in the desired schema, eliminating the need for complex post-processing to transform raw outputs into a usable format.
This solution has proven not only to be effective within a single business unit but also highly portable across different use cases and clients across a wide range of industries. The key modifications required are simple – adjusting the output structure and field definitions – which underscores the adaptability of the LLM to new challenges.
Moreover, we’ve observed that the model exhibits a surprising ability to make ‘human-like’ decisions in ambiguous scenarios. When faced with poorly defined fields or unusually formatted documents, the model often makes rational choices that a human might arrive at when interpreting the same document. This capability further highlights the flexibility and intelligence of the solution, this ability to reason with some post-processing for validation makes it a powerful tool for automating complex document processing tasks.
While we have primarily focused on LLMs capability to extract knowledge from documents within an operational automation use case, transforming this unstructured data into formats more accessible to business intelligence and other machine learning development creates enormous business potential. For example, uncovering new patterns, trends and relationships that were previously unknown.
AWS services used
- Bedrock
- AWS Textract
Outcomes of Project & Success Metrics
We have productionised this solution for a client and observed significant improvements in accuracy compared to their OCR only based solution. Field accuracy increased from 80% to 98%, largely due to the LLM’s ability to handle more complex edge cases. In practical terms, this resulted in an increase in the proportion of documents processed fully automatically, reducing burden on human officers reviewing documents manually. Additionally, the solution eliminated a substantial portion of hard-coded business logic, reducing the maintenance effort and allowing the system to process document structures that were previously unsupported by the legacy system.
Lessons Learned
- Prompt Engineering Crafting an effective prompt is akin to writing clearly and unambiguously for another human. Throughout testing, we identified situations where our field definitions were not as robust as anticipated. Refining these definitions to provide the most accurate and useful context for the LLM is crucial for optimising the last few percentage points of accuracy. This process includes providing illustrative examples, clarifying edge cases, and alerting the LLM to avoid mistakes we’ve observed previously.
Scalability
- One of the key challenges in scaling LLM-based document extraction solutions, especially in enterprise environments, is managing API rate limits imposed by LLM providers. For large-scale operations, careful design is needed to ensure that the system can meet the latency requirements, which may fluctuate depending on internal demand and external factors such as cloud provider load.
- Hosted LLMs, like AWS Bedrock, impose rate limits on both API calls and token processing, which creates a mismatch between the ingestion rate and the model’s throughput capabilities. To address this, solutions like API gateways, load balancers, and queuing mechanisms can be implemented to manage input rates and ensure seamless processing.
- Additionally, design considerations around LLM usage are crucial. Decisions such as choosing between provisioned throughput or on-demand access, selecting the appropriate cloud provider, and determining the region where services are hosted can all impact performance. If multiple production solutions are utilising an API hosted on the same cloud account, it’s important to establish how resources will be allocated to avoid bottlenecks. For example, you could choose to deploy a solution with lower expected consumption into non-primary regions to maintain your API quota bandwidth in the regions with the highest capacity such as US-West.
