
INDUSTRY
Gambling
SERVICES
Cloud Engineering
Data Science
Customer Background
Odds.com.au is owned and operated by Punters.com.au, which is Australia’s largest online social hub for horse racing enthusiasts and tipsters reaching over 3m people annually. Odds.com.au is a specialist sports betting website and app that enables customers to compare up-to-date prices from all the leading bookmakers and find the best value through data driven insights. Odds and Punters are part of News Corp Australia.
Customer Problem
Odds wanted to provide users with match score predictions for two sports, AFL and NRL — and they wanted to use data science to provide the predictions. This would give the users a new feature to leverage when placing bets, giving them an edge against the bookmakers. With the start of the AFL and NRL seasons six weeks away, there was only a short time window available to complete the first iteration of modelling and predictions.
Solution
At Mantel Group we have a philosophy of building our data science pipelines quickly, starting with a basic model and rapidly iterating to improve performance. We decided to use Tensorflow’s implementation of Keras as it facilitates this iterative process. Luckily the data collected for both sports was similar in features so the approach was complementary across AFL and NRL. We opted to build out the predictor as an API that could be easily integrated into the Odds website exposing the predictions to customers.

Phase 1: Exploratory Data Analysis (EDA)
We were given four datasets, two for each sport. One dataset contained details of the match like date and venue and the other contained information about the stats throughout the match like points, goals and tries both at a player level and an aggregated level for each team. The datasets were joined and explored using Python in Jupyter Notebooks. From there we output a csv with selected features from 2013 to 2018 for our first simple model, namely:
- MatchDate
- SeasonID
- NightMatch
- TeamA
- TeamB
- PointsTeamA
- PointsTeamB
Phase 2: V1 model details
Since a basic neural network provides a flexible structure to begin model development we were able to rapidly develop our first sequential model using Keras in Jupyter Notebooks. We optimised for winner accuracy (%) keeping the stats from 2018 as the hold out validation dataset logging the results of the training as we went. To do this we used one-hot encoding for each team and each venue. The Early Stopping callback in Keras was used to ensure training stopped once the model performance stopped improving on the hold out validation dataset.
Phase 3: Feature engineering
V1 relied on a very basic set of match data. The key to developing the model further was to implement extensive feature engineering. With access to a range of game actions for both sports such as kicks and disposals, and more detailed points information (goals/behinds for AFL and tries/goals for NRL), the aim was to find inputs with the highest correlation to the target outputs. Selection from the set of correlated features also posed a problem due to the issue of dimensionality. It simply wasn’t possible to provide the model with an ever increasing number of inputs due to the limited number of training samples. The problem of multicollinearity also meant considering correlations between potential inputs.
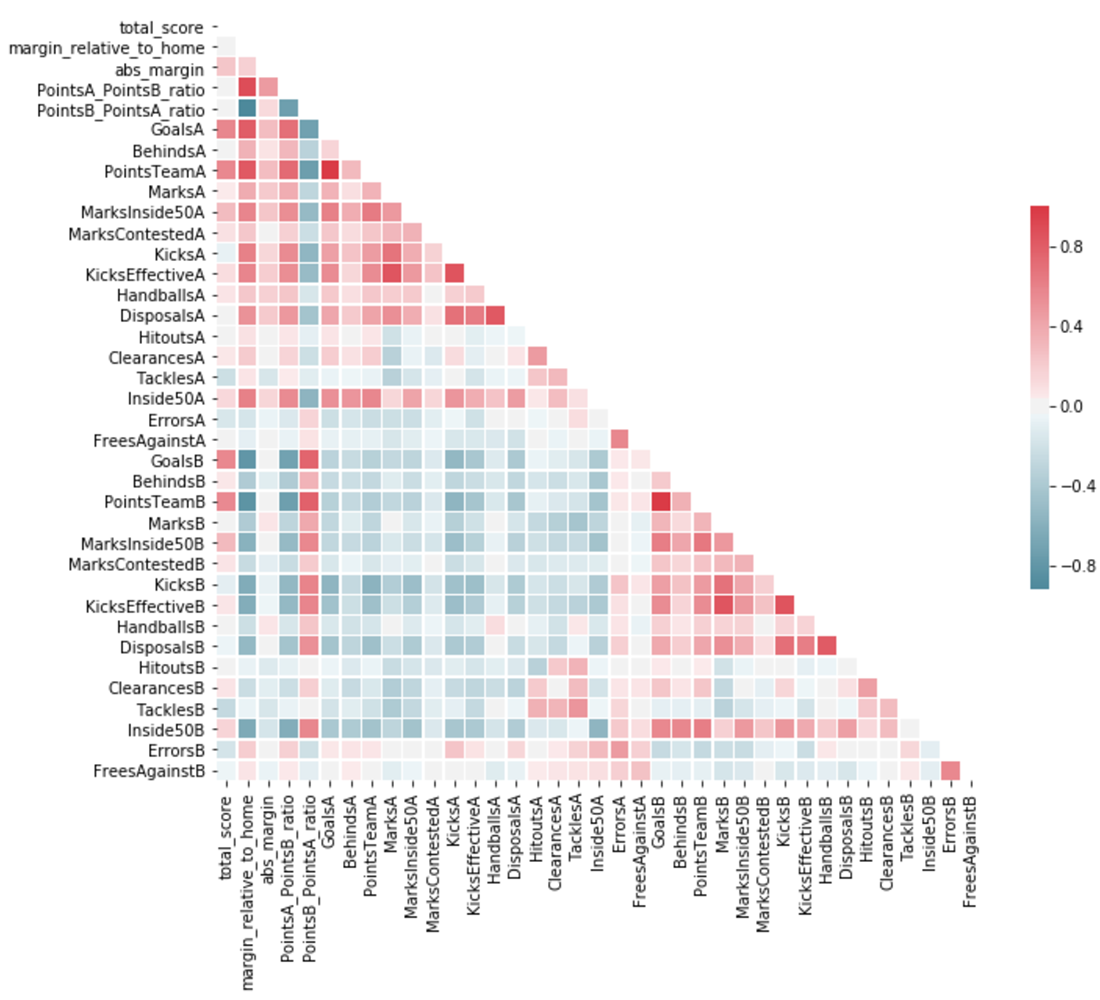
The final hurdle was the aspect of time. Though it is easy to establish relationships between inputs such as number of disposals and the final scores, these within-game type inputs aren’t known prior to a match and therefore historical results must be used as a proxy. This then gives rise to the question of how to construct such proxies. Do we use more simple techniques such as averaging? If so, what will be the optimal of looking back into the past? Timing can be important but will be dependent on the richness of the historical data. Or do we think of these inputs as being the result of their own modelling process? If so, what is the best model?
So which features should be used? With almost an endless number of possibilities but limited data in terms of the number of training samples, extensive analysis became the key. Using Jupyter notebooks to automate much of this analysis, a range of new inputs were identified comprising mainly of win/lose ratios for both the individual teams and on a head-to-head basis.
Phase 4: V2 model details
Once our features were sufficiently engineered it was time to build and compare some more sophisticated models. We leveraged Keras to compare different model structures including the prediction of single target outputs, such as ‘margin relative to home team and dual target outputs’ or ‘home score and margin relative to home team’. Automated logging of the training facilitated fast experimentation.
Productionisation
Two services were created for this project. A RESTful front-end service that used nodeJS. We used internal Odds.com.au libraries and error handling routines to fit with their existing architecture. It primarily called the other service we created which is the internal python service that performed the machine learning predictions.
The python service used TensorFlow, Keras, Pandas and Numpy. It translated from a handful of service parameters to ~60 model parameters. This included one-hot encoding, parameter scaling & minimising and domain validation. The python service encapsulated all its data in the form of an h5 model, historical CSV results and reference data (for validation and cross referencing).
The services were configured using the Serverless framework. CI/CD included tests and data validation. The architecture enabled Odds to update historical data CSVs with the latest sports results. These were then packaged and the service was redeployed.
The use of a micro-services architecture ensures the solution can scale on demand and is fault tolerant as they are relatively self contained, have a single responsibility and are short lived.
One of the challenges we were able to overcome in this project involved identifying the c++ std library that is required by TensorFlow, building for it and packaging the replacement libraries within the python service.
Outcome
Our goal was to develop and deploy a model in 6 weeks that could provide a greater return than simply betting on the favourite, and had the potential for further enhancement by the Odds data science team. Model performance would be evaluated using the 2018 hold out validation data set.
Version 1 of the model predicted the match winner with accuracy of 71.5% and 63.4% for AFL and NRL respectively. Picking the bookies favourite resulted in a winning percentage of 70.5% and 61.2% for AFL and NRL respectively.
Version 2 predicted the match winner with accuracy of 73.4% and 65.0% for AFL and NRL respectively, outperforming the V1 models by 1.9% and 1.6% respectively, achieving our goal of outperforming the bookies.

Takeaways: Data science pipeline development
The power of data science to model real life scenarios, such as team sports, begins with rapid development of a pipeline. An end-to-end data science pipeline ensures that new models can be quickly deployed and therefore facilitates an iterative development process with a faster path to productionisation. Our recommendations to achieve this strategy include:
- Develop structured notebooks to represent each step in the modelling cycle e.g.
- data exploration
- feature analysis and engineering
- training and validation set construction
- model training and analysis
- predictions
- Automate the feature analysis and engineering e.g. establish functions to construct various transforms of the data and then calculate correlation to the output
- Use Tensorflow’s implementation of Keras to construct various model structures for experimentation, we recommend using the Keras functional API structure to ensure extension to more complex model structures is a simple task.
The outcomes of this customer project was part of documentation provided to Google to achieve the Google Cloud Machine Learning Specialisation in January 2020. Mantel Group delivers rapid, scalable and applied ML solutions for customers.
