Introduction
If you want to refresh your knowledge on GraphQL or the meaning of monolithic and BFF patterns, please check out part 1 of this blog series.
Case Study Part I: Adopting GraphQL
Throughout this blog series, we will be referencing the fictional university Mantel U for the case study. The examples given are greatly simplified to keep the focus on GraphQL.
Case Outline
Your team is in charge of providing functionality for the website which allows students to view subjects, classes, departments, lecturers and sign up for courses.
Your website is set up as an existing React project. So far, the front end application has been fetching data via REST API endpoints from various microservices. However, your team is experiencing friction, due to retrieving data from microservices with different standards for their REST API endpoints.
Some of their complaints are:
- “We find the REST endpoints to not be intuitive. The fields have odd names and nested fetching requests are cumbersome to write.”
- “We have to send multiple requests to collect all the data needed for one page. Every query is under- or over-fetching data.”
- “Our React components have to handle a lot of API-related business logic and data massaging. This takes time away from us focusing on the actual UI.”
Introducing GraphQL
Designing the Schema
Taking advantage of this opportunity of implementing a new, schema-focused API design, your team decides to invest some time into outlining what problems they are trying to solve. By having a clear understanding of the current pain points, you are poised to take advantage of GraphQL’s promise of stripping away unfitting coupling of data in legacy REST endpoints.
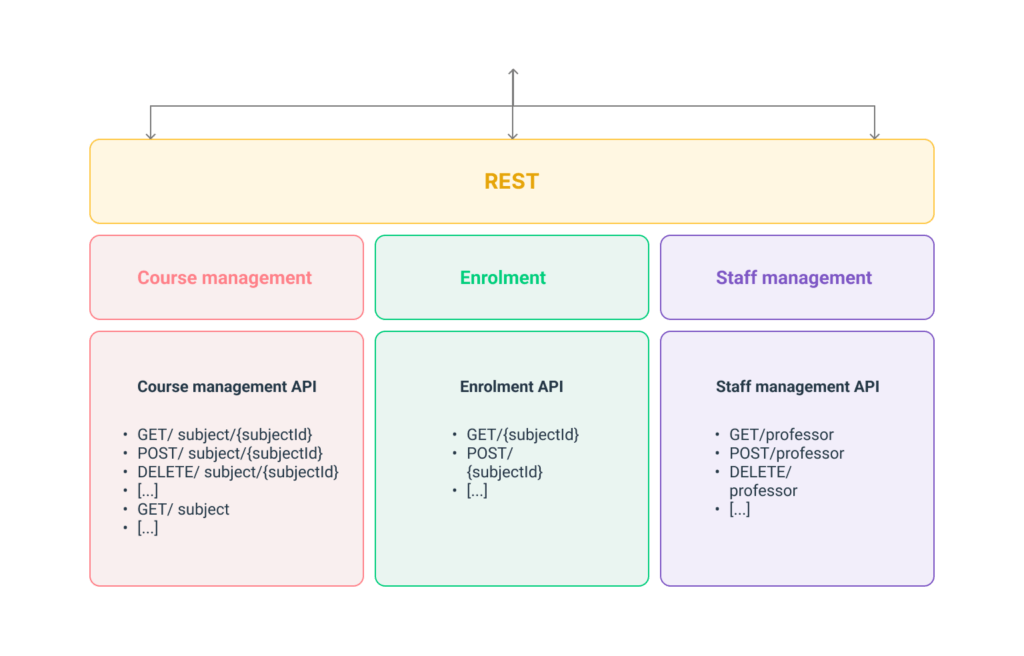
Currently, your team is accessing REST endpoints that follow the typical CRUD pattern.

- What APIs and fields are we actually using?
- How can we provide data to the front-end so that there is no / minimal need for data massaging?
- Do we want to rename any fields to make them clearer?
The first webpage you want to introduce GraphQL queries shows information about subjects. The blueprint of the page looks like this:
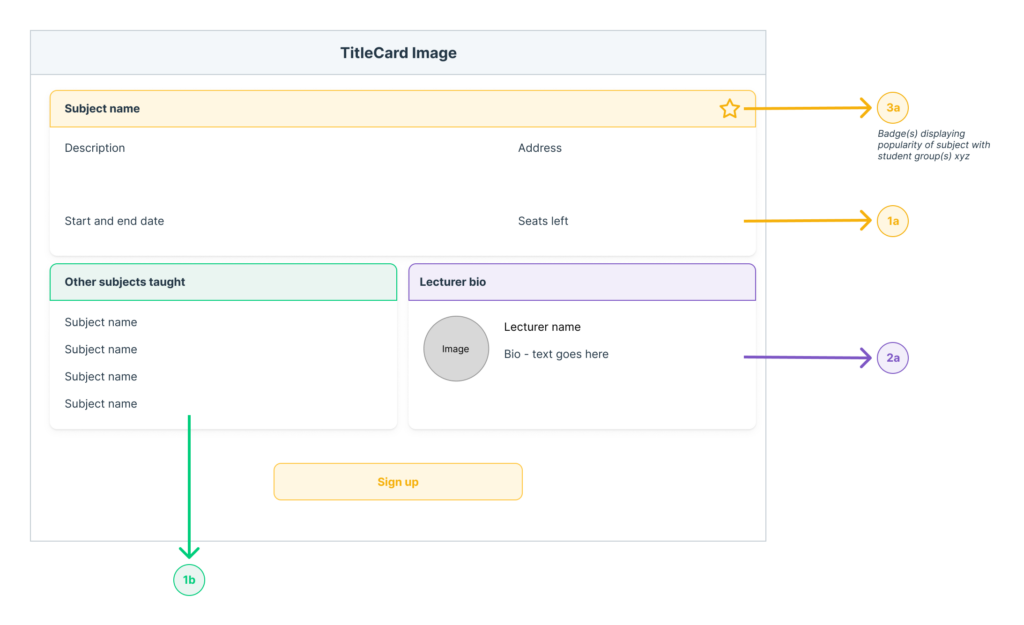
To obtain the require information from the current REST endpoints, your team has to perform the following queries:
- Course Management API:
- GET /course/{subjectId}:
- Returns subject information and `professorID
- GET /{professorId}:
- Return all subjects run by this professor
- GET /course/{subjectId}:
- Staff Management API:
- GET /professor:
- Use `professorID to get the professor’s name, picture and bio
- GET /professor:
- Enrolment API:
- GET /{subjectId}:
- Return information on how many seats are left in subject and information needed to display the appropriate popularity badge.
- GET /{subjectId}:
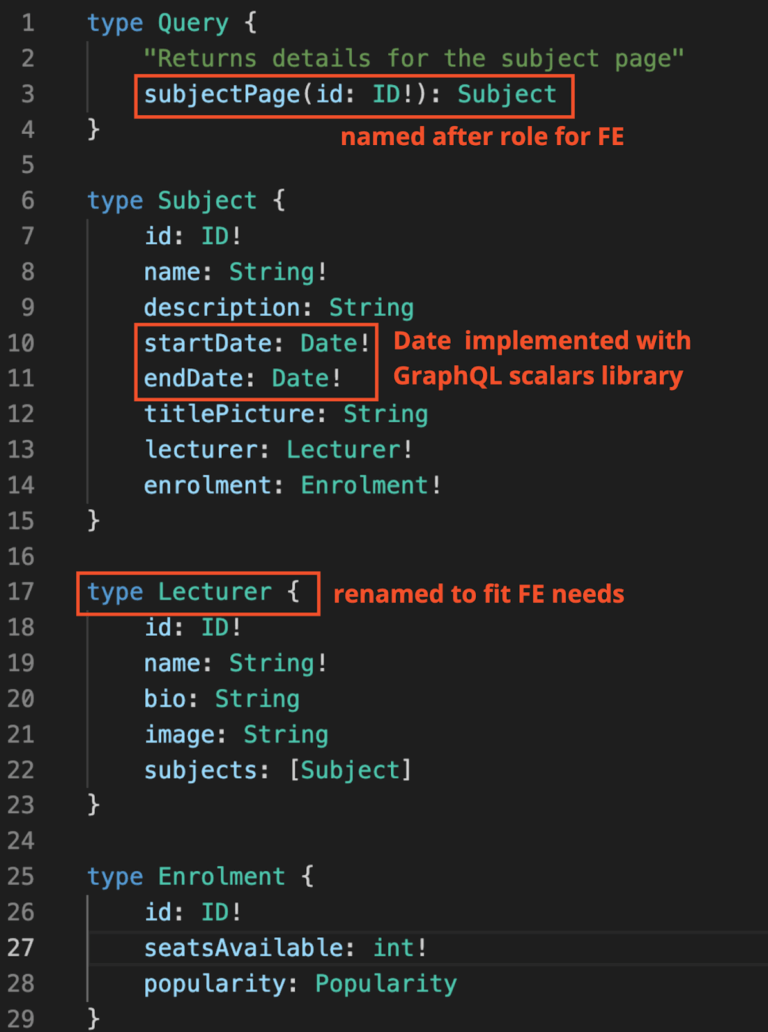
By allowing GraphQL to handle the above calls and taking advantage of its data-just-as-needed promise, your team can reduce the effort of over-fetching and data massaging. Your team also decides to rename the antiquated field name “Professor” to “Lecturer” to more accurately represent that group of users in their front end.
Considering these requirements, your team designs their first query based on their needs and implements it for the subject page:
Growing pains
The GraphQL BFF layer works well for your team as you expand it to supply all front-end services you own. As your team continues to broaden the usage of the GraphQL BFF layer to encompass all the frontend services under your control, it attracts the attention of other teams. The team responsible for the Android and iOS apps also intends to utilise GraphQL, raising the question of the best approach for your organisation.
There are several options available on how to expand the current implementation. Every team could implement their own GraphQL BFF layer or new teams could integrate into the monolithic schema. Both approaches have their advantages and disadvantages, as previously discussed in Part 1 of this series.
Another popular approach your team researches while trying to bridge the gaps of a growing system is “schema-stitching”. This approach, while allowing a lot of flexibility, is not a standardised one, making it hard to estimate the cost and effort involved in this approach.
Federation v2 has started supplanting schema-stitching with the promise of supporting building GraphQL similarly to microservice with modular and independent components without needing to reinvent the wheel at every step.
Your team chooses to investigate Federation v2 before proceeding, and we will be exploring this option with them in part 3 and 4 of this blog series.
