Overview
This post aims to provide a walk-through of how to deploy a Databricks cluster on Azure with its supporting infrastructure using Terraform. At the end of this post, you will have all the components required to be able to complete the Tutorial: Extract, transform, and load data by using Azure Databricks tutorial on the Microsoft website.
Once we have built out the infrastructure I will lay out the steps and results that the aforementioned tutorial goes through.
I will go through building out the Terraform code file by file, below are the files you will end up with:
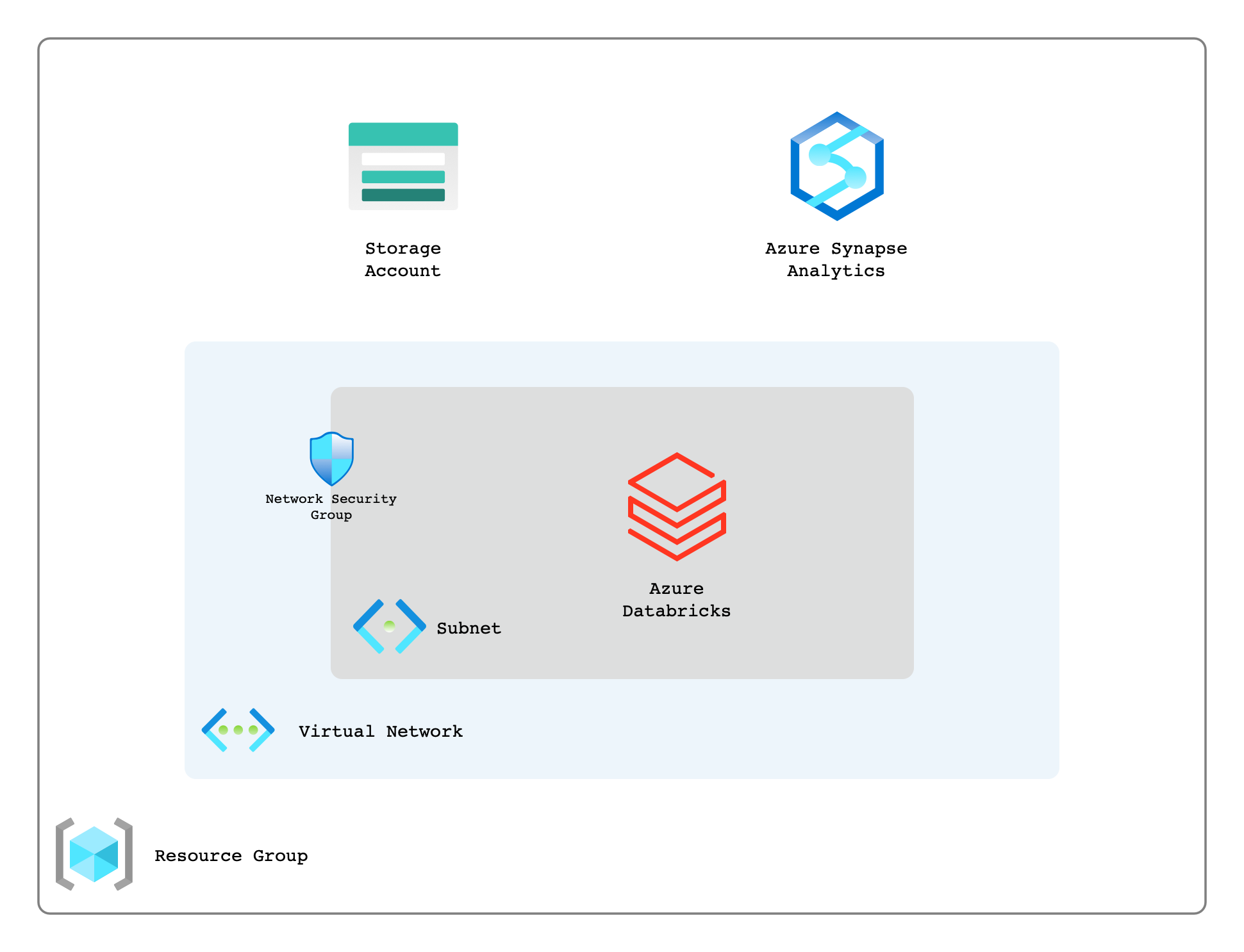
The below diagram outlines the high-level components that will be deployed in this post.
Providers
A key file here is providers.tf, this is where we will declare the providers we require and any configuration parameters that we need to pass to them.
Versions
Another pretty important file in modern Terraform is versions.tf this is where we tell Terraform what version of Terraform it must use as well constraints we may have about any providers. For example, we may want to specify a provider version, or we may be hosting a version/fork of the provider somewhere other than the default Terraform registry.
Variables
Now that we have our providers and any constraints setup about our Terraform environment, it is time to move onto what information we pass into our code, this is done by variables.tf.
Above we have declared four variables, some of which are required and some that are optional. I find it good practice to mark a variable as optional or required in the description. On two of the variables validation has been added to ensure that what is being passed into our code is what Azure expects it to be. Doing this helps surface errors earlier.
Main
main.tf is where anything that is foundational will usually live, an example of this for Azure is broadly an azurerm_resource_group as this is likely to be consumed by any other code written. By splitting out the code into different files it helps developers more easily understand what is going on in the codebase.
In our main.tf as can be seen below we are declaring a few things.
- locals {} – A local map that we can use to assist in naming our resources
- data “azurerm_client_config” “current” – Gives us access to some properties about the client we are connected to Azure with such as; tenant_id, subscription_id, etc
- resource “azurerm_resource_group” “this” { … } – Declares a resource group that we will use to store all our resources in
- resource “azurerm_key_vault” “this” { … } – Where we will store any secrets and/or credentials
resource “azurerm_databricks_workspace” “this” { … } – This is our actual Databricks instance that we will be utilising later.
As can be seen above we use the following format() blocks to more consistently name our resources. This will help give engineers more confidence in the naming of resources, and if there is standard that is kept to across the platform it will enable them to more easily orientate themselves within any environment on the platform.
Info
There are some more advanced ways to deal with this, such as the creation of a Naming Provider or Naming Module. The main advantage for having user friendly and consistent names for resources in my opinion is from engineers who are consuming Azure from the portal or CLI.
Network
Now that we have the code ready for our Databricks workspace we need to create the network as you can see that we are referencing those in our main.tf file. The types of resources that we are creating and their purpose are as follows;
- azurerm_virtual_network – The virtual network (or VPC on AWS/GCP) that will be used to hold our subnets.
- azurerm_subnet – The subnets that will be associated with our azurerm_databricks_workspace
- azurerm_network_security_group – This is where any firewall type activity will be setup.
azurerm_subnet_network_security_group_association – The association between the subnet and the network security group
Important
It is very important to note the following things:
- Delegation must be set on the subnets for the resource type Microsoft.Databricks/workspaces
- Network security groups must be associated with the subnets. It is suggested that the NSGs are empty as Databricks will assign the appropriate rules.
- In order to prevent an error about Network Intent Policy there must be an explicit dependsOnbetween the network security group associations and the Databricks workspace.
Azure Active Directory (AAD)
Before we look into creating the internals of our Databricks instance or our Azure Synapse database we must first create the Azure Active Directory (AAD) application that will be used for authentication.
Above we are creating resources with the following properties:
- random_password – A randomly generated password that will be assigned to our service principal
- azurerm_key_vault_secret – A secret that will be used to store the password for the service principal
- azuread_application – A new Azure Active Directory (AAD) application that will be used for the service principal
- azuread_service_principal – A new service principal that will be used for authentication on our Synapse instance
- azuread_service_principal_password – The password that will be associated with the service principal, this is what we stored in the key vault earlier
- azurerm_role_assignment – A new role assignment that will be used to grant the service principal the ability to access and manage a storage account for Synapse
Synapse
Now that we have our credentials all ready to go we can setup the Synapse instance, as well as any ancillary resources that we might need.
As per usual we will go through each of the resources being created and explain what they do.
- azurerm_storage_account – A new storage account that will be used as a storage and ingestion point for Synapse
- azurerm_storage_data_lake_gen2_filesystem – A container within our storage account that will actually house the data for Synapse
- azurerm_key_vault_secret – Secrets that will store the SQL administrator login and password
- random_password – A randomly generated password that will be assigned to our SQL administrator login
- azurerm_synapse_workspace – The synapse workspace which gives engineers the ability to deal with their data requirements
- azurerm_synapse_sql_pool – A new SQL pool that will be used to store Synapse data
- azurerm_synapse_firewall_rule – A new firewall rule that will allow all traffic from Azure services
Databricks
Finally from a resource creation perspective we need to setup the internals of the Databricks instance. This mostly entails creating a single node Databricks cluster where Notebooks etc can be created by Data Engineers.
Info
We will actually create a notebook later and perform some operations on it.
Outputs
The last thing we will need to write in Terraform will be our outputs.tf, this is the information we want returned to us once the deployment of all the previous code is complete.
In this we are simply outputting information such as our Service Principal details, information about our storage account and Synapse instance and how to authenticate to them.
Deploying the environment
Now that we have all the pieces ready for us to use we can deploy it. This assumes that the files are all in your local directory and that you have Terraform installed.
1. Firstly we will need to initialize terraform and pull down all the providers
terraform init
2. Plan the deployment
terraform plan -var=”environment=dev” -var=”project=meow”
3. Apply the deployment
terraform apply -var=”environment=dev” -var=”project=meow”
Running an ETL in Databricks
Now that we have our environment deployed we can run through the ETL tutorial from Microsoft I linked at the top of this page.
1. From the Azure portal within the Databricks resource click on Launch Workspace
2. On the Databricks summary page click on New notebook
3. On the open dialogue give the notebook a name, select Scala and then select the cluster we just created
4. From within the notebook in the first Cell but in the following code which will setup the session configuration
The result of the above command is below, and it shows the configuration has been written.
5. In the next cell we will setup the account configuration to allow connectivity to our storage accounts
We can see below that the account configuration has also been written.
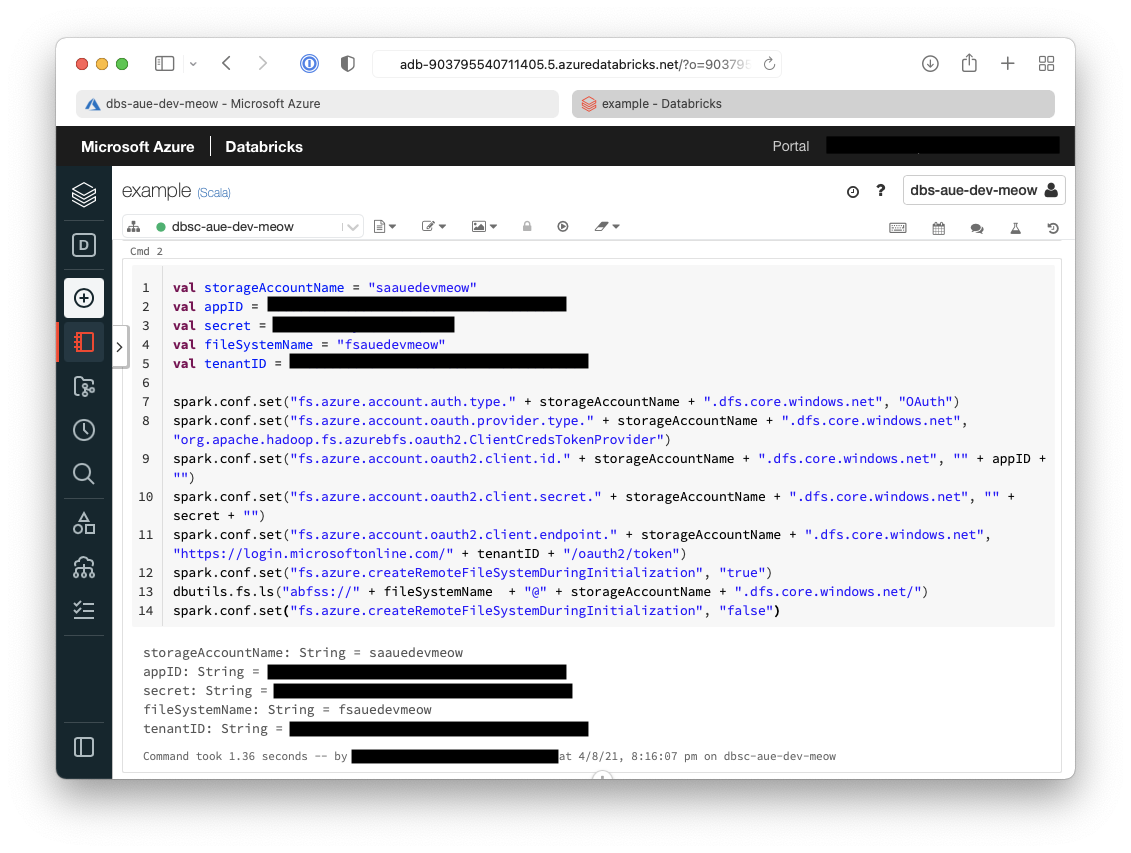
6. Now the sample data needs to be downloaded onto the cluster
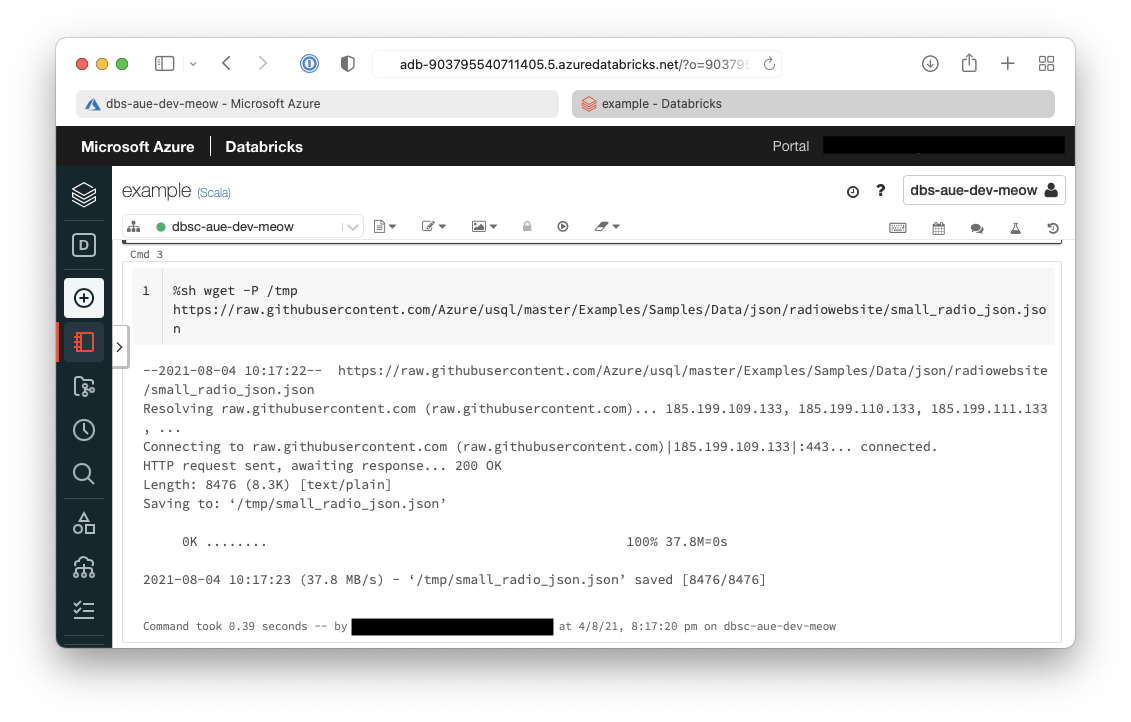
7. Now we need to transfer from the cluster to the Azure Data Lake Storage (ADLS)
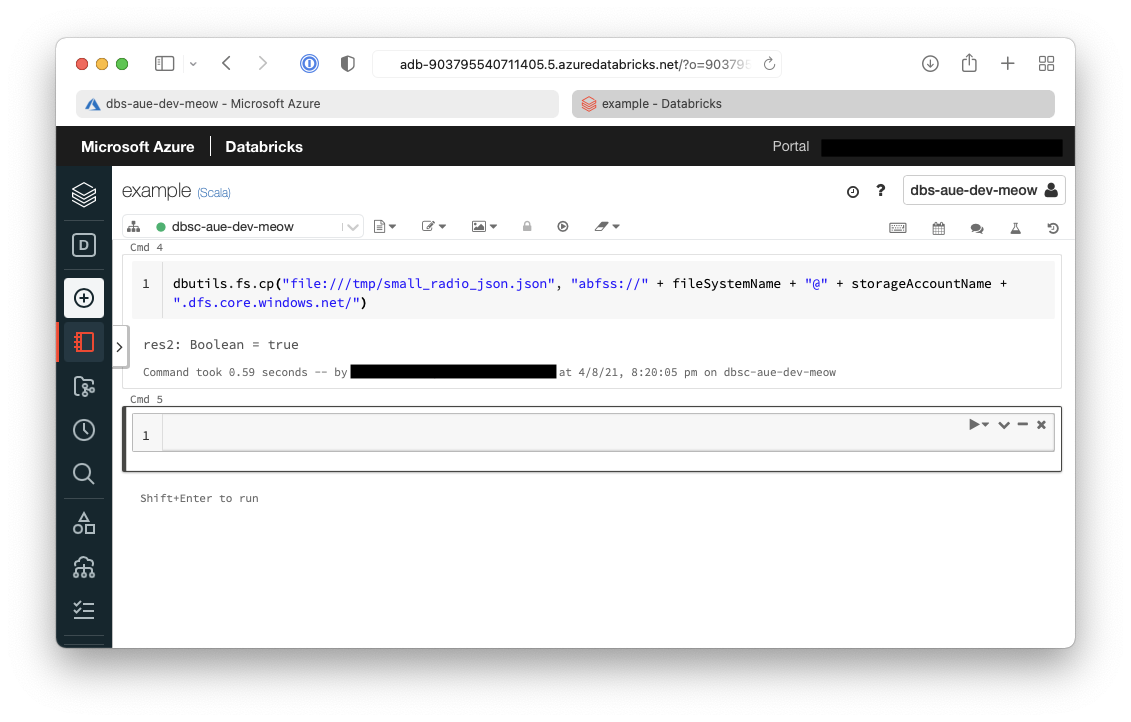
8. Extract the data from ADLS into a dataframe
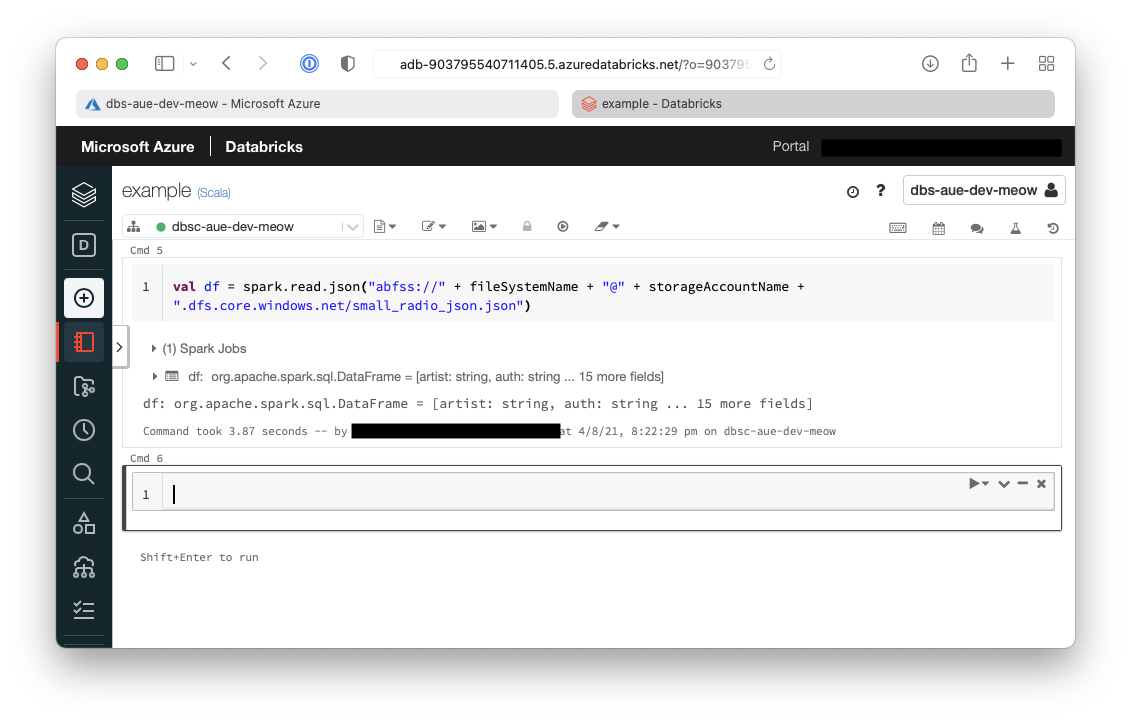
9. Show the contents of the dataframe
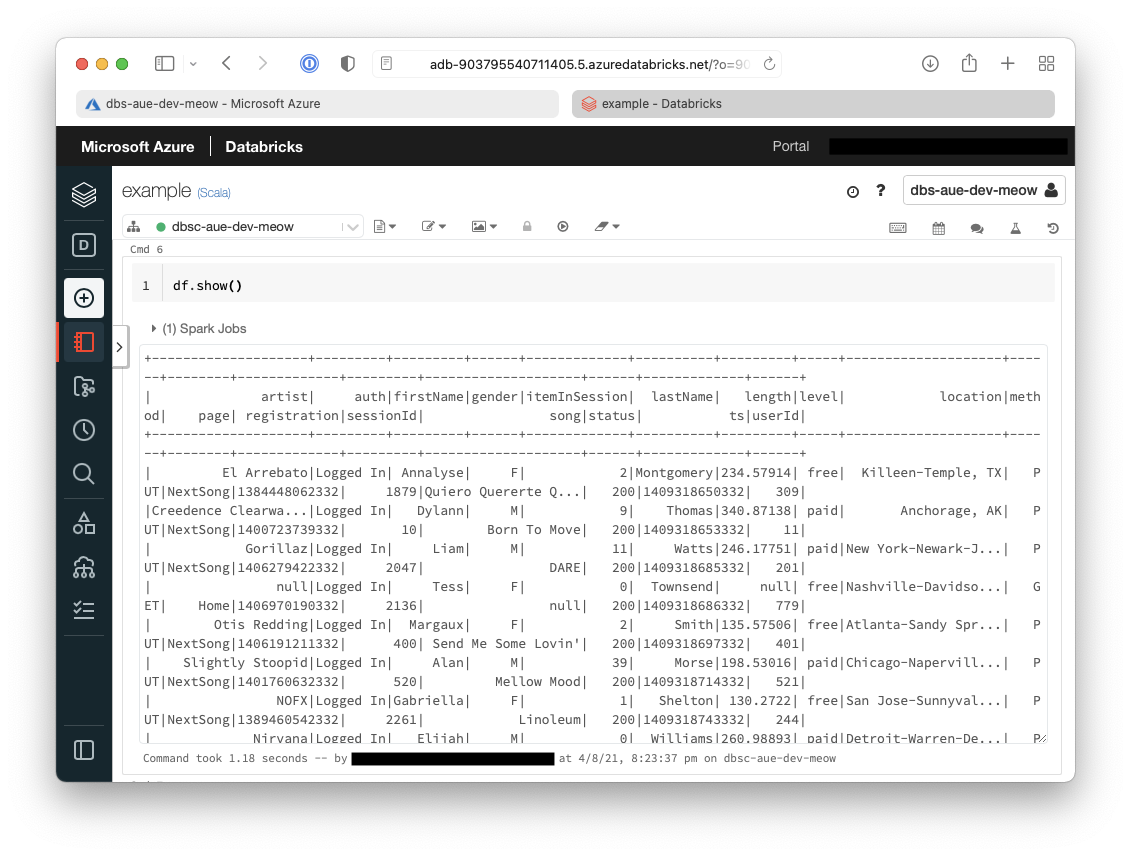
Tip
Given that this is running in a Databricks notebook a cleaner way to show the contents of the dataframe is to use the following:
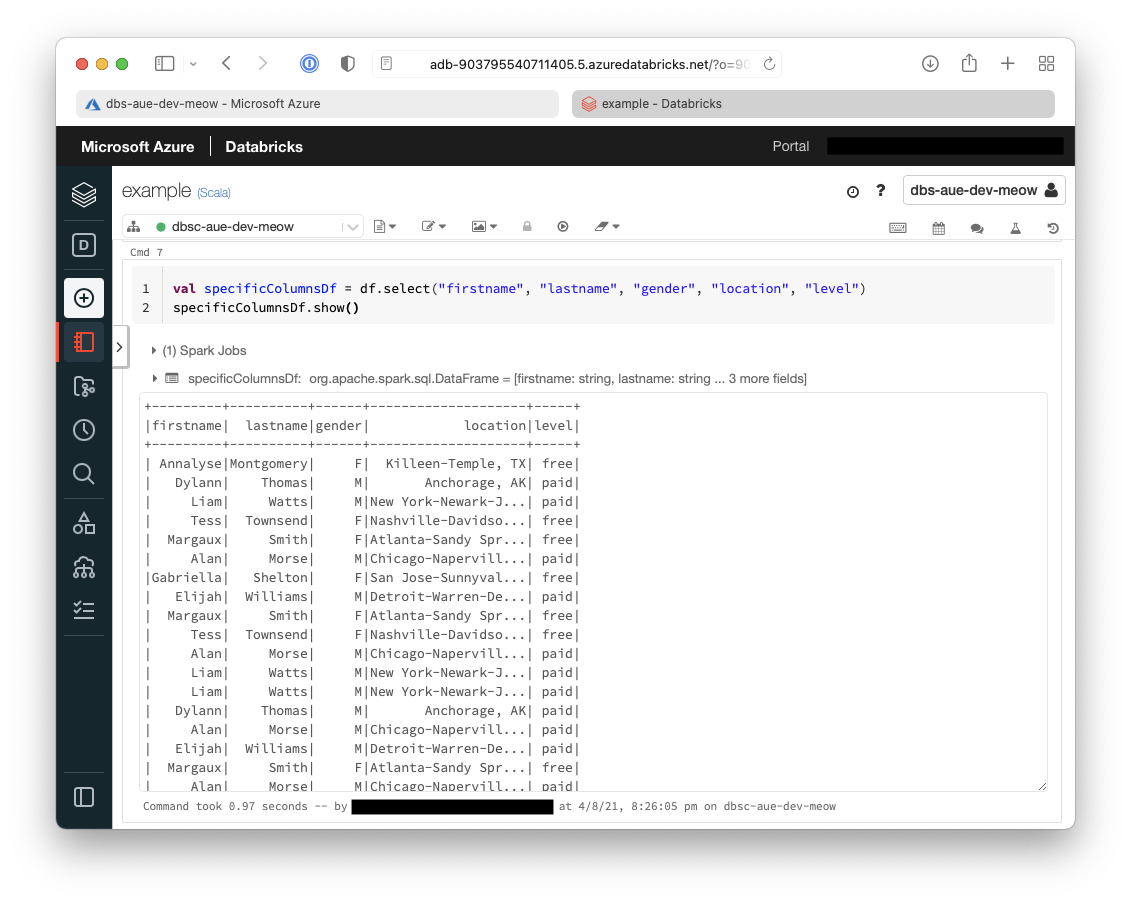
You can see below that the only columns that are now returned in the dataframe are:
- firstname
- lastname
- gender
- location
- level
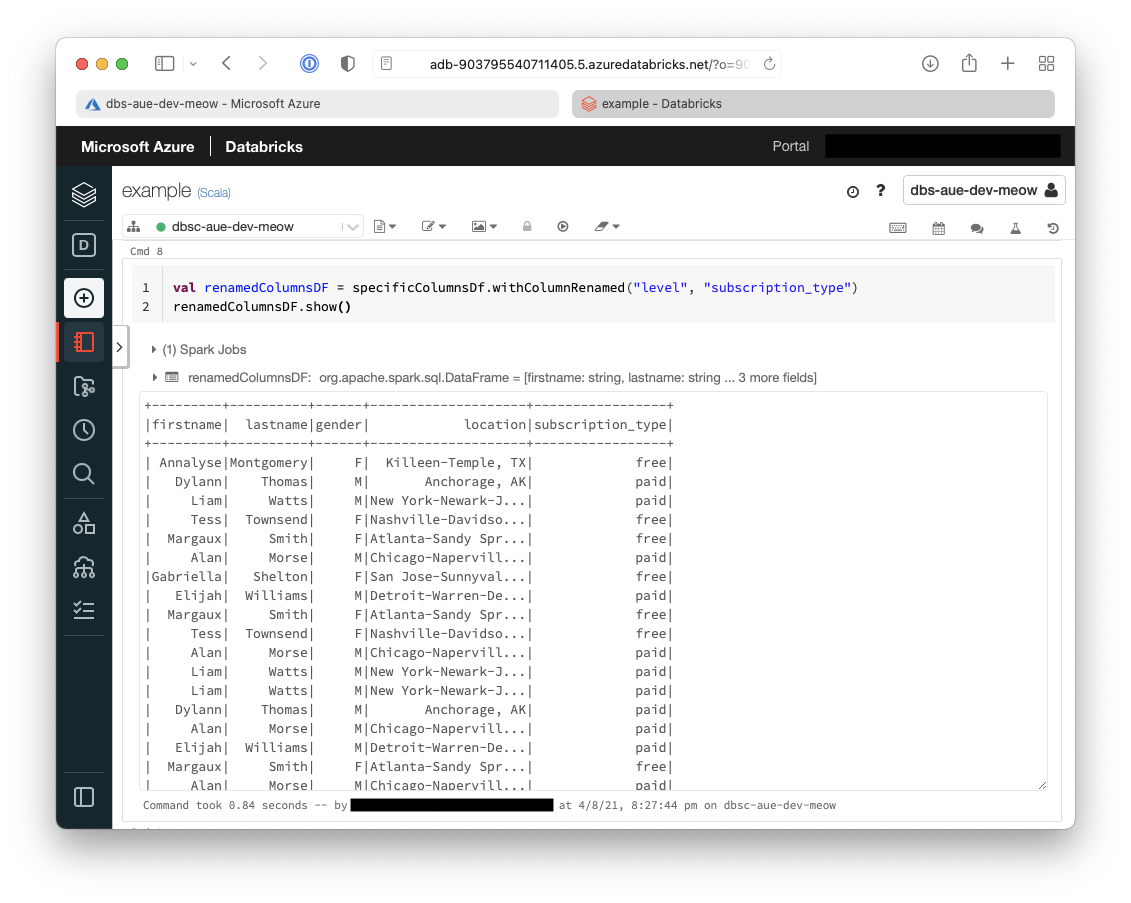
11. The second transformation that we will do is to rename some columns
Below shows that the second transformation we have performed is to rename the column level to subscription_type.
12. Now we are going to load that transformed dataframe into Azure Synapse for later use
