This blog kicks off a series of articles focussing on the Cloud Managed DevOps Service at CMD Solutions. The series will focus on the “Customer Journey” and will include foundational to advanced topics around designing and managing environments in AWS. A common theme will be how CMD Solutions work with our customers to leverage the latest techniques in Cloud technology to incrementally mature our customers’ environments.
Providing background on the customer’s journey from traditional on-premise environments through to the migration to the Cloud and how a Managed Service can help inform customers who are looking to leverage a Next-Gen Managed Service provider.
The traditional approach to release management
For many years, traditional operations teams relied on three key components for success:
- a detailed implementation guide with step-by-step instructions on the deployment;
- (manually) configured servers that incrementally change with every release and;
- key personnel that understood these machines and how to maintain them.
With each release, the risk of a compatibility issue between software and infrastructure increased. It was not possible to track the myriad of changes over these longer living application platforms. When key personnel that built and maintained the test servers left the organisation, their replacements would spend many days or months becoming familiar with the complex environment they inherited.
Conflicting Methodologies
As new delivery methods such as Agile were adopted by software projects, rapid prototyping and the concept of the Minimal Viable Product (MVP) became standard practice. However, approaches to infrastructure management and production support were slow to adapt to these new ways of working. This caused a bottleneck in the Software Development Life Cycle, causing larger more complex projects with multiple streams of change to queue, negating the improvements of faster development cycles.
Development teams would build a new product or make a major change to an existing environment and pass the change to test teams, who in turn passed the final version to an operations team to release to production. Any failures would be passed back up the chain and, in many cases, the responsibility fell to the development teams to resolve. The old adage “it worked on my machine” was a common mantra of developers and “it must be a software problem” would be the standard response from infrastructure / operations teams.
Next Generation : Cloud Computing
Over the last ten years, Cloud adoption has been touted as a cure-all, meant to solve these issues through re-usable, like-for-like hosts that could be provisioned in seconds and not weeks. Many large enterprises started to look to cloud solutions providers for help as a move to the cloud was considered in the early years of cloud adoption, the solution to most of their problems. Capacity management was improved through the Cloud’s elasticity to accommodate fluctuations in demand became a thing of the past. Infrastructure as Code and configuration management tools provided a “rinse and repeat” approach to provisioning infrastructure, but there was a hitch. “Lift and Shift” migrations involved very little modernisation and focussed on moving the entire stack with as little variation to the existing architecture as possible. Tactical compromises were made, and more strategic fixes deferred for a time in the future that, in many cases, never came due to budget constraints or competing priorities.
The Need for Organisational Change
Another challenge and key to the future success or failure of many Cloud adoption strategies was organisational. The Lift and Shift projects were usually fixed price, short term engagements. The customer was left with very little strategic advice as to how the organisation should change to best fit their environment once the engagement ended. Operations teams would fall back to old habits and, with minimal further investment post migration go-live, these environments would start to look similar to their on-premise predecessors.
The adoption of Agile, led to the development of a series of new engineering practices and patterns that became known as DevOps. The cornerstone of DevOps practices was a key change to culture from siloed to cross-functional teams.
Many of these traditional organisations thought that adopting some parts of Agile and some parts of DevOps would be enough to make them successful, but many organisations failed in their initial attempts to modernise because they maintained their siloed approach to delivery.
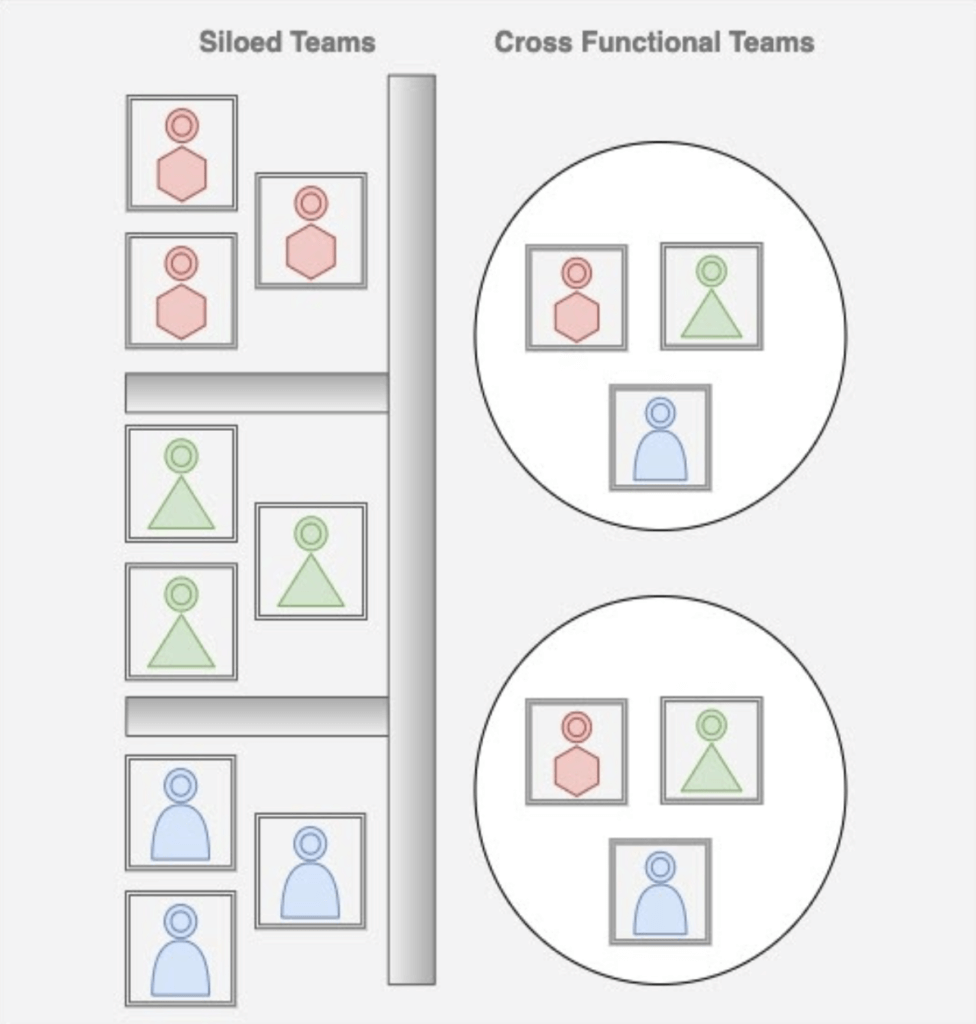
The Adoption of DevOps
Several variants of DevOps started to form including “you build it, you run it” along with forming DevOps teams, which many purists felt was missing the point altogether.
Under the “you build it, you run it” model, developers were left to build pipelines and support the software for which they were responsible. The important controls traditionally enforced by operations teams were discarded and quality suffered as a result.
The team-based approach could work given the right amount of investment and support by the business. The issue was, senior executives did not understand the concept and could not see the justification in the increase in costs to build and maintain deployment pipelines. This coupled with heavy resistance from Operations teams’ (through fear of change), made it difficult to get funding approved for new teams and tooling. As a result, many attempts to build and successfully run centralised DevOps teams failed due to high costs and a low appetite for the increased perceived risk of the new methods used.
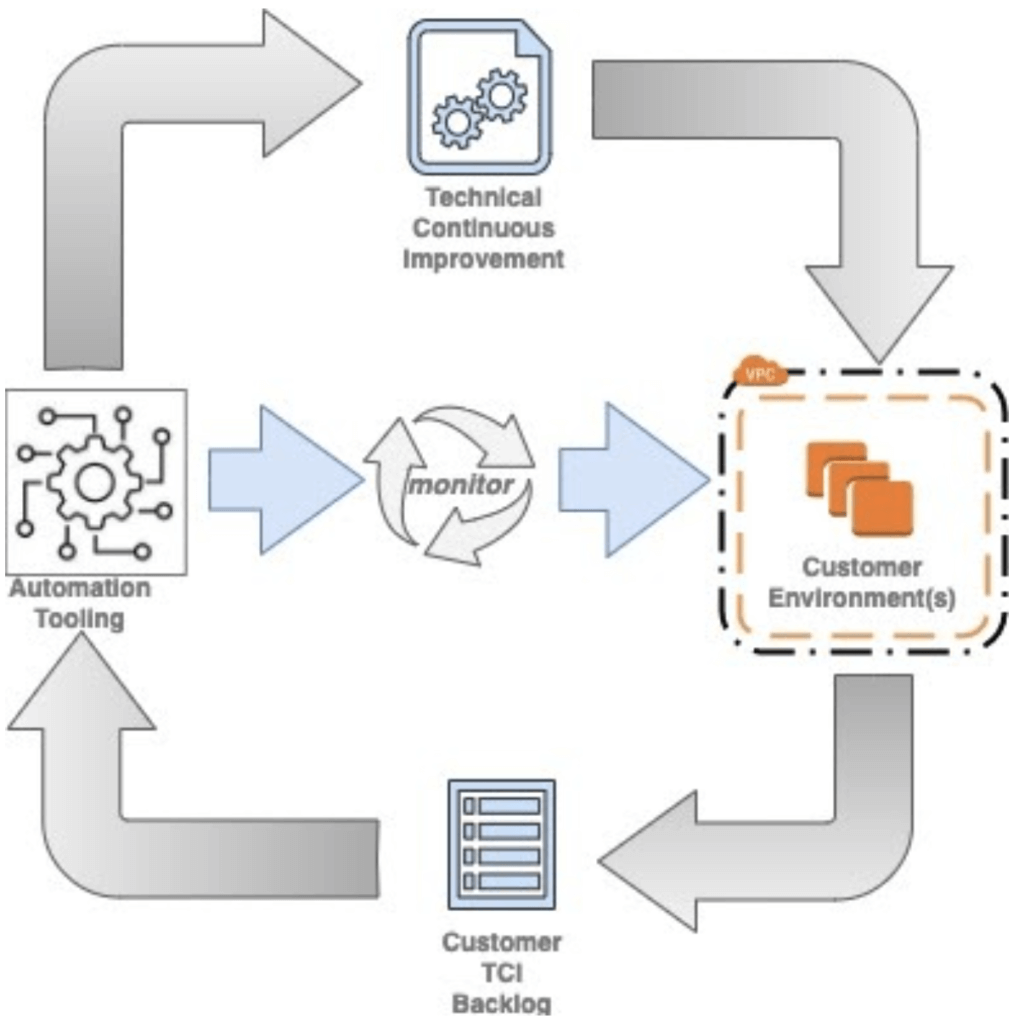
The image below describes how automation plays a major role in rapid prototyping and taking an idea to market in the shortest possible time maintaining quality and control as core priorities in product delivery.
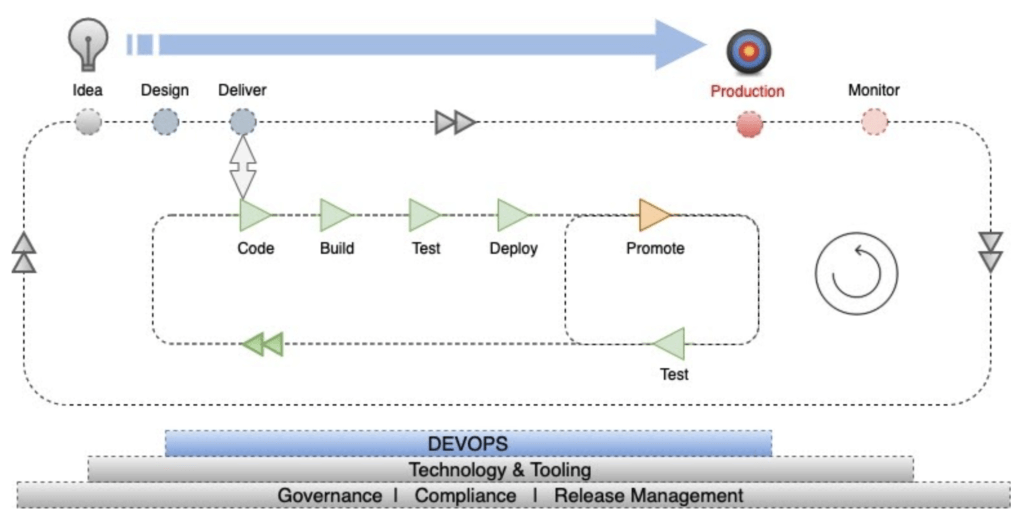
The constant feedback loop in the DevOps Zone ensures that smaller changes are deployed more often. This reduces the risk usually associated with big bang releases in traditional Waterfall style projects. This model applies equally to the delivery of infrastructure or applications to production.
Click Ops to Git Ops – Moving to Everything as Code
Many early variants of cloud hosted support services were based on the Click Ops model. Infrastructure would be provisioned and managed through the Cloud Providers’ web-based console. AWS led the innovation of these user interfaces, developing an integrated platform that centralised the management of core services such as load balancers, DNS and Databases.
As Infrastructure as Code and CI/CD tooling matured, automation became the key factor in the success of implementing a Cloud Hosted DevOps model. Every component of the stack from infrastructure, to applications and environments was driven through version control tools such as Git. This “everything as code” approach was coined “GitOps”.
All the rigour and quality assurance that had been used by software teams was now driving the full stack and supporting tooling. Deployments that would take hours or days could now be achieved in a fraction of the time. Modern deployment methods such as Blue-Green deployments and improved testing through ephemeral environments and Canary testing became commonplace.
The Introduction of the Managed Service Provider
Many businesses could see the value in these modern practices but didn’t have the capital to invest in building these teams and the skillsets required to succeed. Professional Services consultants migrated environments to the Cloud but then moved on when the engagement ended. There was a need for a longer-term strategic partnership between the customer and the Cloud Solution Providers and so began the increase in demand for Managed Service Providers.
A Managed Service engagement is usually a long-term arrangement that can last for an average of 3-5 years. Building and developing a relationship with a customer is key to the success of the engagement. Site Reliability is a base requirement but is not the only component of a Next Generation Managed Service. Continuous improvement is key to ensuring the customers’ environment remains current and aligned with industry best practice through a regular and ongoing review process.
Beyond Support – Moving to a Continuous Improvement Approach
Building and feeding a backlog of improvements and regularly communicating these recommendations to the customer ensures there is an iterative approach to the development and maturity of their environment.
Agreeing and refining a set of non-functional requirements is a critical part of this process, so both parties can measure progress over time against a baseline set of metrics.
Observability is also a critical component of any Managed Service. The ability to proactively detect potential problems before they arise and react to unforeseen events as soon as possible is crucial. Bespoke and third-party solutions can be leveraged to provide this early warning system and allow Site Reliability Engineers time to respond and remediate issues when they arise.
At CMD Solutions, our Cloud Managed DevOps service leverages a team of highly trained Site Reliability Engineers, combined with our bespoke RunCMD tooling, giving our customers an efficient, secure and scalable approach to maintaining and enhancing their AWS environment. Our Managed Service has the added advantage of being able to draw on the wider skills available from our Mantel group partners with specialty skills in Software and Data, AI and Machine Learning. Engineering practice is at the core of our Managed Service, ensuring our customers keep pace with fast paced changes in the Cloud.