Written by Neil Khatri
In the fast moving world of software development, mastering continuous integration (CI) has become a hugely important part of a developers day to day. CI arms a development team with the ability to automate the build and testing of code with the added knowledge that the code is clean, standardised, secure and reliable. Furthermore, CI can simultaneously offer stakeholders the visibility of real time results and features.
The CI half of CI/CD (Continuous Integration and Continuous Delivery/Deployment) is an ever growing and evolving practice. In this blog we are going to discuss the purpose of CI, look at the features of it in detail, and share our findings around best practices.
Purpose of CI
The primary goal of CI is to detect and address integration issues early in the development process, ensuring that the codebase remains functional and cohesive as it evolves. A CI pipeline is aligned to a project’s source code and there should be one per deployable artefact. As part of the Agile approach to software development, CI is necessary for many reasons:
- Collaboration – Teams need to be able to have various developers working on the same project concurrently, visibility of bugs, do peer reviews, and make changes if needed.
- Continuous feedback – Developers using CI can push their code changes regularly and improve their code based on feedback received. CI will highlight any problems or faults and environment issues for quicker fixes.
- Consistency – All developers integrate their changes using the same process and branching strategy, ensuring a uniform and standardised approach to code integration. This consistency ensures tests are executed in a stable repeatable environment, removing the issues revolving code working on individual machines. Furthermore, it minimises integration conflicts, promotes collaboration, and maintains a coherent codebase across the development team.
- Reduced costs – CI pipelines facilitate a faster and more efficient development process by automating repetitive tasks, enabling developers to focus on business logic and enabling faster and more frequent releases, thus increasing revenue potential. Furthermore, a CI pipeline can detect bugs early on in the development process and improve the code quality leading to reduced maintenance costs and costs on rectifying bugs.
When Does A Pipeline Get Triggered?
CI pipelines should be triggered whenever there is a change to code or configuration that resides under source control. It is meant to verify that the solution is still functioning by executing automated testing, with new features being accompanied by new tests.
There are many ways a CI/CD pipeline can be triggered. You can have it set up to be triggered on every push, every pull request (PR), or even have it scheduled to run at certain intervals (e.g. every week or month). With GitHub Actions for example, there are many options when it comes to triggering a pipeline to run.
You can run pipelines when a PR is opened to run actions like internal build and tests, and another pipeline when a PR is closed for actions like clean-up tasks. These are just a few examples of how pipelines can be triggered, you can see more examples from GitHub Actions.
Brief Outline of CI Steps
In the following sections we will look into the elements of CI in detail, and how they fit into the puzzle. Here is a brief outline of the main steps of continuous integration:
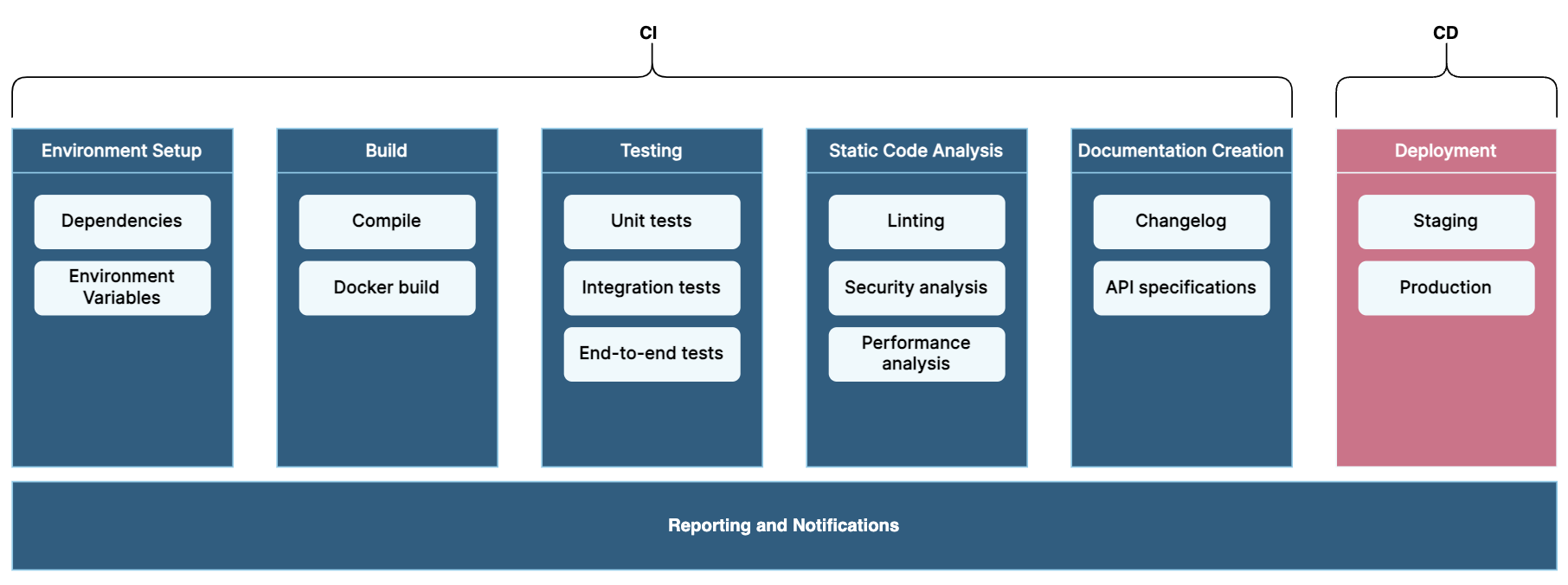
- Environment Setup: To ensure that the following steps in the pipeline have what they need to succeed (e.g. dependencies and environment variables).
- Build: Code needs to be compiled/built to ensure that it can be tested and deployed without errors.
- Testing: To ensure that new tests are being committed along with new code. The purpose of this is to ensure that the new code doesn’t break existing functionality (i.e. regression testing), and to limit the bugs that are released into production.
- Static Code Analysis: To scan the codebase for commonly known errors, vulnerabilities, and security flaws. It’s included to improve code security and enforce coding standards.
- Release Documentation Creation: Involves creating a release page documenting this version’s tag and the changelog, it helps keep a documented backlog of changes made to the repository.
- Reporting and Notifications: Reporting allows the team to identify and analyse trends and notifications enable team members to see results of pipeline in an easier and quicker manner, enabling them to take action quicker.
Deep Dive into CI Steps
1 Environment Setup
Install Dependencies/Packages
Many projects use external libraries, packages, and dependencies in the codebase. We need to install the required dependencies/packages at the beginning of the CI pipeline as steps further down the pipeline such as static code analysis and testing require it. Furthermore, performing this at the beginning helps catch dependency compatibility issues early.
Environment Variables
Environment variables can be database connection strings, API keys, authentication tokens, etc., used for configuration and runtime information for an app. In a CI pipeline, you might define variables that mimic the settings used in various stages of deployment (development, testing, production). These environment variables need to be set at the beginning of the CI pipeline as certain steps further down the pipeline such as testing require these variables to function properly. Furthermore, setting these variables during the CI process increases the likelihood of catching environment-related bugs before getting to the code.
2 Build
Building code is a fundamental step in the CI pipeline. This step would generally generate a build/artefact of your code that can be used for testing and deployment. Each artefact is versioned and tagged in source with the concept being to build once and deploy many. Automating the build in the CI pipeline ensures consistency across development environments, allowing developers to reproduce the same output consistently regardless of their setup.
3 Testing
Testing is essential in any software project as it can detect any potential bugs or errors that exist in your codebase. This is especially important in a CI pipeline as the detection happens before deployment and limits bugs from reaching production. Furthermore, it validates any new features or enhancements and helps ensure that there are no bugs when they are integrated with the rest of the code.
Testing in a CI Pipeline
In a CI pipeline, the way tests are run would depend on the testing frameworks being used and the structure of your project. All the tests could be run under one command or there may be multiple steps within testing to go through smaller and faster tests such as unit tests, and longer tests like end-to-end tests or integration tests. Parallel testing can also be set up in the pipeline to speed up the total testing time.
The types of tests that can be run in a CI pipeline, pre-deployment, can be limited based on the project. For example, in a backend project, only unit tests and certain integration tests can be tested before deployment, end-to-end testing and black box testing would often occur post-deployment. On the other hand, for a frontend project, the CI pipeline can include unit tests, snapshot testing, and end-to-end tests in the CI pipeline.
To support integration within a CI process and mimic deployment environments effectively, it’s beneficial to utilise mocks and stubs. Incorporating stubs or mocks enable the simulation of dependencies and external systems, contributing to comprehensive test coverage and streamlining the testing process without requiring actual deployment.
Test Coverage
Test coverage is one of the important aspects of testing, it helps us understand how well our code is tested in certain aspects by measuring the proportion of statements, branches and functions tested in our codebase. Test coverage reports produced in a CI pipeline help standardise a team’s measurement of testing. Pull requests can be blocked until a minimum percentage threshold of statements, branches and other metrics is met.
Having test coverage also allows developers to assess the potential impact of their code changes on other parts of the project or application as changes may introduce new edge cases that are not being tested, thus helping identify potential bugs or side effects. However, test coverage alone does not guarantee the quality of testing, only that execution parts have been covered. There may be logical test scenarios or edge cases that are not present in a 100% covered codebase. Nonetheless, test coverage reports are important and helpful, but they should not be the sole point of reasoning for a well-tested codebase.
4 Static Code Analysis
Linting
Linting your source code is to analyse for potential errors, bugs, and stylistic issues that may not be caught by the compiler or developer. More importantly, linting can pick up on code smells, which are certain patterns or structures that may indicate potential issues in terms of maintainability, readability and extensibility. Some examples of code smells that linting can help flag and mitigate are long methods or functions, excessive nesting and complex conditionals, and duplicated code. Linting can also enforce coding conventions by identifying issues related to formatting, naming conventions, and other style-related matters.
Security Testing
Security analysis identifies security vulnerabilities in the code, such as potential buffer overflows, SQL injection, cross-site scripting (XSS), and other common security issues. Vulnerability checking includes the scanning of code we own and the project dependencies. We include this in our CI pipeline because security vulnerabilities can lead to data breaches, unauthorised access, and other security threats.
Code Quality Analysis
Code complexity analysis plays a critical role in assessing code quality through metrics such as cyclomatic complexity and code duplication. High code complexity can lead to errors, difficulties in debugging, and challenges in extending the codebase. By striving for high cohesion and low coupling within the codebase, complexity can be mitigated. Low code complexity and good code quality can result in simplification, refactoring, or better documentation, making code more maintainable and robust software.
Performance Analysis
Performance analysis identifies potential performance bottlenecks and inefficiencies in the code. It looks for resource-intensive operations, inefficient algorithms, and memory-related issues. We try to conduct performance analysis as performance issues can lead to slow software, poor user experience, and resource exhaustion.
5 Release Documentation Creation
Release documentation creation is a “nice-to-have” step in a CI pipeline. Integrating this functionality into your pipeline streamlines the process of generating documentation for software releases. Release documentation would typically consist of release notes for any new changes, a changelog including bug fixes, feature additions and code modifications, versioning and more. Having release documentation in your project helps all stakeholders be more aware of the changes in the software and it keeps a documented backlog of your repository so that you can go back and see all the changes that were made at any time.
Additionally, if your team is developing a public REST API, then this step can also involve publishing public APIs. Tools can be integrated into your pipeline to generate OpenAPI specifications from your code or read your specification file in YAML or JSON, and update the API specifications.
6 Reporting and Notifications
Reporting and notifications is another “nice-to-have” step in a CI pipeline, it helps keep the development team informed about the progress of the pipeline and any issues that arise.
Reporting in a CI pipeline involves generating and presenting various types of information related to the previous steps in the CI pipeline. This information helps the development team and stakeholders understand the current state of the codebase and its quality. For testing we can report on the outcomes of the tests such as pass/fail status and any associated errors, along with the code coverage results. Reports on the code quality and potential issues can also be generated with the results from the static code analysis. Having reporting set up in your pipeline is also important when it comes to identifying trends in the codebase over time, such as the change in test coverage and code quality.
Notifications involve informing relevant team members about the status and results of the CI pipeline. Notifications can be sent via various communication channels, such as Slack, email, or any other messaging platforms. We can have notifications for build failures, test outcomes (e.g. pass/fail) and test coverage, static code analysis results, and the release documentation results.
Conclusion
In conclusion, CI stands as a cornerstone of modern software development, fostering collaboration, ensuring code quality, and enabling faster development cycles. By automating integration processes and emphasising robust testing methodologies, CI plays an instrumental role in delivering reliable, high-quality software while aligning with Agile principles and industry best practices.
In this blog, we have discussed six major components of a CI pipeline, yet not everything listed in this blog needs to be included in your CI pipeline. Furthermore, there are additional steps and tasks that can be included in your pipeline, such as publishing shared artefacts to a repository. A CI pipeline should be designed and implemented to align with the specific needs and requirements of a project’s source code, meaning this blog may not include everything that should be included in your pipeline, and may also include steps or tasks that do not need to be included in your pipeline.
Stay tuned for future blog posts going into detail on the tools and technologies used in CI pipelines with different languages
