Running a CI/CD platform using your own runners can be daunting. Not from an implementation perspective, but more so from a scaling perspective.
You may be asking, “How will our platform create new runners/workers in response to a pipeline being run?”
Scaling
If scaling is not appropriately managed, pipeline jobs may be held up in a queue, which delays their execution, and results in non-productive developer time. Scaling can be a difficult task. After following an install guide, the choice to scale out can be subjective.
Depending on the CI/CD Platform, typically the choices are:
- Using the SaaS option
- Installing an Agent to a server
- Pulling a container from a container registry (DockerHub/ECR) with the Agent already setup
Either of these options can be scaled, however, the difficulty is usually deciding what metric you scale it on. When using CI/CD, you may have the option to use a Webhook as a trigger to scale out runners, and although it is a perfectly capable option, you will need to build custom logic behind the scaling.
An ingress point will need to be present for the Webhook, which will then need to be passed to a Webhook server or a worker/runner that will then start-up based on invocation.
Within AWS the solution may resemble something like this:
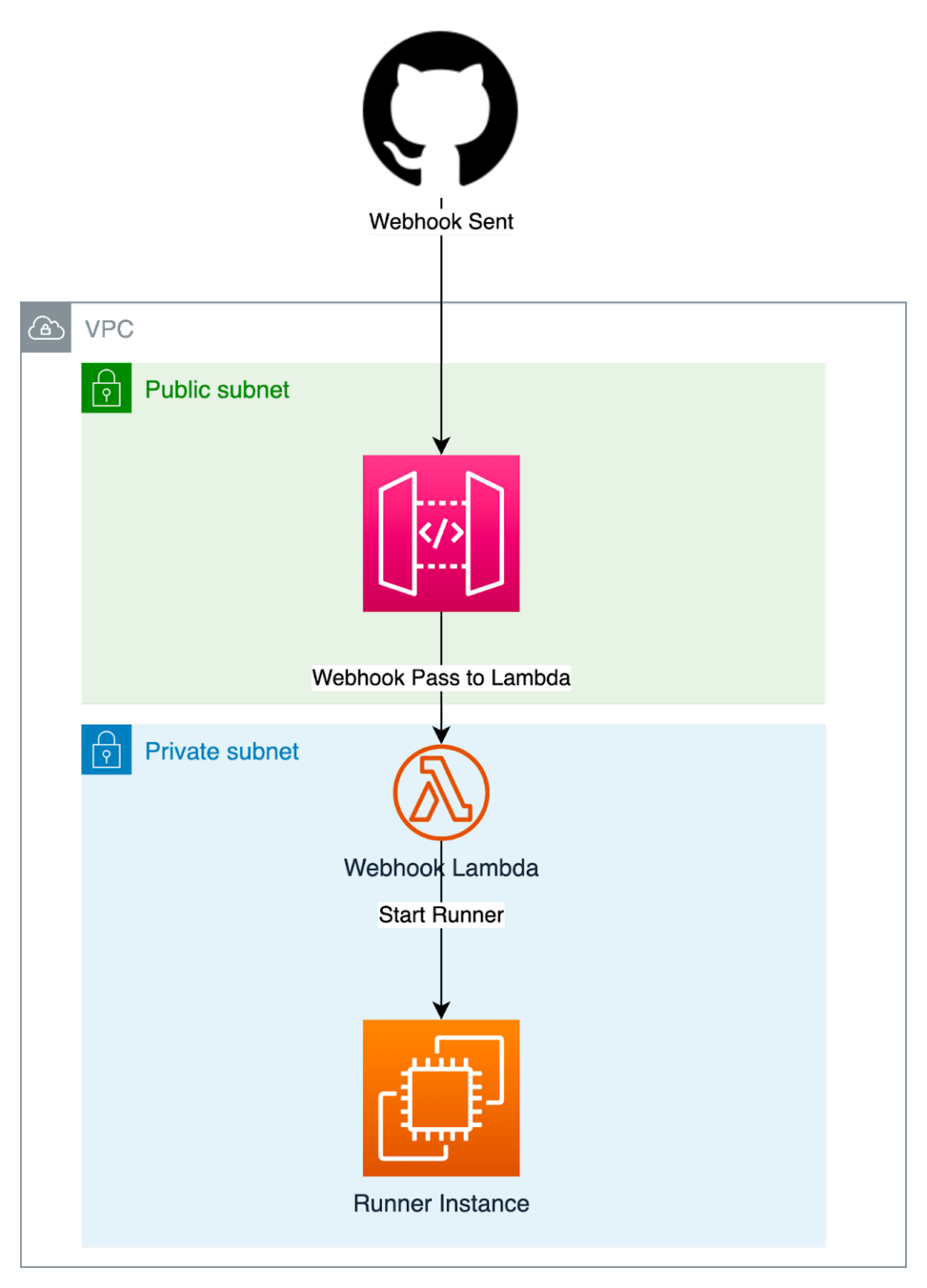
At first glance this seems simple:
- API Gateway for ingress.
- Lambda function to launch runner via EC2 API.
However, when dealing with EC2, costs can add up if Runners are Orphaned/Left Running.
To deal with these Orphaned runners, another Lambda function was added CleanUpRunnerLambda. To deal with long-running “Stuck” runners, TimedOutStaleRunnerLambda was created. Plus, an additional 3 lambda Lambdas were made to deal with potential costly LONG running instance costs and general runner failure. The overall upkeep is starting to add up.

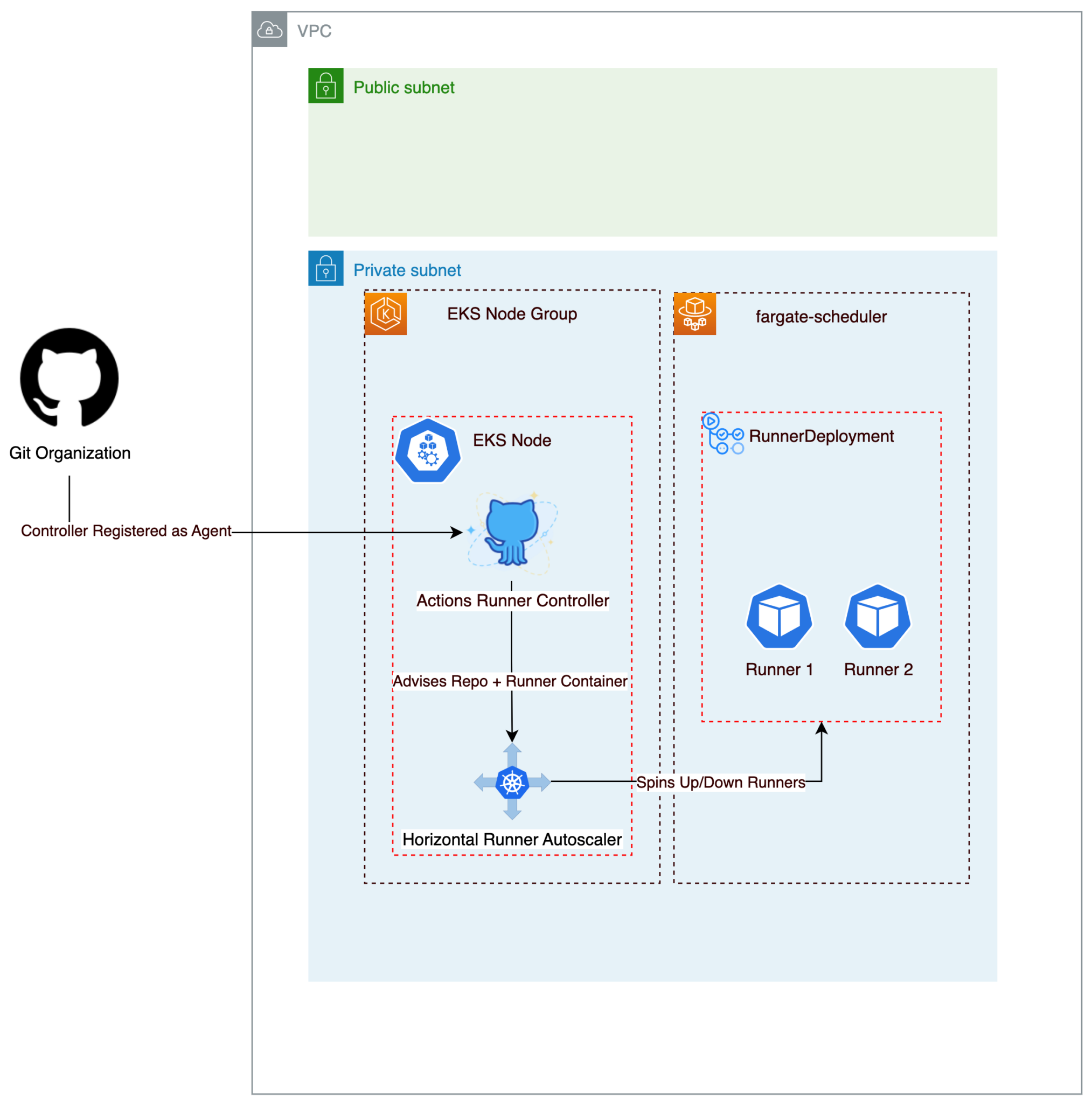
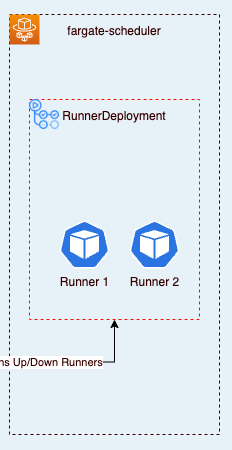
In the case of ARC, to let our runners run on Fargate, a RunnerDeployment(RD) just needs to select the Fargate namespace in its selector. On running this RD, no actual runners will be spun up until we receive a response from the HorizontalPodAutoscaler. Therefore no nodes to be running consistently, and here’s the real benefit, unlike in the EC2 solution, these Pods are being spun up and scaled down as needed, and our charge will only be for the Pod itself, not multiple instances of EC2.
From a security standpoint, we have limited our attack vector, by removing a public endpoint from the solution and from a reliability perspective, our chain of events does not rely on several Lambda functions to Spin-up and down.