
I’ve always enjoyed seeing tools that make tasks easier. Tools that bring more non-technical users close to specific areas like Machine Learning and Data Engineering, abstracting technical details and allowing more focus on the objective. Google has been trying to do that for years with different tools like AutoML, BigQuery ML, Dataprep and more recently with Cloud Data Fusion (CDF).
In this post, I will shed the light on one of the new Google Cloud ETL solutions (Cloud Data Fusion) and compare it against other ETL products. This post is not meant to be a tutorial for any of the tools, it is rather meant to help whomever making a decision about which ETL solution to pick on Google Cloud.
Overview
Google released Data Fusion on November 21, 2019. It is a fully-managed and codeless tool originated from the open-source Cask Data Application Platform (CDAP) that allows parallel data processing (ETL) for both batch and streaming pipelines.
CDF avails a graphical interface that allows users to compose new data pipelines with point-and-click components on a canvas. Pipelines in CDF are represented by Directed Acyclic Graphs (DAGs) where the nodes (vertices) are actions or transformations and edges represent the data flow.
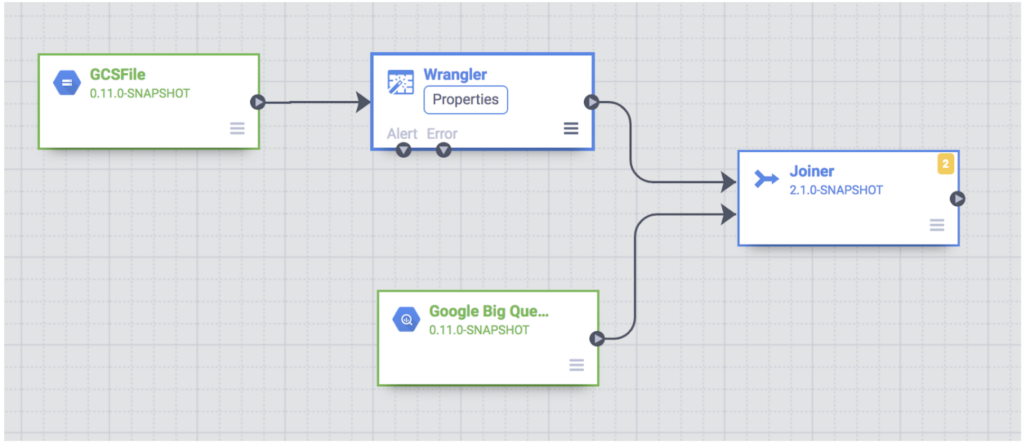
Example Pipeline – https://cloud.google.com/data-fusion/docs/tutorials/targeting-campaign-pipeline
Once the pipeline is created, it can be deployed and become in a ready-to-use state. On the deployment step, Data Fusion behind the scenes, translates the pipeline created on its interface into a Hadoop application (Spark/Spark Streaming or MapReduce). The application can then be triggered on demand or scheduled to execute on a regular basis.
At execution time, CDF provisions a per-run Dataproc cluster and submits the job to that cluster. It can also be configured to use an existing cluster. If the Dataproc cluster were provisioned by CDF, it will take care of deleting the cluster once the job is finished (batch jobs).
The idea is to make it easy to create pipelines by using existing components (plugins) and configure them for your needs. Data Fusion will take care of the infrastructure provisioning, cluster management and job submission for you.
Plugins
Data Fusion offers a variety of plugins (nodes on the pipeline) and categorises them into its usage on the interface.
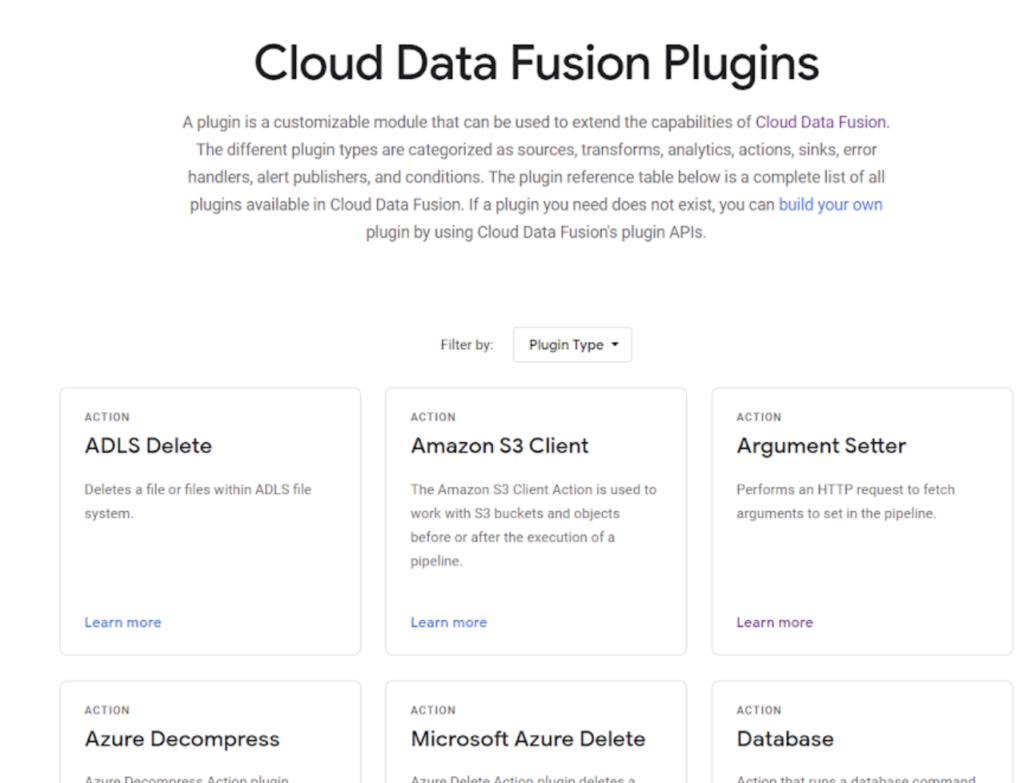
Plugins – https://cloud.google.com/data-fusion/plugins
Sources: Where we get the data from. On-premises or in the cloud. Examples: Kafka, Pub/Sub, Databases (on-prem or cloud), S3 (AWS), Cloud Storage, BigQuery, Spanner.
Sinks: Where the data will land. Examples: BigQuery, Databases (on-prem or cloud), Cassandra, Cloud Storage, Pub/Sub, HBase.
Transforms: Common transformations of the data. Examples: CSV/JSON Formatter/Parser, Encoder, PDF Extractor and also customizable ones with Python, JavaScript or Scala.
Analytics: Operations like Deduplication, Distinct, Group By, Windowing, Joining.
Error Handler: Error treatment in a separate workflow.
Alert publishers: Publish notifications. Examples: Kafka Alert Publisher, Transactional Message System.
Actions: Actions don’t manipulate main data in the workflow, for example, moving a file to Cloud Storage. More examples: Argument Setter, Run query, Send email, File manipulations.
Conditions: Branch pipeline into separate paths.
It is also possible to create your own customizable plugin in Java by extending the type you want and importing it into CDF’s interface.
Data lineage
Data lineage helps impact analysis and trace back how your data is being transformed.
Data Fusion offers two types of data lineage: at dataset level and field level.
Dataset level: Shows the relationship between datasets and pipelines over a selected period.
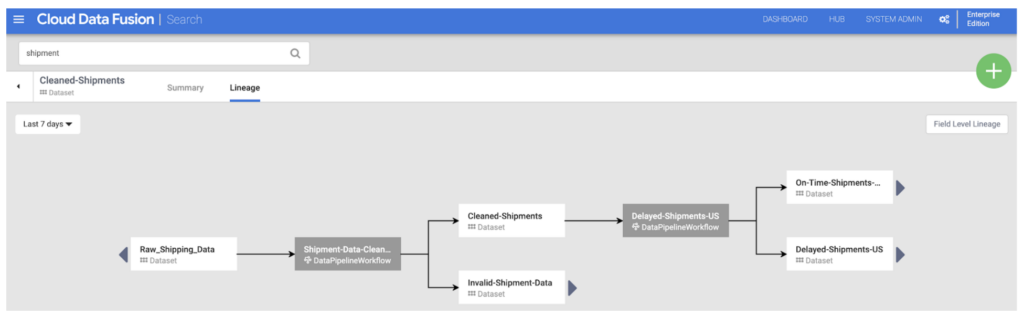
Dataset level – https://cloud.google.com/data-fusion/docs/tutorials/lineage
Field level: Shows operations done on a field or on a set of fields. For example, what transformations
happened in the source that produced the target field.
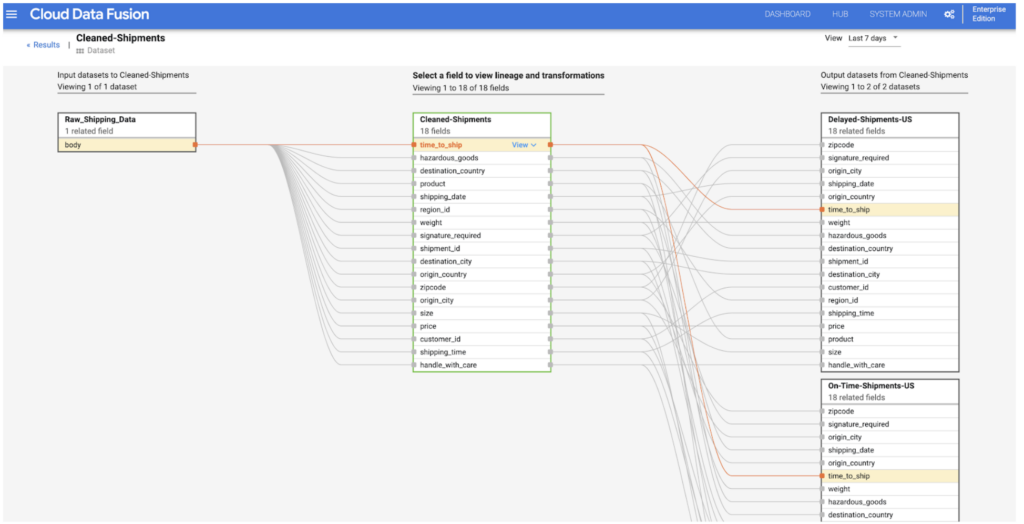
Field level – https://cloud.google.com/data-fusion/docs/tutorials/lineage
Metadata search
CDF allows cataloging and searching previously used datasets. It is useful to discover what has already been processed and available to reuse. It is possible to get dataset names, types, schemas, fields, creation time and processing information.
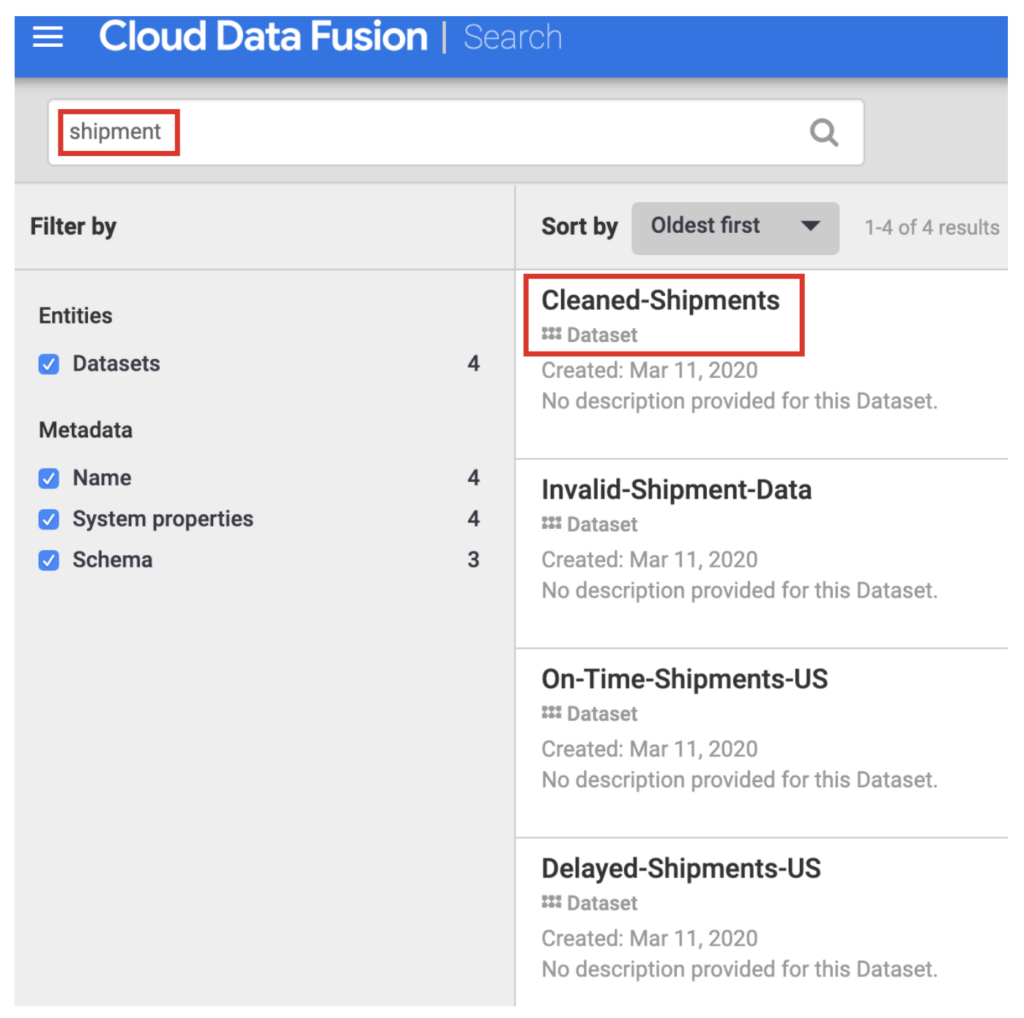
Metadata Search – https://cloud.google.com/data-fusion/docs/tutorials/lineage
Editions
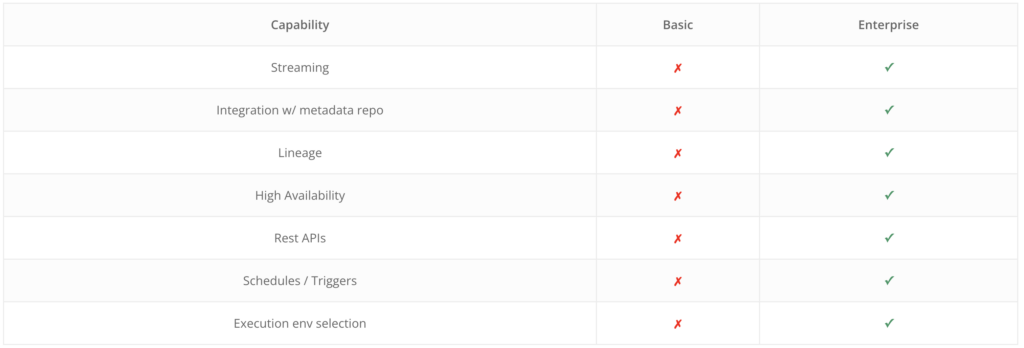
Data fusion offers two editions: Basic and Enterprise.
Besides pricing, the main differences between them are:
Comparing with other Google Cloud Platform tools
Google offers a bunch of tools in the Big Data space. It is common to confuse them, even unintentionally. However, it is our job to find which one is best for each solution and point out the trade-offs between them.
Dataproc is a managed Apache Hadoop cluster for multiple use. You can run Spark, Spark Streaming, Hive, Pig and many other “Pokemons” available in the Hadoop cluster. It is recommended for migrating existing Hadoop workloads but leveraging the separation of storage and compute that GCP has to offer. Dataproc is also the cluster used in Data Fusion to run its jobs.
Dataflow is also a service for parallel data processing both for streaming and batch. It uses Apache Beam as its engine and it can change from a batch to streaming pipeline with few code modifications. It has also a great interface where you can see data flowing, its performance and transformations. Dataflow is recommended for new pipeline creation on the cloud.
Composer is the managed Apache Airflow. It is a containerised orchestration tool hosted on GCP used to automate and schedule workflows. Composer is not recommended for streaming pipelines but it’s a powerful tool for triggering small tasks that have dependencies on one another. It uses Python and has a lot of existing operators available and ready to use.
Here is a summarised table comparing the tools:
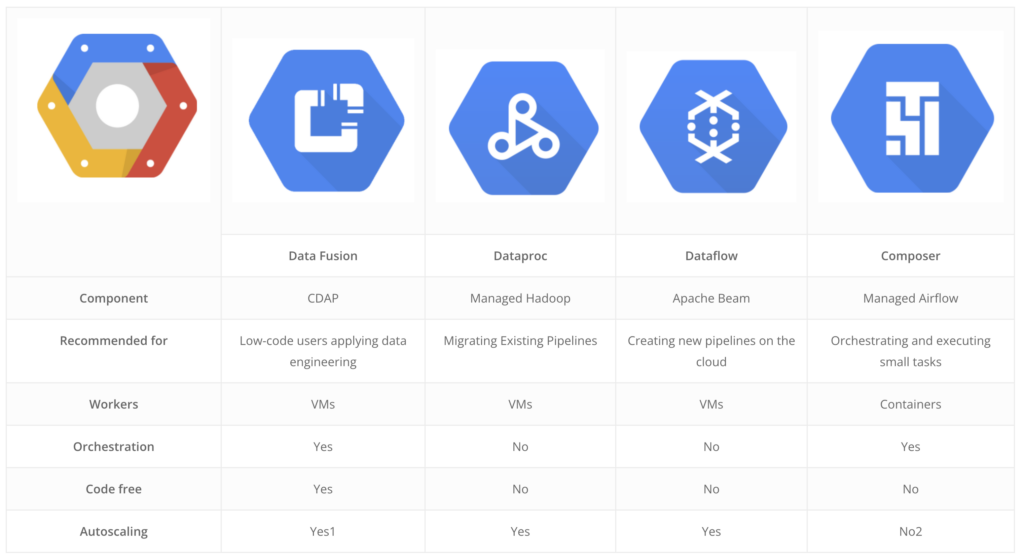
1 Data fusion at the moment supports autoscaling only if it uses an existing cluster with auto scale already configured.
2 It is possible to autoscale Composer with Cloud Functions and cluster usage monitoring.
Comparing with Matillion
Matillion is a proprietary ETL/ELT tool that does transformations of data and stores it on an existing Data Warehouse (e.g. BigQuery). On GCP, it can be deployed via Marketplace and can run BigQuery queries for transformations. It is also an interface tool with drag-and-drop components and has a lot of integrations available.
One of the advantages of using Matillion is to use BigQuery’s compute capabilities to do transformations using BigQuery SQL. In that way, most of the workload will be done by BigQuery itself and the pipeline would perform ELT instead of ETL.
More differences between them are:

Conclusion
Some tools are adequate for certain situations, not only technically but also depending on business requirements. Always consider other options while implementing a solution.
Cloud Data Fusion is recommended for companies lacking coding skills or in need of fast delivery of pipelines with low-curve learning. However, keep in mind that CDF is still fresh in the market and specific pipelines can be tricky to create. It is recommended to first give it a try before designing your pipeline to validate if Data Fusion is the right tool for you.
As a relatively recent tool, CDF also has good potential and developers working on a lot of features. It is definitely an option to consider if you have plans to migrate to the cloud.
Thanks Mohamed Esmat for reviewing this article! Also, checkout my previous post about how to secure Personally Identifiable Information (PII) using Data Fusion and Secure Storage.
