3. Amazon Glue for Schema Registry
We can use the fully managed Amazon Glue as the schema registry for MSK clusters. The integration is easy and straightforward. Glue supports all three (JSON, Protobuf, AVRO) schema types. Worthy to mention is, Glue registry has public access enabled, so it is still possible to use the same Glue schema registry for local development with dockerised standalone kafka instance.
Con’s of AWS MSK Serverless
1. Lack of control
As one would expect, serverless comes with limited control compared to the ‘provisioned’ type. We can’t control the number of brokers or which kafka version to be used or system operations like reboots. At the time of writing this article, we are able to create serverless clusters on AWS web console only.
CDK and Cloudformation are not supported yet for serverless cluster type. Although a feature request has been raised and this may get resolved in due time.
2. No public access
Unlike the “provisioned” cluster type, serverless cluster doesn’t offer any public access to kafka service. Only the AWS services which are under the configured VPCs (up to five) allowed access to the serverless cluster. This means, the external applications which want to connect to the cluster will have to do this via an aws bastion proxy. Another option is to use the open source Kafka Rest Proxy by Confluent. This also means any local development environment may have to be content with local dockerised kafka instances (or use a bastion proxy).
3. Lack of library support
MSK Serverless (and Provisioned) use the SASL mechanism of ‘AWS_MSK_IAM’. This is well supported in Java (or any other JVM language) via aws-msk-iam-auth module. But if your services are using a non JVM language, you would most likely be the early adapter and have to do the hard yard of implementing these mechanisms. At the time of writing, there were no GoLang and Python libraries available to connect to MSK serverless using the ‘AWS_MSK_IAM’ mechanism. Although this might most likely change in the future.
4. AWS Console is no “Confluent Control Center”
As its competitors often claim, AWS Serverless is cloud hosted but not cloud native. The web console offers a very simple UI to perform very basic kafka operations. It doesn’t have the complex features of the Confluent control center. You cannot manage the topics. You cannot do on-console KSQL stream processing. You cannot monitor the consumers and producers. The list keeps on growing.
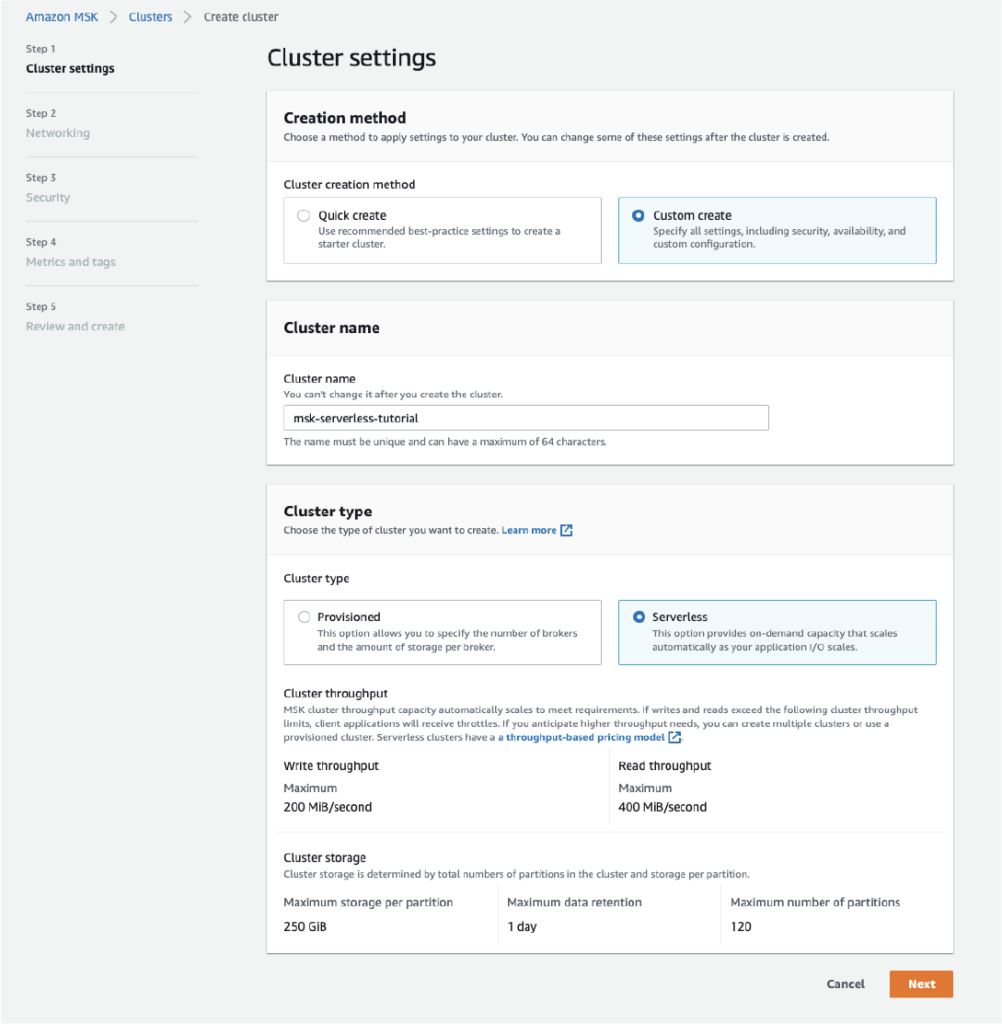
5. Not for high intensity large workloads
Each serverless cluster has a maximum write throughput of up to 200 MiB per second and a maximum read throughput of up to 400 MiB per second. The maximum number of partitions allowed is 120 and data retention is maximum of 1 day. This could be a limitation for very large workloads and high intensity events based use cases.
6. Cost does not scale to zero!
Although the pricing for MSK Serverless is throughput based, it still charges for cluster hours. That means, even when the cluster is idle, we have to pay some amount.
Here’s the pricing breakdown for MSK Serverless (for Asia Pacific Sydney region). This scenario is sourced from the AWS pricing model.
Let’s assume the cluster has 5 topics with 20 partitions each. Daily, your producers write on average 100GB of data and your consumers read 200GB of data. You also retain that data for 24 hours to ensure it is available for replay. In the above scenario, you would pay the following for a 31-day month:

As you can see it would cost at least 700 USD for a month long idle, inactive and empty serverless cluster. Any data and storage cost is proportional to the throughput and this could vary depending on the load.
Conclusion
We recommend MSK Serverless Kafka in the following scenarios:
- For startups, small scale applications which use the Kafka platform.
- For those services with unpredictable varying data load.
- As of now, only JVM applications are best equipped with all the necessary libraries to use MSK Serverless.
- Since the public access is limited, it is recommended for AWS ecosystem only while local development can best utilise the dockerised kafka instances.
- Amazon Glue registry is the preferred managed schema registry for MSK Serverless (and the same registry can be used with local development too).
- Teams will have to provision the cluster manually in the aws console for the time being. Lack of cloudformation support can be a devops hurdle although this could be addressed by AWS duly.
Sample Application
We have developed a small and simple Kotlin spring boot application which connects MSK serverless to produce and consume data for your reference. It also has samples for connecting to the Amazon Glue registry. For local ‘development’ profile, it uses dockerised Confluent Kafka instance.
Here’s the link to the git repository for the project.
