Written By: Illia Kavaliou (Principal Consultant) Mantel Group
One of the most debated topics in the AWS cloud community is how to choose the right compute service for applications deployment. While there are numerous articles on the Internet that offer side-by-side comparisons based on service characteristics, many of them lack concrete examples and evidence to support and prove theoretical claims.
Therefore, we opted to conduct a practical experiment to compare AWS Lambda, ECS and EC2 services. Our focus was on a straightforward yet extensively used API deployment to collect empirical, observable, and measurable data.
Our experiment results revealed that AWS Lambda outperforms other deployment methods showcasing better scalability and reliability, ease of maintenance, and operational cost-effectiveness, all while delivering comparable performance.
While acknowledging that the “Serverless First” approach may not be universally applicable to all organisations and business challenges, it is reasonable to consider the use of AWS Lambda as a foundational element when designing and implementing new cloud-based systems or features.
In the following sections, we will explore our approach with related challenges and discuss the results.
Our approach to compare Lambda, ECS and EC2 services
We aimed to abstract the code logic in this comparison to ensure a fair “apples to apples” evaluation, and therefore we decided to deploy the same workload to three AWS services with comparable specifications.
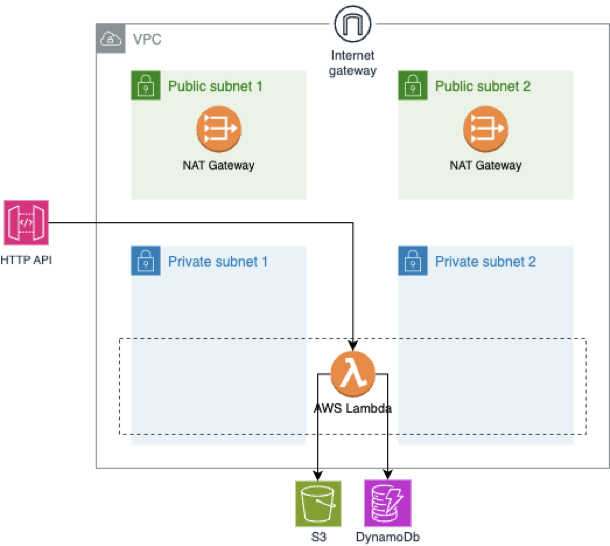
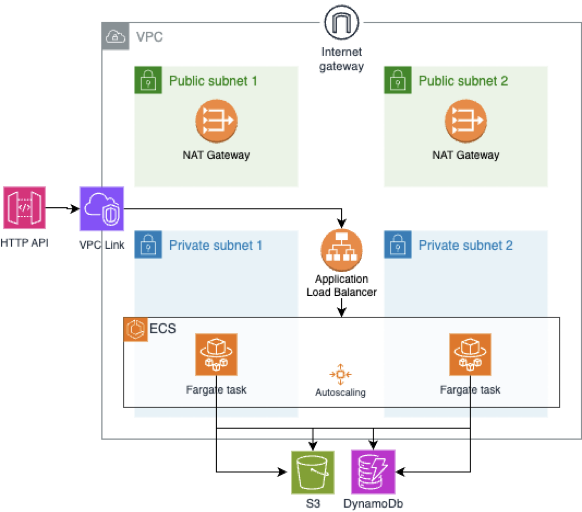
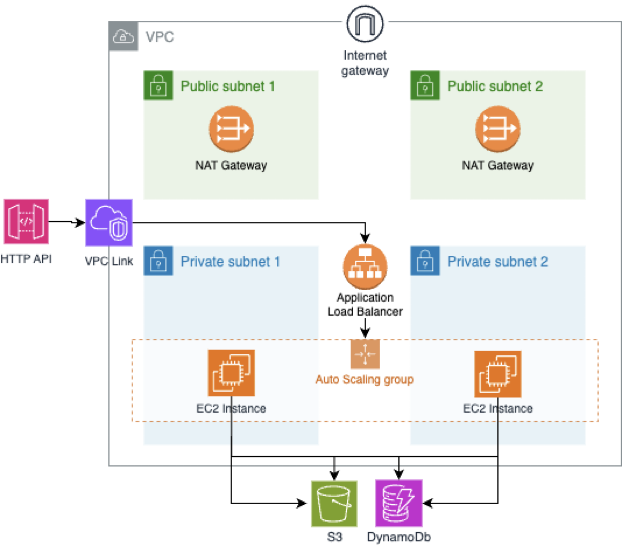
We developed a Python FastAPI endpoint containing straightforward logic that interacts with an S3 bucket and DynamoDB table, returning a status code of 200. This endpoint was deployed in three distinct ways: as a zipped code to Lambda (“Lambda scenario”), as a Docker container to ECS Fargate (“ECS scenario”), and as a set of files copied to an EC2 instance with an initialisation script to initiate the server (“EC2 scenario”). All three deployment approaches adhere to commonly used patterns and serve to illustrate how the same code can be executed in different environments leveraging API Gateway and private VPC subnets.
The following configuration for ECS and EC2 scenarios:
- ECS Fargate tasks with a configuration of 1 vCPU and 2 GB of memory.
- EC2 M5g.medium instance with specifications of 1 vCPU and 4 GiB.
- Lambda with 512MB memory allocation.
This configuration was selected after thorough testing to ensure comparable performance and throughput.
A simplified version of the Lambda scenario architecture diagram is presented below:
The ECS scenario utilising two Availability Zones (AZs) and Application Load Balancer (ALB):
The EC2 scenario:
AWS CDK was used to deploy a minimal infrastructure, creating distinct stacks for each scenario, each with an HTTP API endpoint. Separately, a shared infrastructure stack was used to create VPC, subnets, and other network-related infrastructure, recognising these components typically spanning the entire organisation.
Another EC2 instance was deployed hosting a k6 script designed to execute a load testing suite against all three APIs simultaneously. Ramping arrival rate executors were utilised to simulate API traffic over a 6-hour span, incorporating sudden traffic spikes and drops. The following graph shows the load shape pattern used generating approximately 4.8 million requests, with an average exceeding 220 transactions per second.
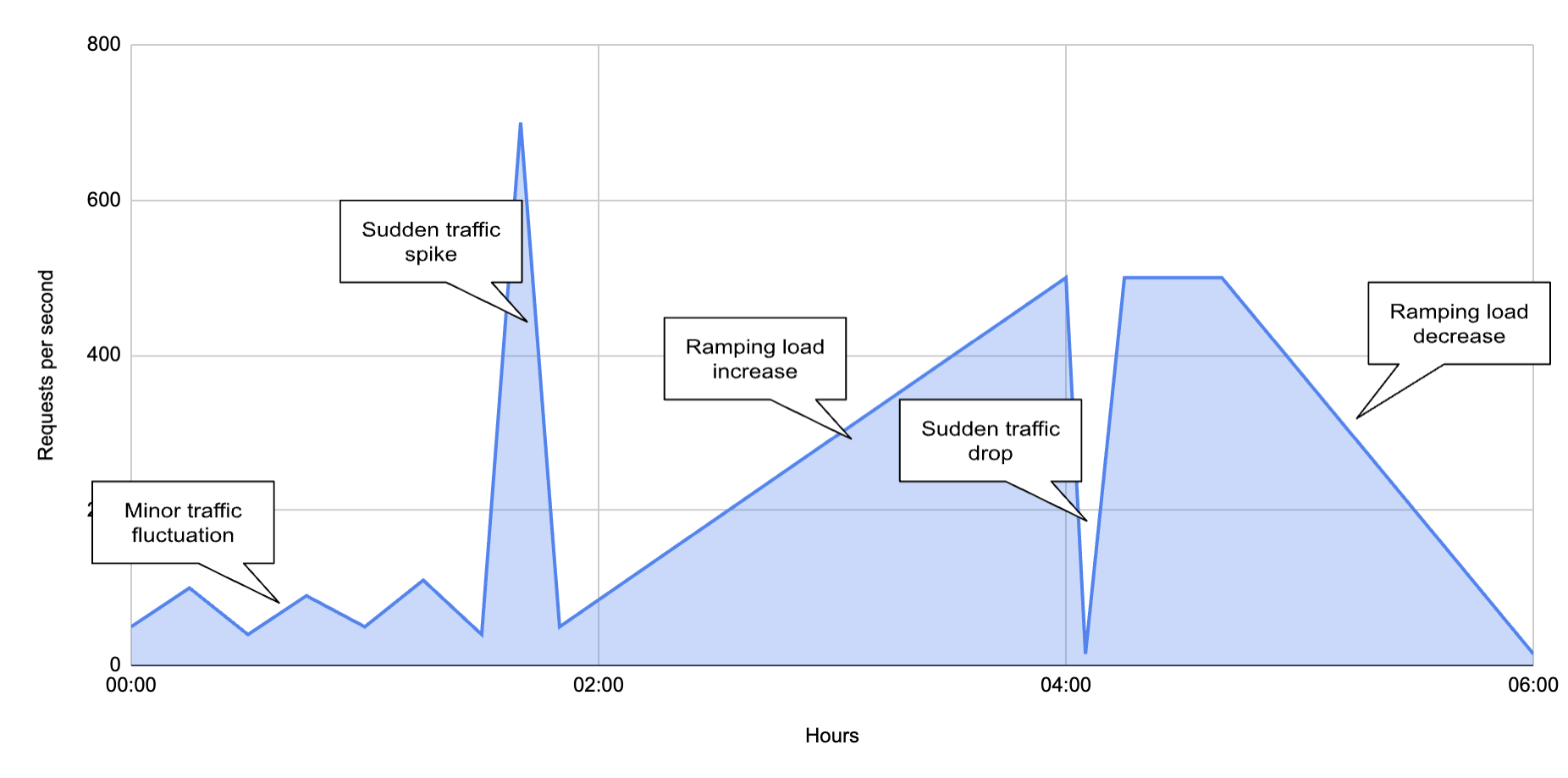
With a load approaching 700 transactions per second during spikes, our testing reaches a significantly high level, surpassing the peak transaction rate reported by NAB on Boxing Day in 2021, which recorded 147 transactions per second. This load level is chosen to cover the majority of use cases and ensure a robust evaluation.
Cost allocation tags were used to track the operational costs associated with each scenario, enabling a precise comparison of each stack deployment.
Optimising ECS and EC2 scaling configuration
Initially, the default auto-scaling configurations for both ECS and EC2 were deployed using the CPU Utilisation metric as a trigger for scaling activities. The default scaling patterns employ CloudWatch alarms with three data points over the last three minutes, along with the Average CPU metric.
As a result, all three solutions managed well under moderate traffic fluctuations. However, both ECS and EC2 implementations encountered challenges in scaling effectively, leading to a significant increase in missed requests. The graph below illustrates the number of requests (Y axis) processed during the test execution time (X axis) for each scenario.
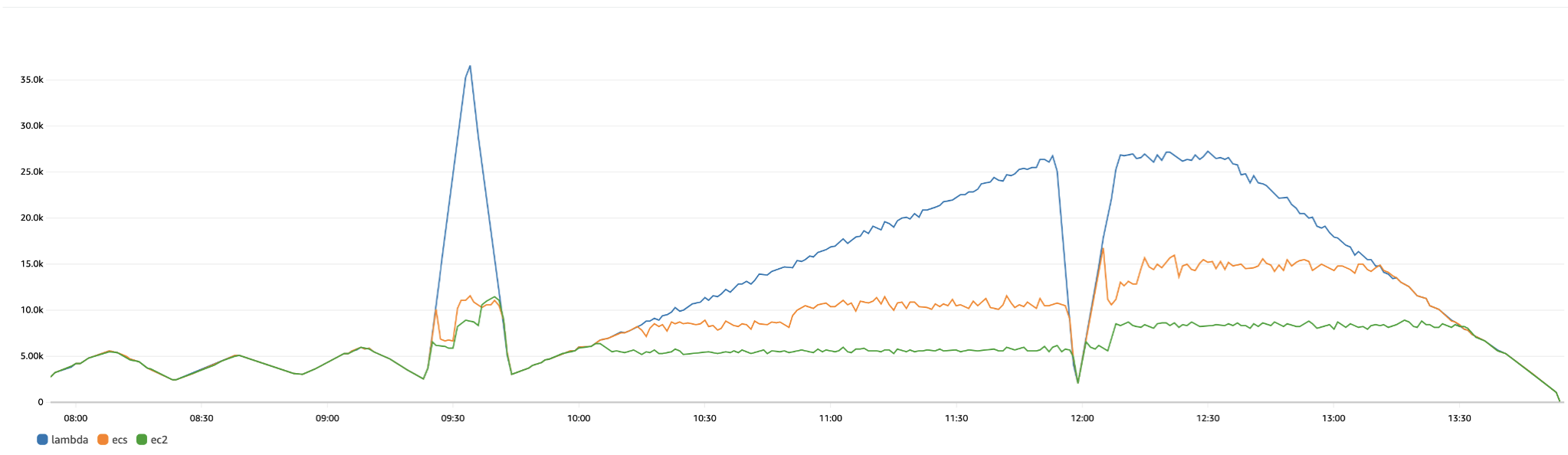
After examining the logs, it became evident that 3 minutes delay was not adequate for the traffic patterns used as shown below.
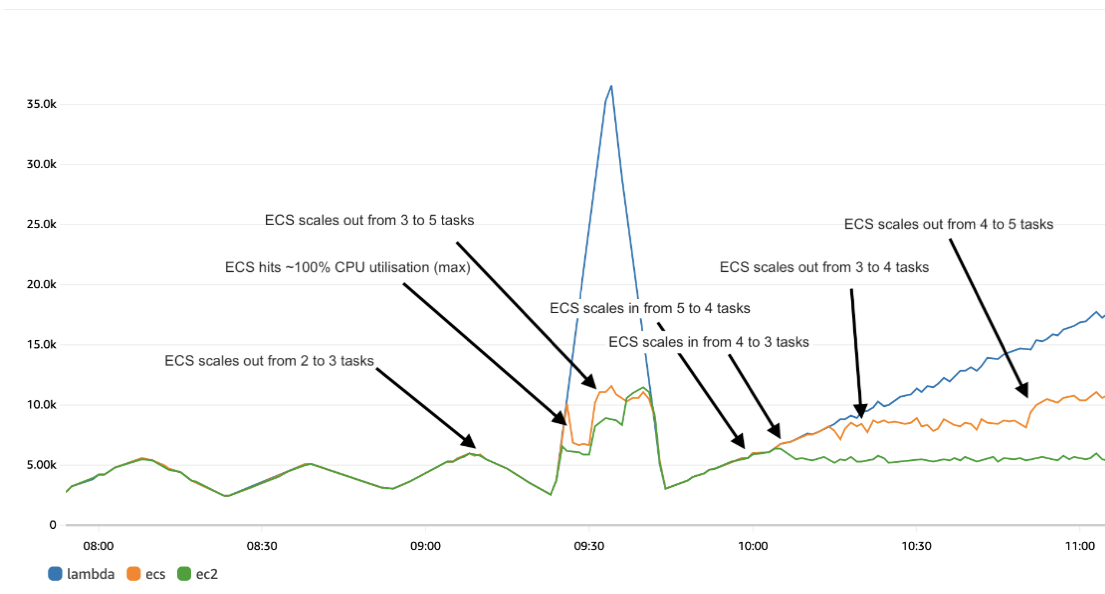
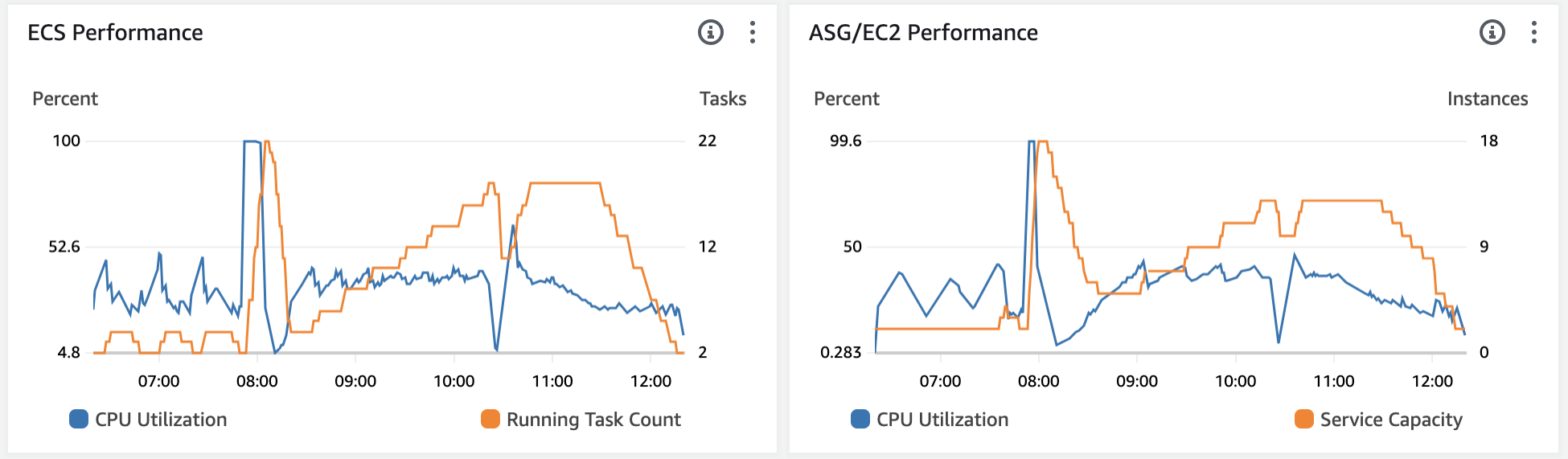
The Average CPU Utilisation metric worked well for moderate traffic fluctuations, but was not sufficient to reflect traffic spikes. The below diagram shows the average and maximum CPU utilisation to demonstrate that additional tasks launched brought down the average CPU, while at least one of the running tasks was still sitting at a 100%.
In addition, while the Average CPU Utilisation metric effectively handled moderate traffic fluctuations, it proved inadequate to capture sudden traffic spikes. The diagram below illustrates both average and maximum CPU utilisation, highlighting that the launch of additional tasks brought down the average CPU, while at least one of the running tasks maintained a constant 100% utilisation.
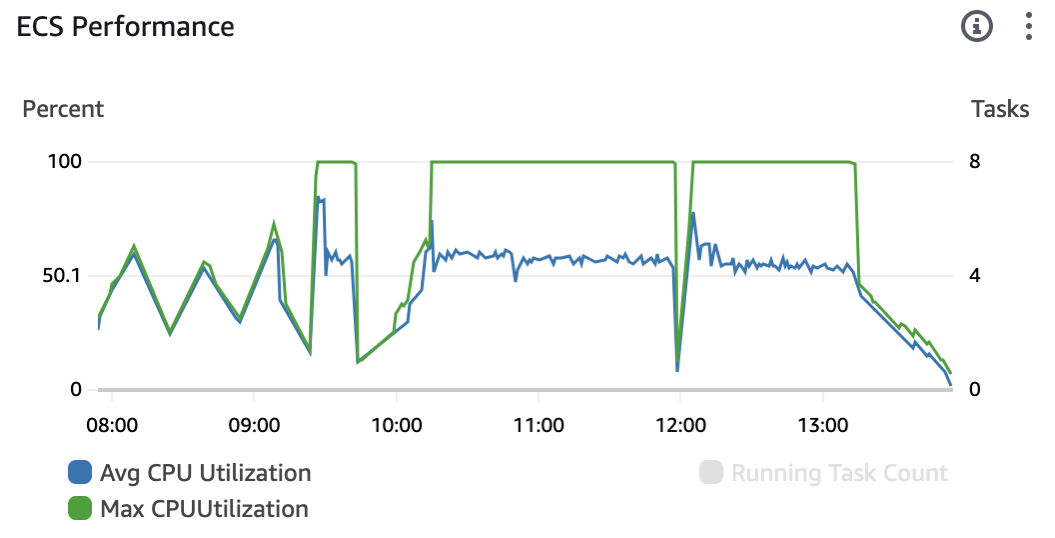
Hence, custom metrics were introduced based on MAX CPU Utilisation, coupled with an aggressive scaling steps policy (adding 5 additional tasks or instances once the metric reaches 80%). A 1-minute cooldown period was implemented between scaling-out activities.
It is crucial to note that the effort invested in producing IaC scripts and fine-tuning scaling policies was substantial, resulting in a larger codebase and anticipated higher ongoing maintenance costs.
Scalability and reliability
With the updated configuration, ECS and EC2 solutions demonstrated scaling performance similar to Lambda scenario. However, they still fell behind during sudden traffic spikes, as shown in the graph below.
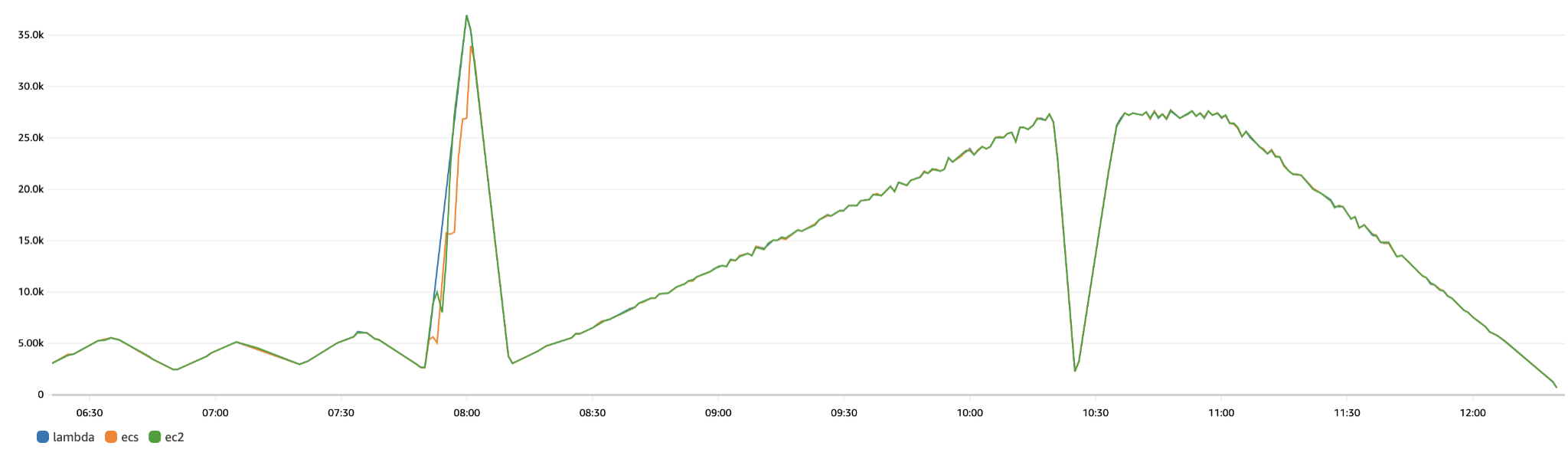
This behaviour is anticipated and highlights a significant limitation of ECS and EC2 autoscaling policies – they are reactive and occur after a CloudWatch alarm is triggered following custom metrics delivery, typically accompanied by a 1-3 minute delay.
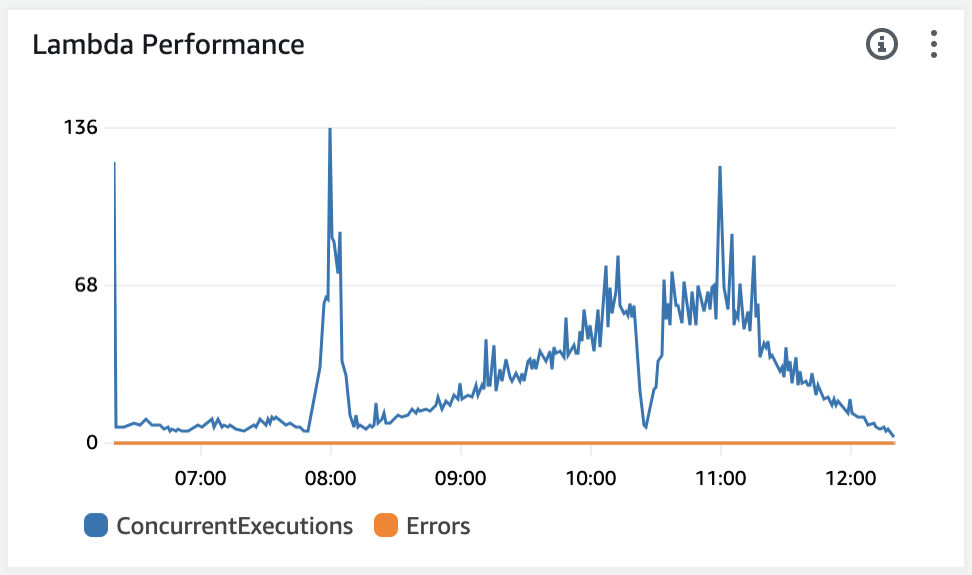
The nature of AWS Lambda mitigates this limitation by seamlessly increasing the number of concurrent executions. Concurrent execution and burst concurrency are soft limits and can be increased if needed. In our test, AWS Lambda was capable of handling almost 37,000 requests per minute, with concurrent executions peaking at 136 (Y axis on the chart below), which is well below the default quotas.
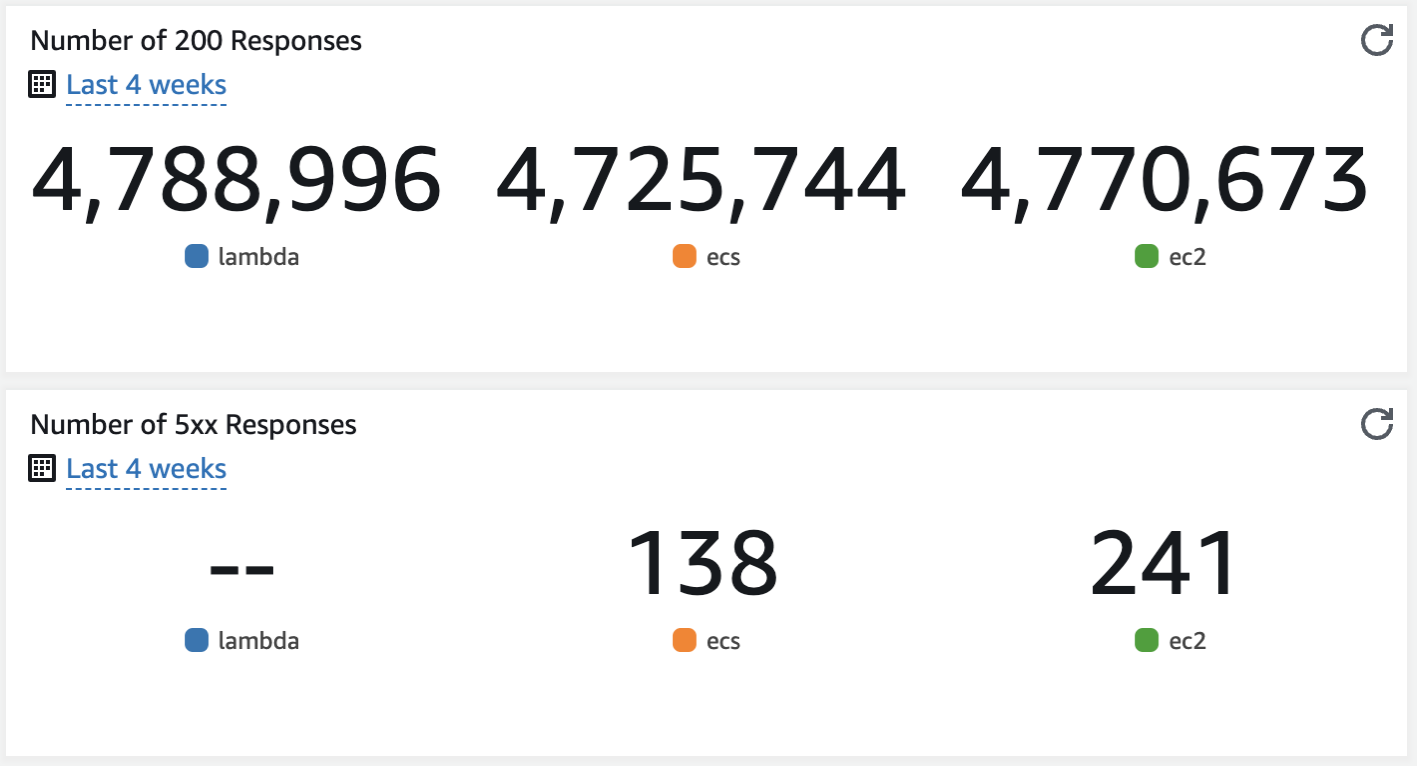
Over the duration of our test, AWS Lambda managed to process more requests than ECS/EC2 solutions, consistently delivering no errors to the users.
Responsiveness
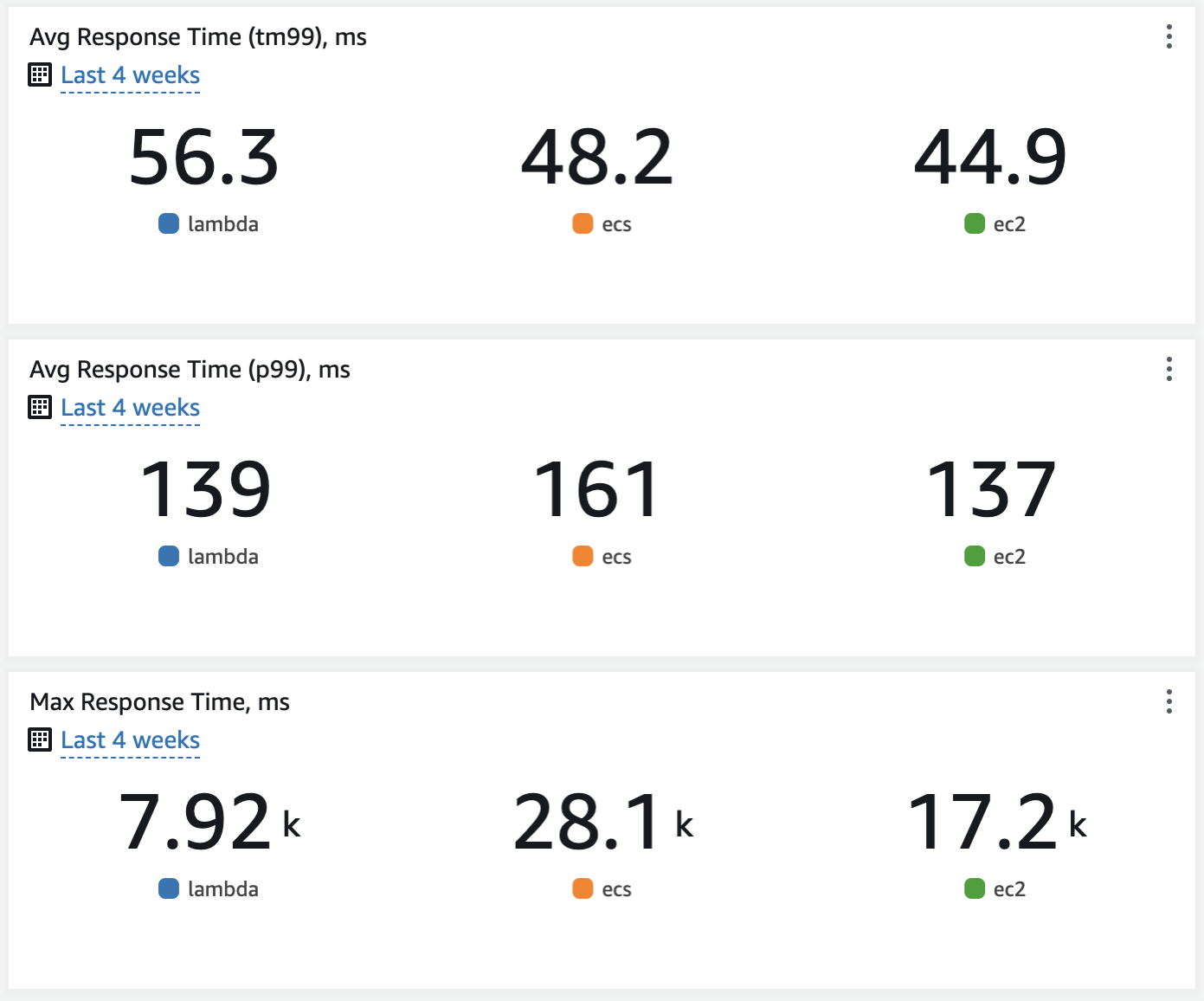
Our tests demonstrated that 99% of requests, evaluated using both the tm99 and p99 methods, were processed with a similar average response time across all three solutions. However, the maximum response time was notably higher in ECS and EC2 scenarios compared to the slowest ‘cold start’ of AWS Lambda. This finding addresses a common concern regarding cold starts, highlighting that their impact is far less significant than the challenges posed by high CPU/memory utilisation in ECS tasks or EC2 instances. In other words, the impact of AWS Lambda cold starts on performance is more predictable than that of ECS/EC2 under heavy load and should not be a significant concern in highly-utilised systems.
Is Lambda-based solution more cost-efficient than ECS or EC2 scenarios?
Our test has confirmed a widely known statement that AWS Lambda is more cost efficient under spiky loads. The total cost of the test execution was $43.76 for Lambda scenario, $46.76 for ECS scenario and $45.73 for EC2 scenario with over 90% of the total cost were attributed to the use of S3, DynamoDb and API Gateway.
It is important to note that ECS and EC2 solutions do not require API Gateway since Application Load Balancer can be placed in public subnets, allowing for cost savings. Similarly, AWS Lambdas can be placed outside of the VPC, reducing shared infrastructure costs.
Nevertheless, due to the difference in number of requests processed, a decision was made to exclude all other services not directly related to the compute, load balancing, and scaling of the services.
| Service | 6 hours, USD | Annual, USD (estimated) |
| Lambda Scenario | $1.04 | $1,518.40 |
| Lambda | $1.04 | |
| ECS Scenario | $4.62 | $6,745.20 |
| Elastic Load Balancing | $0.48 | |
| Elastic Container Service | $4.00 | |
| CloudWatch | $0.14 | |
| EC2 Scenario | $3.16 | $4,613.60 |
| Elastic Load Balancing | $0.50 | |
| EC2-Instances | $2.39 | |
| EC2-Other | $0.05 | |
| CloudWatch | $0.22 |
As illustrated in the table above, AWS Lambda incurred the lowest cost, followed by EC2 (3 times more expensive) and ECS (4.5 times more expensive).
This cost difference is predominantly due to the unutilised capacity of ECS and EC2 which is unavoidable to compensate for potential load fluctuation. In scenarios with more predictable load patterns, additional savings in EC2 scenarios could be realised by leveraging compute savings plans and fine-tuning auto-scaling policies further.
Conclusion
Our comprehensive exploration of AWS Lambda, ECS, and EC2 services for a simple API deployment has revealed valuable insights into their respective strengths and limitations. The practical experiment, comparing their performance under varying workloads, demonstrated that AWS Lambda excels in scalability, reliability, and cost-effectiveness, particularly under spiky loads. While ECS and EC2 solutions were sufficient in handling moderate traffic fluctuations, they faced challenges in scaling effectively during sudden traffic spikes, leading to a higher number of missed requests.
The limitations of reactive auto-scaling policies in ECS and EC2 were highlighted, emphasising the need for more proactive strategies to handle sudden increases in demand resulting in more development efforts in terms of IaC scripts and scaling policies.
Our tests have also affirmed AWS Lambda’s efficiency in cost management, with the lowest overall expenditure compared to ECS and EC2. The cost difference was attributed to the unutilised capacity of ECS and EC2, necessary to compensate for potential load fluctuations.
This study highlights the importance of understanding the nuances of cloud services when making deployment decisions. As cloud computing continues to evolve, these findings serve as a valuable reference for using Serverless First approach while optimising performance, cost, and scalability in AWS cloud environments.
If you are interested in understanding how serverless offerings can benefit your organisation, feel free to reach out here. The AWS Application Modernisation team at Mantel Group has an extensive track record of delivering cloud-native and serverless solutions while focusing on business objectives and addressing the specific challenges unique to your environment.
