Written by Mirjam Uher
Background
GraphQL is a powerful query language for APIs that was released in 2015. It has since gained a lot of attention for its schema-driven approach and focus on giving clients precise control over the type of data they receive. While it can be used in conjunction with REST and other API technologies, it is a popular replacement for REST APIs for frontend development, as it allows for multi-source data retrieval in a single API call.
At Mantel, we have been seeing growing interest among our clients in GraphQL. In response, our team investigated the latest developments in GraphQL in order to provide better guidance and recommendations to our clients. We are particularly interested in the newer federation techniques that promise to better support multiple teams working on a single solution.
With this in mind, we have created this blog series to explore various GraphQL designs, ranging from a simple BFF (backend-for-frontend) architecture built by a single application team to a federated architecture that supports a diverse set of clients.
There is no one-size-fits-all solution when it comes to architectural design. The right approach is one that aligns with your business objectives and takes into account your organisation structure, resources and constraints. We hope that this blog series will assist you in determining whether and how to adopt GraphQL for your project.
Structure of this GraphQL Blog Series
Part 1: What is GraphQL and when should I use a monolithic or backend-for-frontend architecture?
In this introductory blog post, we will be going through the basics of GraphQL and how to use it with the popular Apollo Framework. Our main focus is to help you define what questions you want to ask when deciding to adopt GraphQL, and to decide which pattern is right for you.
Part 2: Case Study I: Introducing a monolithic GraphQL architecture
We will present the Case Study of Mantel U, and how their frontend team introduces and promotes adoption of GraphQL throughout the company. This practical example will help you anticipate and think about questions you are likely to face when introducing GraphQL to your team.
Part 3: When should we adopt a federated GraphQL architecture?
Federation 2 was recently introduced by Apollo and is a promising alternative to schema-stitching. In this blog we will explore how it works, when to use it and how splitting your graph into a service-oriented architecture can increase your development speed and re-introduce clear separation of concerns.
Part 4: Case Study II: Introducing Federation and a service-oriented architecture to your graph
This part will show you with the example of Mantel U how to practically implement the theory of the previous blog post. We will walk you through which questions Mantel U’s team considers to decide if implementing a federated GraphQL is the right step for them, and discuss how to merge ownership of the resulting subgraphs into their logical domains.
What is GraphQL?
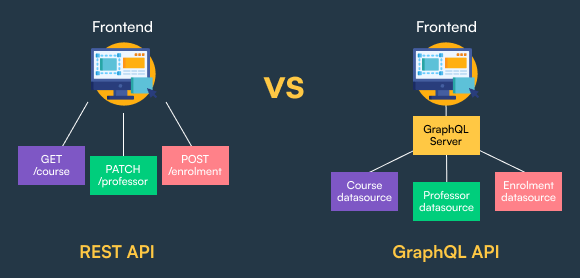
GraphQL is a querying language for APIs which can be used instead of or in conjunction with alternative API architectures, such as REST. It provides a single endpoint for all data queries, as opposed to the multiple endpoints provided by REST, and allows consumers to specify the data they need.
A GraphQL server will accept GraphQL queries that comply with a contract that is provided to clients, and will resolve those queries, supplying exactly what the requester asked for: nothing more and nothing less. The client that makes the request does not need to know where the data is sourced from, nor how many sources need to be used to resolve the query. All that matters to the client is that the required data has been sourced from somewhere within the advertised data graph. When it comes to changing the source data, the same is true: requests for changes (GraphQL mutations) that comply with the contract will be accepted by the server and will subsequently be resolved to update the appropriate sources.
What problems does GraphQL solve?
The primary advantage of GraphQL is that it allows consumers to only query one endpoint to get the data they need, eliminating the need for multiple requests and the over- and under-fetching of data that often occurs with REST. This is an especially attractive feature for frontend development. For one, it minimises data consumption, which is often a concern for mobile apps. Secondly, it eliminates the need for data-massaging in the frontend, making frontend repositories more readable and maintainable.
Another benefit is that GraphQL was originally developed by Facebook, the same company that created REACT, making it designed to integrate neatly with most frontend libraries. This allows web developers to easily access and propagate data or errors.
Additionally, GraphQL puts the query schema front-and-centre in development. This can greatly ease communication between frontend (FE) and backend (BE) teams and decouples the FE feature development slightly from the BE, as FE devs can restructure the way they receive data by simply changing their query structure.
In this blog series, we will be exploring GraphQL in conjunction with the popular Apollo server and client libraries.
Is GraphQL used with or instead of REST or other API architectures?
While GraphQL is often talked about as a replacement for REST, our experience with clients shows that it is most commonly introduced as a wrapper for existing REST APIs. This will be the use case Part 1 and 2 of this blog series investigate, while Part 3 and 4 will discuss the replacement of REST.
One feature of GraphQL worth mentioning, which may form part of a future article, is the Subscription feature. You may sometimes hear this referred to as the “Live Query” feature. This allows a client to express interest in changes to aspects of the graph on the server, ultimately meaning that those aspects in the graph model can be automatically sent to the consumer when that part of the graph model is changed. Whilst this same thing can be achieved with some work using REST, the Subscription feature comes built-in with GraphQL.
GraphQL Architecture Styles
A discussion of architectural style in software solutions can take us down many paths, depending on which aspect of a solution we are discussing. There are many recognised patterns and approaches to how we lay out the various elements and how we construct those elements for solutions using GraphQL. In this section we will discuss some patterns, and in particular the approaches available to us for constructing the graph that is central to GraphQL, and candidate components for where that graph resides.
What kind of architecture/pattern is best for GraphQL?
GraphQL is often introduced to a company as a BFF layer (backend-for-frontend, see next section) for one specific FE client. As more teams start to adopt GraphQL, the service either turns into one large monolithic graph queried by multiple frontend clients, or every frontend client creates its own GraphQL BFF server.
As adoption grows, maintenance and scalability of the monolithic graph or the many BFF graphs can become a pain point; this is when most companies look at options like schema-stitching or a federated architecture.
All of these approaches can be the right choice in a certain context and to a certain scale. We will be exploring when to use BFF and Monolithic graphs in this article and part 2 of the blog series, before discussing Federation in more detail in part 3 and 4.
Backend-for-frontend (BFF) GraphQL Pattern

The BFF pattern is a popular language-agnostic software pattern for projects with multiple frontend consumers that need different sets of data. When everyone is querying the same shared data source, the APIs can become bloated and a bottleneck for rolling out new features. A BFF solves this by acting as a middleman between consumer and BE, specialising in providing the set of data needed by that particular consumer. Furthermore, this can implicitly lead to more security: sensitive data can be omitted when sending a response to the frontend, and the abstraction of the BFF makes it harder for hackers to target the application.
When organisations first start using GraphQL, they often choose a BFF approach to meet the needs of a single application wrapping existing data sources. This allows a frontend or product team to quickly access data for their frontend without requiring changes to downstream services.
As adoption of GraphQL scales, some companies may introduce a separate BFF for each frontend client, while others contribute to a single GraphQL endpoint for all clients. The latter is achieved by implementing a GraphQL monolithic pattern or through graph-stitching or federation techniques.
The Benefits
- A BFF design approach is a low-stakes way of introducing GraphQL
- Teams can focus on a particular piece of work, i.e. the needs of one client.
- Simplifies the FE as data handling related logic can be moved from the FE repositories to the BFF layer.
- Once the server has been set up, it becomes straightforward for (new) team members to add and edit queries
The Drawbacks
- Graph bloat can easily occur as more stakeholders want to use the BFF
- Improper implementation of depth or rate limitation can lead to performance issues
- BFF-inherent problems of duplication:
- changes to the backend require updates of each BFF querying it
- security-updates, changes of libraries or company policy need to be implemented everywhere
- possibility of teams falling behind latest (security) best practices
Monolithic Pattern
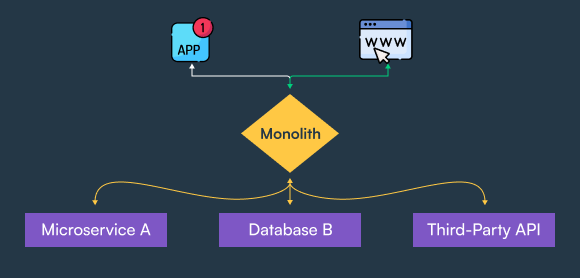
A monolithic architecture describes a solution where all functionality is packaged in a single codebase and deployable unit. This functionality may span multiple business domains and can be contributed to by multiple teams.
When applied to GraphQL, a monolithic pattern describes a single schema which serves multiple clients and aggregates data from one to many business domains. Ownership of the server may be shared by multiple frontend and/or business service teams.
A monolithic GraphQL server often emerges as adoption of GraphQL grows in an organisation. To avoid having to reinvent the wheel, new clients will integrate with the existing server, which consequently grows and often becomes difficult to maintain due to lack of clear ownership and tight coupling between domains.
This approach shares many of the same advantages and disadvantages as other monolithic patterns.
The Benefits:
-
Easy to set it up and get started
-
Simple infrastructure setup
-
Global type-safety
-
Newcomers take advantage of the existing setup and can quickly become productive
The Drawbacks:
-
Development velocity slows down as the monolith grows. It becomes harder to onboard new team members and changes increasingly lead to merge conflicts.
-
Operational complexity rears its head as the monolith gets scaled. Bottlenecks may start emerging when implementing new features
-
Boundaries between team responsibilities and separation of concern get blurred
-
Involuntary coupling of logical domains may occur
When is it time to move on?
A non-federated GraphQL setup is a good place to begin with, especially when an organisation has limited knowledge and experience with GraphQL. However, keep a lookout for the following signs that you need a more sophisticated approach as adoption of GraphQL grows within your organisation:
Monolithic graph:
-
The graph is so large that new starters take a long time to understand how the solution hangs together
-
Duplication of work as team members don’t realise their use case had already been implemented
-
Clients have to work around the graph setup of other teams
-
Standardisation slips
-
Blurred boundaries of ownership between teams
-
Merge conflicts
-
Graph becomes a bottleneck for rolling out new features in frontend or backend
Multiple BFF graphs:
-
No standardisation between BFF setups
-
Clients need to start querying multiple BFFs to get all the data they need
-
Updating or changing aspects of all GraphQL servers becomes expensive and hard to communicate, and the duplication of work consumes expensive resources
-
Teams fall behind in staying up-to-date with security requirements
Best Practices & Tools that might help you on your journey
GraphQL is popular and people want to get the most out of it:
In order to realise the full potential of GraphQL, an organisation may wish to embrace the same principles that lead to the adoption of microservice architectures by breaking up the monolith along business boundaries. Ideally, GraphQL should not be wrapped around business services as an afterthought, it should replace them.
If your organisation seeks to expose a unified endpoint to the frontend, but also benefit from decoupled graph development along business boundaries allowing teams to work and scale independently, Federation might be the right choice. We will be discussing the benefits and challenges of Federated GraphQL and how to transition to it in parts 3 and 4 of this series.
Here are some of our insights regarding what you must and should have …
Must:
-
Implement automated validation of your GraphQL before shipping to production; ideally integrated in your CI/CD pipeline. For example, this can be achieved by passing health checks for your spun up GraphQL instance or by using Apollo’s Centralised Schema Registry.
-
Create a standard for naming operations in your project.
-
Use specific data types, i.e. (custom) scalars and enums, to define set of valid values whenever you can
-
GraphQL practically invites devs to create nested queries. Therefore, limits should be implemented to decrease the potential for DoS attacks or unintended large and expensive fetch requests. Apply a depth limit, amount limit, pagination and/or query-cost analysis before processing an incoming request wherever appropriate, or consider whitelisting accepted queries. These features are not inbuilt, but there are a number of recommended libraries that you can use.
Nice To Have:
-
If more than one team is consuming your GraphQL layer, increase observability by attaching client name and version to every operation’s trace. This will allow you to see which fields are being consumed the most, and will allow you to delete deprecated fields with more confidence. If you are using Apollo Server & Apollo Client’s library, there is an inbuilt feature that allows easy capturing of the client’s name and version in the request headers to your trace operation, but it can also be manually implemented.
-
Especially when querying from third-party services: think about server-caching! Similar to other aggregator services, your bottom line, latency and resilience against malicious attacks can benefit from caching data retrieved for a query. For example, Apollo Server provides an optional `cacheControl` that can be set per request type or single field. It lets you define the maximum amount of time a field’s cached value is valid, and if it is specific to a single user. This setting can drastically reduce your roundtrips to data sources.
Conclusion
GraphQL is a widely used query language that offers many benefits for frontend developers, allowing them to request only the data they need from just one endpoint. The architecture in which GraphQL is implemented, including the schema and data-fetching resolvers, can take various forms.
In this article, we discussed the common patterns of using GraphQL in a monolithic or backend-for-frontend architecture. Both share similar advantages, such as the ease of setup, ownership of each service often residing with just one team, and scalability.
However, as they scale to serve data from more and more endpoints, both architectures experience challenges. Predominantly, these come in the form of lacking maintenance of standards, increasing complexity of ownership, suffering upkeep of best practices with resulting potential security holes. Additionally, the services will require a high level of domain knowledge to effectively manage.
All these issues lead to decreasing development speed and increasing cost. This is where Federation becomes an attractive proposal, which we will further explore in upcoming articles in this blog series.
Using unfederated GraphQL introduces some noticeable cost as it scales; especially through duplication of work, maintainability and separation of concerns. This is where Federation becomes an attractive use-case; a topic we will further explore in Part 3 and 4 of this blog series.
