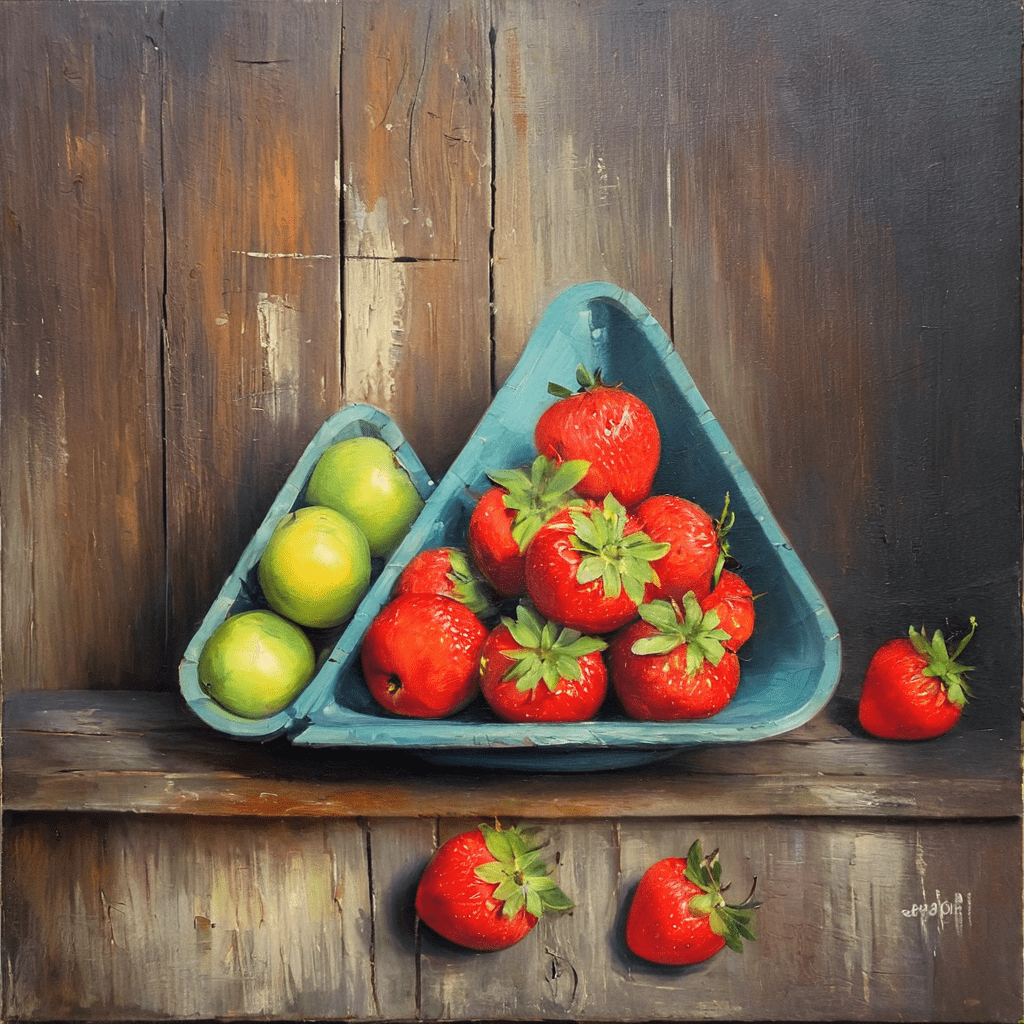Written by Harish Suresh
Who says GenAI can’t be fun for everyone?
As we gathered at AWS Summit Sydney 2024, it was clear that we were part of a pivotal point in tech history, where Generative AI was unlocking new paradigms that were previously impossible. This year, the event was themed around the transformative potential of Generative AI, spotlighting the remarkable capabilities of Large Language Models (LLMs) and Diffusion models. These tools are not just enhancing existing processes but are paving the way for solutions to problems that seemed beyond our reach just a few years ago.
A great example of this was Leonardo.AI, who took to the stage in the Keynote and showcased how they used Diffusion models to rapidly iterate through assets for designers and creatives, shortening the process from days to hours.. Amidst this backdrop, numerous technology and service partners, including ourselves, were present, each eager to demonstrate how they are integrating these models into their offerings. It was a massive learning experience for us, to see the breadth of innovation and to share a space with so many forward-thinking professionals.



At the AWS Summit, Mantel Group had a booth near the Generative AI corner and wanted to bring something distinctively engaging to the table. We showcased a demo that took a very different approach to GenAI, moving away from the more common LLM, VectorDB, and Retrieval-Augmented Generation (RAG) model presentations. We aimed to show the audience that LLMs weren’t the only GenAI models worth exploring. We utilised Diffusion Models paired with ControlNets to allow attendees to create artistic masterpieces from their imagination. This interactive experience was designed not just to showcase the technology but to engage users in the creative process, making Gen AI more approachable and understandable.
The response was overwhelmingly positive, as numerous participants were amazed to see their creative ideas turned into stunning pieces of art. This experience was a reminder of the joy and wonder that technology can inspire when applied creatively. Many were thrilled to see their ideas come to life, almost instantly, reflecting on the unique blend of their creativity with the power of AI. This process not only demonstrated the capabilities of the technology but also served as a vivid illustration of how AI can be a partner in the creative process, rather than just a tool. The ability to instantly visualise changes and experiment with different creative directions offered a hands-on experience that was both educational and inspiring. This interactive element helped demystify AI for many, making it more tangible and accessible. You don’t need to be a Data Scientist to appreciate it; a vivid imagination is enough. Who says GenAI can’t be fun for everyone.
Our presence at the summit provided a valuable opportunity to engage in deeper conversations about the broader spectrum of Generative AI beyond wrappers around LLMs. We discussed with attendees the exciting possibilities across different AI modalities, such as audio synthesis, video generation, and code generation that could revolutionise industries from entertainment to healthcare. These discussions were eye-opening for many, highlighting the vast potential of AI to transcend traditional boundaries and foster innovation across diverse fields. It was inspiring to see the realisation dawn on many faces that Generative AI is not just about text or static images—It’s a rapidly expanding area, rich in possibilities for cross-disciplinary creativity.
Under the hood of the GenAI demo at the Mantel Group booth
Creating our demo was a journey of both challenges and learning. At its core, the demo ran on an AWS G5.XL EC2 instance, which was crucial for handling the demands of the Stable Diffusion XL model checkpoint — a cornerstone of our setup. We used ComfyUI to ensure that the user interface was intuitive and user-friendly, allowing participants to easily interact with the model without feeling overwhelmed by its complexity. Next,we used a Depth ControlNet model to add a layer of sophistication to the images, enhancing their realism and detail. We experimented with other models like Canny, Sketch, etc. but the Depth model gave us a fine balance of consistent image generation and creative randomness (scroll down to see how someone generated a plate of grilled salmon with their prompt).
Our goal was to optimise the image generation process to under 10 seconds per image at a resolution of 1024 x 1024, making the magic of AI tangible and immediate for summit attendees and the G5.XL EC2 instance with NVIDIA A10G gave us a great balance of cost and performance, letting us experiment freely on our sandpits during the pre-summit preparation phase. Using the Deep Learning AMI significantly reduced the setup time for the demo, and most of the components worked out of the box.


Our workflow asked attendees to enter 4 inputs:
- An art style for their image: Ranging from simple oil paintings and watercolours to complex styles like art deco and double exposure photography.
- The main subject: We provided a reference image that looked like a generic building with a mountain in the background, but the attendees were free to interpret it anyway they wanted. Some folks saw a hospital by the beach, others saw a princess on the throne, and someone even said it looked like a place of salmon!
- Any fine details: Attendees could choose the time of day, specific colour tones, or details about objects in the image. Nothing was off limits.
- Contact Details: We did offer a prize for the best image generated each day, so having an identifier about the artist made it easy for us to contact them to dispatch their prize.
The diffusion model starts with a random noise seed, and transforms the image in “steps”. Each time it uses the prompt to guide the pixels until it generates the final image that matches the prompt. Here we can see how 2 different starting points have resulted in slightly different variants of the same image. By Step 4, we can see how the model intends to complete the image, and by Step 7 we are just missing some of the fine details. By Step 10 or 11, we have enough information for a consistent image that matches the prompt.
If you’ve used Stable Diffusion XL (SDXL) models yourself, you’ll know that these are a small handful of settings that you use in your workflow, but for the purposes of the demo, we pre-selected values for the scheduler, CFG (classifier-free guidance scale), negative prompt, etc. using sensible defaults that worked well for the wide range of tests that we performed before the event. This was especially important knowing that the SDXL model has been trained on images from the internet and is more than capable of generating images that may not be appropriate for all audiences.
 These prompts are applied to our reference image which acts as a depth map for the ControlNet model to influence the structure of the generated image. If you’re wondering why there’s a big apple on top of the building, that’s because we wanted to give the model enough randomness to generate something truly unique and artistic.
These prompts are applied to our reference image which acts as a depth map for the ControlNet model to influence the structure of the generated image. If you’re wondering why there’s a big apple on top of the building, that’s because we wanted to give the model enough randomness to generate something truly unique and artistic.

Here’s a sample of the images generated at our booth.


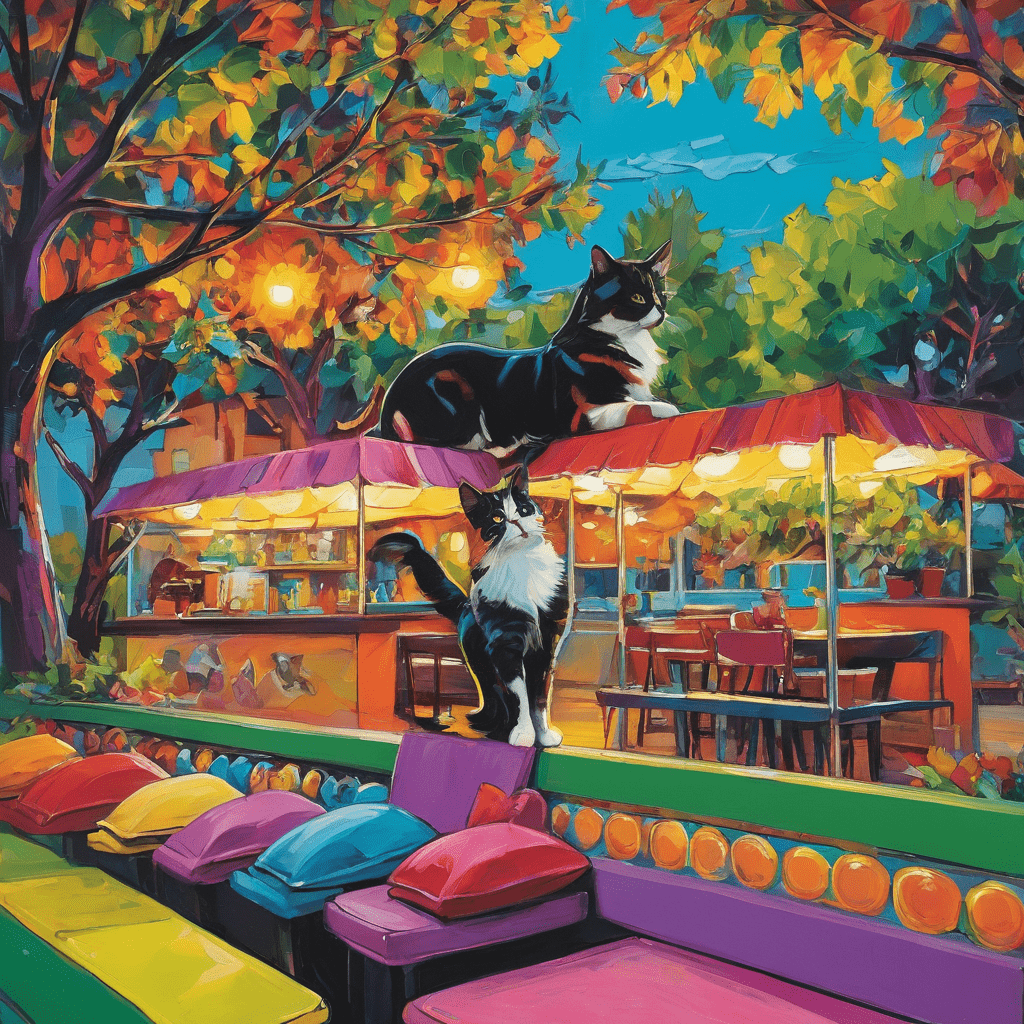





Embracing New Horizons with AWS Bedrock
The launch of AWS Bedrock in the Sydney region on the day of the summit was a pivotal moment for us and the cloud computing community at large. Looking ahead, we are excited about the possibilities this new platform opens up for us, particularly in terms of adopting a serverless approach to our image generation demo. Unfortunately, the current version of Bedrock doesn’t support the use of external networks like the Depth ControlNets used in this workflow, so we have to rely on deploying it via an EC2 instance instead. The industry is rapidly growing and evolving to support the latest capabilities of these models and we’re optimistic that future iterations of AWS Bedrock may support ControlNets.
AWS Bedrock represents not just a technical upgrade but a strategic move towards scalable, and cost-effective computing solutions. Prior to its release, users had to right size the GPU backed EC2 instance for ideal cost / performance balance, then install the necessary tools to interact with the model and finally write custom logic to serve results. Bedrock simplifies this process by removing the undifferentiated heavy lifting involved in model deployment, and offers a simple API with IAM integrations that can easily work with other applications in your environment. We expect services like Bedrock to further democratise access to powerful AI tools, making them more available to a broader audience.
The event was a great chance to catch up with our technology partners, clients, prospects and even potential hires, as we all navigate the uncharted waters of this rapidly evolving space. With each week, we see models getting leaner and more performant, and each day the barrier to entry is getting smaller and smaller. At this rate, we expect some of these tools to become as ubiquitous as Microsoft Excel, and we can’t wait to see how it unlocks new paradigms for developers, users and the tech community.
To wrap things up, here’s an example of how we applied the same model to the Mantel Group logo to generate some interesting graphics. As a disclaimer, these are purely used in the context of a tech demo, and are not part of our official brand identity, but I’m sure you’ll start seeing more AI inspired dynamic identities as the technology keeps getting better! Considering the fact that someone like me with almost no creative skills was able to generate these in seconds, I can only imagine what wonders await us when these tools are widely adopted by everyone!