
What is a Data Platform?
A Data Platform is a unified architecture designed to ingest, store, process, and analyse data from across an organisation. By consolidating fragmented data into a single, scalable environment, it eliminates data silos and serves as the foundation for data-driven decision-making.
Why modern businesses need a data platform
A robust data platform does more than store information; it transforms raw data into a competitive asset through:
-
Centralised Management: Integrates databases, data lakes, and warehouses to ensure data consistency and high-quality governance.
-
Advanced Analytics: Powers high-level capabilities including Business Intelligence (BI), Machine Learning, and Predictive Analytics.
-
Real-Time Insights: Connects with IoT devices and social media to provide a holistic, live view of market dynamics and customer behaviour.
-
Cloud Scalability: Modern platforms offer cost-effective, “pay-as-you-go” growth with minimal operational overhead.
Data platform services provide the visibility and technical certainty needed to turn complex data into a positive ROI.
Types of data platforms
On-premise vs. Cloud-based data platforms
On-premise data platforms are deployed within an organisation’s local infrastructure, providing control over hardware, software, and data storage. Control over these components, however, comes with increased responsibility for maintenance, updates, and security measures. In contrast, cloud-based data platforms rely on third-party cloud service providers for infrastructure and services. These platforms offer advantages like scalability, reduced upfront costs, and lower operational overhead, but may introduce concerns related to data privacy and dependency on the service provider.
Open-source vs. Proprietary data platforms
Open-source data platforms are built using publicly available source code, granting users the freedom to modify, redistribute, and contribute to the platform’s development. This collaborative approach often results in rapid innovation, a vast support community, and reduced licensing costs. Proprietary data platforms, on the other hand, are owned and maintained by private companies, offering a more polished and supported product with dedicated customer service. However, these benefits may come at the expense of higher costs, limited customisation options, and potential vendor lock-in.
Vertical vs. Horizontal data platforms
Vertical data platforms are tailored to address the specific needs of a particular industry or business domain, such as healthcare, finance, or retail. These specialised platforms provide industry-specific data models, analytics capabilities, and integrations, enabling organisations to derive insights relevant to their domain. In contrast, horizontal data platforms are designed to be versatile and applicable across various industries, focusing on delivering a comprehensive suite of data management, processing, and analytics tools. While horizontal platforms offer more flexibility, they may require additional customisation and configuration to meet unique industry requirements.
Types of data platforms summary:
| Category | Type | Primary Focus | Key Advantages | Potential Drawbacks |
| Deployment | On-Premise | Local Infrastructure | Full control over hardware, software, and data security. | High maintenance; responsible for all updates and scaling. |
| Cloud-Based | Third-party Infrastructure | High scalability; lower upfront costs; reduced operational overhead. | Privacy concerns; dependency on the specific cloud provider. | |
| Source & Licensing | Open-Source | Community-Driven Code | Rapid innovation; no licensing fees; high customization. | Requires internal expertise; community-reliant support. |
| Proprietary | Vendor-Owned Product | Polished UI; dedicated customer support; “out-of-the-box” readiness. | Higher costs; potential vendor lock-in; limited customization. | |
| Industry Scope | Vertical | Industry-Specific (e.g., Health) | Tailored data models and analytics for specific sectors. | Less flexible if business needs expand outside that niche. |
| Horizontal | General Purpose | Versatile; applicable across any industry or business domain. | May require significant configuration to meet specific industry needs. |
What are the advantages of a data platform?
Data platforms provide several key advantages for organisations, including data integration and consolidation, scalability and performance, enhanced data analytics and insights, improved collaboration and data sharing, and data security and compliance.
By offering a comprehensive solution that addresses these critical aspects of data management and analysis, data platforms empower businesses to harness the full potential of their data, make more informed decisions, and remain competitive in an increasingly data-driven world.
Data integration and consolidation
Data platforms enable organisations to integrate and consolidate data from disparate sources, such as databases, APIs, IoT devices, and web scraping. By bringing this data together, businesses can create a unified, holistic view of their operations, making it easier to identify patterns, trends, and potential areas for improvement. This consolidated data repository also simplifies the process of data management and helps maintain data quality across the organisation.
Scalability and performance
Modern data platforms are built to handle the increasing volume, velocity, and variety of data generated by today’s businesses. With features like horizontal scaling, distributed processing, and real-time analytics, these platforms can efficiently manage large datasets and deliver insights at the speed required for informed decision-making. This scalability and performance optimisation not only keeps pace with growing data needs but also ensures that businesses can adapt to new data sources and technologies as they emerge.
Enhanced data analytics and insights
Data platforms offer advanced analytics capabilities, including machine learning, natural language processing, and graph processing, which enable organisations to derive actionable insights from their data. These advanced analytics tools can be used to develop predictive models, identify trends, optimise operations, and uncover hidden relationships within the data. By leveraging these insights, businesses can make more informed decisions, innovate, and stay competitive in their respective industries.
Improved collaboration and data sharing
By centralising data storage and providing a unified platform for data processing and analysis, data platforms facilitate collaboration and data sharing among different teams within an organisation. This improved collaboration allows teams to work together on projects more efficiently, fosters a data-driven culture, and ensures that everyone has access to the most up-to-date and accurate data for decision-making.
Data security and compliance
Data platforms often come with built-in security measures, such as encryption, access control, and data loss prevention, to protect sensitive information from unauthorised access and misuse. Additionally, many platforms offer tools for data governance and compliance, helping organisations manage their data in accordance with industry-specific regulations and guidelines. These security and compliance features not only safeguard an organisation’s data but also build trust with customers, partners, and stakeholders.
Data platform layers
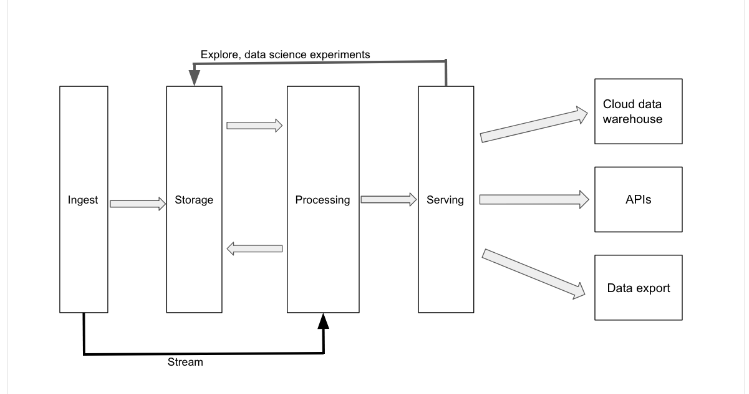
Data platform layers refer to the various stages and components within a data platform architecture, designed to handle and process data efficiently. These layers typically work together to ingest, store, process, analyse, and serve data to users and applications.
While there is some dispute between individual layer differentiation, the five main data platform layers are comprised of the;
- Data ingestion layer
- Data storage layer
- Data processing layer
- Data analytics layer
- Data serving and visualisation layer
Data ingestion layer
The data ingestion layer is a crucial component of any data platform, encompassing the subcomponents data extraction, data transformation, and data loading. It handles data from various sources, including databases, files, APIs, and web services, requiring both structured and unstructured data for comprehensive analysis down the line. Data transformation processes raw data into a suitable format, enhancing its quality and usability. Data loading transfers transformed data into the storage layer using batch loading for bulk processing at predetermined intervals or real-time loading for continuous data ingestion. Efficient data ingestion sets the stage for subsequent processing, analysis, and visualisation tasks.
Data storage layer
Once ingested, data is stored in the data storage layer, which comprises various types of databases and data lakes. Relational databases, NoSQL databases, columnar databases, and time-series databases are some of the common storage solutions used for structured and semi-structured data. Data lakes, on the other hand, store vast amounts of raw, unprocessed data, including structured, semi-structured, and unstructured data, allowing for flexible and scalable storage solutions.
Data processing layer
The data processing layer handles the transformation, aggregation, and analysis of the stored data. This layer includes batch processing frameworks for processing large volumes of data in batches, and stream processing frameworks for real-time processing of data streams. Data transformation tools are also employed to manipulate and prepare the data for further analysis, while data integration and orchestration tools manage the flow and dependencies of data processing tasks.
Data analytics layer
The data analytics layer focuses on extracting insights and generating predictions from the processed data. Analytical databases enable fast querying and reporting, while machine learning frameworks facilitate the development and deployment of predictive models. Data analytics libraries, natural language processing libraries, and graph processing libraries provide additional capabilities for advanced analysis and insight extraction.
Data serving and visualisation layer
Finally, the serving and visualisation layer presents the insights derived from the data in a visually appealing and easily digestible format. Data visualisation tools help create interactive charts, graphs, and dashboards, while reporting tools generate detailed reports for various business stakeholders. Geospatial analysis tools can also be employed to visualise and analyse location-based data, enhancing the understanding of spatial relationships and patterns.
How to build a data platform
Building a data platform involves several key steps to ensure its effectiveness, scalability, and performance.
-
Defining Business Objectives: Identifying key goals and KPIs to ensure the platform delivers tangible ROI.
-
Choosing the Right Technology Stack: Selecting the optimal mix of cloud providers, warehouses, and processing frameworks.
-
Designing the Data Architecture: Mapping out the flow of data from source to consumption to ensure scalability.
-
Implementing Data Ingestion and Processing: Building the pipelines that move and transform raw data into usable formats.
-
Ensuring Data Quality: Establishing validation rules and cleansing processes to maintain a “single source of truth.”
-
Providing Data Analytics and Visualisation Tools: Deploying the interface (like PowerBI or Tableau) where stakeholders gain insights.
-
Implementing Security and Compliance Measures: Hardening the platform to meet regulatory standards like GDPR or APRA.
Defining business objectives
Defining business objectives is the first step in building a data platform. Business objectives are important because they guide the data platform’s development and help stakeholders understand its purpose. By identifying specific goals and outcomes, the platform can be tailored to meet the organisation’s unique needs, ensuring that it delivers valuable insights. Examples of viable business objectives may include improving customer targeting, optimising supply chain operations, or enhancing product development.
Choosing the right technology stack
Choosing the right technology stack is crucial for building a robust and scalable data platform. The technology stack comprises the collection of software, tools, and frameworks that support the platform’s functionality. Key components of the stack include data storage solutions (e.g., relational databases, NoSQL databases, data warehouses), data processing frameworks (e.g., Apache Hadoop, Apache Spark, Google Dataflow), and data integration tools (e.g., Apache Nifi, Talend, Informatica).
When selecting the stack, consider factors such as cost, ease of use, scalability, and compatibility with existing systems. Conduct a thorough evaluation of available technologies, considering factors such as vendor support, community engagement, and future development plans. A well-chosen stack ensures the platform can handle future growth and adapt to new technologies as they emerge.
Designing the data architecture
Designing the data architecture involves organising and structuring data to facilitate efficient storage, retrieval, and processing. A well-designed data architecture is the foundation upon which the entire data platform is built. It enables seamless integration between data sources, supports data processing pipelines, and promotes data consistency and accessibility.
Key aspects of data architecture include data modelling (defining the structure and relationships between data elements), data storage (determining how and where data is stored), and data processing (specifying how data is transformed and enriched).
To design an effective data architecture, consider the organisation’s unique requirements, data types, and data sources, while also planning for future growth and evolving needs. This definitely isn’t a one-man job – ensure that the product owner collaborates with cross-functional teams, including data engineers, data scientists, and business analysts, to certify that the data platform architecture meets the diverse needs of various stakeholders.
Implementing data ingestion and processing
Implementing data ingestion and processing refers to the methods used to collect, store, and transform raw data into usable information. This step involves creating data pipelines, which are responsible for extracting data from various sources (e.g., APIs, databases, files), transforming it to meet specific requirements (e.g., aggregating, filtering, enriching), and loading it into the data platform.
Data pipelines should be designed to handle different data formats, volumes, and velocities, ensuring that they can accommodate the organisation’s evolving data landscape. Efficient data pipelines ensure that data is readily available for analysis and decision-making, minimising latency and delivering timely insights.
Ensuring data quality
Ensuring data quality is essential for the success of a data platform. Data quality refers to the accuracy, completeness, and consistency of the data stored in the platform. Poor data quality can lead to incorrect insights and faulty decision-making, undermining the platform’s value.
To maintain high data quality, implement data validation, cleansing, and monitoring processes throughout the data pipeline.
Data validation involves checking for inconsistencies, errors, and anomalies in the data; data cleansing involves correcting, updating, or removing inaccurate or incomplete data; and data monitoring involves tracking data quality metrics over time, identifying trends and potential issues.
Providing data analytics and visualisation tools
Offering data analytics and visualisation tools is essential for enabling users to extract valuable insights from the data platform. These tools empower users to explore, analyse, and visualise data in meaningful ways, making it easier to identify trends, patterns, and relationships that inform decision-making.
To cater to a wide range of user needs and preferences, provide a diverse set of analytics tools, such as SQL-based query engines, machine learning libraries, and statistical analysis software.
Additionally, offer user-friendly visualisation tools that support various chart types, interactive dashboards, and custom reporting options. By equipping users with powerful analytics and visualisation capabilities, the data platform becomes an indispensable resource for data-driven insights and strategic planning.
Implementing security and compliance measures
Implementing security and compliance measures is vital for protecting the data platform and the valuable information it contains. This step involves establishing access controls, encryption methods, and auditing processes to safeguard data and ensure compliance with relevant regulations. A secure and compliant data platform fosters trust and confidence among stakeholders and end-users.
Use cases of a data platform
Data platforms have a wide range of use cases across various industries and organisations, enabling them to derive insights and make data-driven decisions. Some common use cases include;
- Supply chain optimisation
- Fraud detection
- Predictive maintenance
- Product recommendations
Supply chain optimisation
Supply chain optimisation is a critical use case for data platforms that enables organisations to enhance their end-to-end supply chain processes’ efficiency (and effectiveness). Efficiency improvements come from integrating and analysing data from various sources, such as suppliers, manufacturers, distributors, retailers, and customers. Analysing data from these sources allows organisations to gain comprehensive insights into their supply chain operations.
These insights help identify inefficiencies, bottlenecks, and areas of improvement in procurement, production, inventory management, transportation, and distribution.
Supplier selection
For instance, procurement improvements can be achieved by using data platforms to identify the best suppliers based on factors like lead time, quality, and cost. Identifying the best supplier ultimately leads to streamlined production processes, which data platforms support by analysing production data to find efficient manufacturing schedules, resource allocations, and equipment utilisation.
Manufacturing optimisation
Efficient manufacturing schedules are closely related to inventory management optimisation, where data platforms analyse demand forecasts, lead times, and stock levels. Analysing these factors helps determine optimal inventory levels and safety stock requirements, enabling organisations to balance their inventory. Striking the right inventory balance prevents carrying excessive inventory, which can cause increased carrying costs and obsolescence, as well as avoiding insufficient inventory, which can lead to stockouts and lost sales.
Avoiding stock outs is essential in transportation and distribution, where data platforms optimise logistics operations by analysing factors such as shipping costs, transit times, and route efficiency. Analysing these factors results in reduced transportation costs, improved on-time delivery performance, and increased customer satisfaction, all of which contribute to a more streamlined and effective supply chain.
Product recommendations
Product recommendations are a widely used application of data platforms in the retail and e-commerce sectors. By analysing customer preferences, browsing history, and purchase patterns, data platforms can generate personalised product recommendations that cater to individual tastes and needs. These personalised recommendations can drive customer engagement, increase sales, and enhance customer loyalty, contributing to the overall success of the organisation.
Workforce Analytics
Workforce analytics is a valuable use case for data platforms that helps organisations optimise their human resources management. Organisations achieve this optimisation by deriving insights from employee-related data. Employee-related data includes factors such as performance, demographics, and engagement, which businesses analyse to understand productivity, satisfaction, and retention patterns. These patterns reveal crucial information about talent acquisition strategies.
Talent development
Talent acquisition strategies can be improved by using data platforms to identify and target the most suitable candidates based on their skills, qualifications, and experience. Improved hiring outcomes reduce time and cost associated with talent acquisition. Talent acquisition is closely related to employee development, another critical area where workforce analytics plays a vital role.
Employee development involves identifying skill gaps and opportunities for employee growth. Data platforms analyse information related to employee performance, learning patterns, and career progression to create personalised development plans and training programs. These development plans and training programs cater to individual needs and aspirations, which in turn improve employee engagement and enhance skill sets.
Performance management
Enhanced skill sets contribute to career satisfaction, which directly affects performance management, another essential aspect of workforce analytics. Performance management is improved by examining data on individual and team performance, enabling organisations to develop data-driven performance evaluations and compensation strategies. Compensation strategies ensure that employees are rewarded fairly and consistently based on their contributions, leading to increased employee morale.
Additionally, workforce analytics helps organisations identify and address factors contributing to employee turnover by analysing data on employee satisfaction, engagement, and exit interviews. Exit interviews pinpoint the root causes of employee attrition, which allows businesses to implement targeted retention strategies.
Fraud Detection
Fraud detection is a crucial use case for data platforms, particularly in the finance and e-commerce sectors. By analysing transaction data and user behaviour, data platforms can identify patterns and anomalies that may indicate fraudulent activity.
Advanced analytics techniques, such as machine learning and artificial intelligence, can be employed to enhance the accuracy of fraud detection systems. Implementing a robust fraud detection solution can protect businesses and customers from financial losses and maintain trust in the organisation.
Predictive Maintenance
Predictive maintenance is a highly valuable use case for data platforms in industries that heavily depend on machinery or equipment, including manufacturing, transportation, and energy sectors. Industries such as these benefit from collecting and analysing sensor data generated by their equipment. Analysing sensor data enables organisations to foresee when machinery is likely to fail, which is essential for proactively scheduling maintenance activities.
Proactive Maintenance Scheduling
Proactive maintenance scheduling, made possible by leveraging data platforms, significantly reduces equipment downtime, which is crucial for maintaining operational efficiency. Reduced downtime also contributes to extending the life of equipment, ensuring that businesses can derive maximum value from their machinery investments. Furthermore, predictive maintenance allows organisations to optimise their maintenance budgets by minimising the frequency of unexpected equipment breakdowns.
The minimised breakdown frequency results in reduced overall maintenance costs, as organisations can avoid costly reactive repairs and focus on cost-effective preventive maintenance strategies. These strategies, powered by data-driven insights, not only enhance the operational performance of machinery but also contribute to improved safety standards, as potential hazards and risks associated with equipment failure are identified and addressed before they escalate.
Choosing the right data platform for your business
Selecting the ideal data platform for your organisation is crucial to unlocking the full potential of your data and driving better decision-making. When comparing data platforms such as Databricks, Snowflake, and Google BigQuery, it’s important to consider various factors, such as your business requirements, data types, and scalability needs. In the following sections, we’ll explore these three popular data platforms in more detail to help you make an informed choice.
Databricks
Databricks is a unified analytics platform that combines data engineering, data science, and machine learning capabilities. It is built on top of Apache Spark, a powerful open-source processing engine designed for big data and analytics workloads. Databricks excels in handling large-scale data processing tasks, making it a suitable choice for organisations with complex data pipelines and advanced analytics requirements.
The Databricks platform provides seamless data integration, allowing you to ingest data from various sources, such as databases, APIs, and IoT devices. Its collaborative notebooks enable data scientists and engineers to work together efficiently, while the platform’s support for multiple programming languages, including Python, R, Scala, and SQL, caters to diverse skill sets within your organisation.
Snowflake
Snowflake is a cloud-based data platform that focuses on structured and semi-structured data, making it a strong option for organisations with a need for data warehousing and analytics. Its innovative architecture separates storage and compute resources, allowing for greater flexibility and scalability. This means you can independently scale storage and compute resources based on your specific needs, which can lead to cost savings and improved performance.
Snowflake’s platform offers seamless data integration, allowing you to ingest data from various sources easily. Its support for SQL enables analysts and data scientists to query data using familiar syntax, while the platform’s native support for JSON and semi-structured data simplifies working with diverse data types.
Google BigQuery
Google BigQuery is a fully-managed, serverless data warehouse designed for large-scale data warehousing and analytics. It is part of the Google Cloud Platform and benefits from Google’s extensive cloud infrastructure and expertise. BigQuery enables super-fast SQL queries and real-time data analysis, making it an excellent choice for organisations that require real-time insights and need to process massive volumes of data.
BigQuery offers seamless data integration and supports various data formats, including CSV, JSON, and Avro. Its serverless architecture means there’s no need to manage any infrastructure, allowing your team to focus on data analysis and insights. Additionally, BigQuery’s integration with other Google Cloud services, such as Google Data Studio, makes it easy to create comprehensive data visualisations and dashboards.
In conclusion, choosing the right data platform for your business involves understanding your data needs, evaluating platform features, and assessing the vendor ecosystem. By carefully considering platforms like Databricks, Snowflake, and Google BigQuery, your organisation can select a data platform that best meets its requirements and unlocks the full potential of its data, driving informed decision-making and business growth.
| Metrics |  |
 |
 |
| Focus | Big data and analytics workloads | Data warehousing and analytics | Large-scale data warehousing and analytics |
| Data Types
|
Structured, semi-structured, unstructured | Structured and semi-structured | Structured, semi-structured, unstructured |
| Architecture
|
Apache Spark-based | Unique architecture separating storage and compute | Serverless architecture |
| Data Integration
|
Seamless integration with various sources | Seamless integration with various sources | Seamless integration with various sources and formats |
| Query Language
|
Python, R, Scala, SQL | SQL | SQL |
| Data Processing Capabilities
|
Large-scale data processing | Flexible and scalable data processing | Real-time data analysis, massive data processing |
| Collaboration Features
|
Collaborative notebooks | N/A | N/A |
| Scalability
|
Highly scalable | Independent scaling of storage and compute | Highly scalable, serverless |
| Ecosystem
|
Strong presence in Apache Spark community | Rapidly growing popularity, unique architecture | Google Cloud infrastructure, expertise |
| Integration with Visualisation Tools
|
Compatible with various visualisation tools | Compatible with various visualisation tools | Integrated with Google Data Studio |
Challenges of implementing a data platform
Implementing a data platform presents various challenges that organisations must overcome for a successful implementation. In this section, we’ll discuss examples of things that commonly go wrong during data platform implementation, adhering closely to the linking principle for a clearer understanding of these challenges.
Poor data integration and management
Inadequate data integration and management is a common issue during data platform implementation, leading to data silos and inconsistencies. Data silos and inconsistencies can impede organisations from gaining accurate insights and making informed decisions. To address this challenge, organisations must invest in robust data integration tools such as ETL processes, data pipelines, and APIs. By using these tools, they can ensure data consistency and accessibility across the organisation. Ensuring data consistency is crucial for maintaining a comprehensive understanding of operations, which can be achieved by establishing a comprehensive data governance strategy.
No future-proofing
Insufficient scalability resulting from a lack of planning ahead is another common pitfall that organisations face during data platform implementation. This occurs when organisations fail to plan for growing data volumes or choose a platform that lacks flexibility. A lack of flexibility in the platform can lead to performance bottlenecks and resource constraints. To avoid these issues, organisations should opt for a data platform with flexible scaling options, such as cloud-based solutions. Cloud-based solutions can automatically adjust resources based on demand, ensuring optimal performance as data volumes grow. Maintaining optimal performance requires regular monitoring of performance metrics and proactive bottleneck resolution.
Inadequate security measures
Inadequate security and compliance measures are a frequent challenge in data platform implementation, leading to data breaches and potential legal consequences. Data breaches occur when organisations fail to properly protect sensitive data or adhere to regulatory requirements. To mitigate this risk, organisations must establish a comprehensive data security strategy that includes encryption, access control, and auditing. Implementing these security measures can help protect sensitive data, and staying up-to-date with regulatory requirements is crucial for maintaining compliance. Maintaining compliance involves implementing measures such as data anonymisation and strict data retention policies.
Insufficient data-engineering talent
Insufficient training and skill development is a challenge that organisations face during data platform implementation, resulting in a workforce that cannot effectively leverage the platform’s capabilities. The inability to leverage the platform’s capabilities can hinder an organisation’s ability to gain insights and negatively impact data-driven decision-making processes. To address this issue, organisations should invest in training their workforce in areas such as data analysis, data engineering, and data science. Training in these areas enables employees to effectively use the platform and promotes a culture of continuous learning. Encouraging continuous learning and providing access to resources can help employees stay current with emerging technologies and best practices, ensuring a successful data platform implementation.
Successful implementation – an example
Despite the many challenges that accompany an ambitious data project, when done correctly the benefits to the bottom line can be enormous. The ability to make continuous data driven decisions, save significant time and operational labour, and determine effective strategies for increasing customer acquisition and retention cannot be understated.
Case Study: Liven
Challenges
As Liven prepared for a Series B funding round, the startup encountered tech debt and data reconciliation issues stemming from their use of multiple platforms and tools, such as PostgreSQL, Stitch, and Amazon Kinesis. This patchwork of tools led to data reliability problems, making it difficult to ensure data consistency and accuracy. Additionally, extracting data was a complex and labour-intensive process, with internal teams needing the data team’s assistance to access and understand the data.
Solution
Liven collaborated with Cuusoo (an Aginic partner) to implement the Databricks Lakehouse platform, which would consolidate their data into one unified platform. Cuusoo offered hands-on coaching, created detailed documentation, and recorded training videos to help Liven’s team understand the new platform. They also guided Liven in building a well-structured framework for data management, making it easier to add new data sources without extensive coding. The entire implementation process was completed within 100 working days, allowing Liven to meet their Series B deadline.
Results
By consolidating their data onto the Databricks Lakehouse platform, Liven simplified and unified their data management processes, leading to a significant increase in user adoption from 24% to 65%. Liven’s lean data team was now able to handle 10 times the data volume without needing to expand, thanks to the platform’s efficient design. The platform also made it easier for internal teams and external customers to access and analyse data, leading to more informed decision-making. This streamlined data management approach resulted in an estimated $1 million in total savings and efficiencies, with the data team gaining more time to focus on strategic initiatives.
