
Introduction
The lakehouse architecture has gained lots of traction in the last few years. The lakehouse simply brings the best of both data warehouses and data lakes. One of the core building blocks of such architecture is delta lake storage format. Delta lake sounds to be very tightly coupled with Databricks or at least Spark. That’s not true! Delta lake is an open source format and the protocol itself is simple and public. Any client that can read/write parquet files and respect the protocol, will be able to interact with delta tables. Actually the protocol does not really dictate parquet format but parquet has been the de-facto standard agreed by the community.
All major cloud providers have built-in support for delta lake via their analytics products like Azure Synapse and AWS Athena and Redshift. So delta lake is not really tied to Spark and Databricks. It would be still cool to be able to read and write to delta using other lightweight options like serverless tools (AWS Lambdas/Azure functions). In many use cases, it makes more sense to write to delta tables using a serverless small function instead of firing up a Spark cluster. Databricks have cool tools like Auto Loader that helps ingesting data from cloud object stores but the idea around lakehouse is being open and using whatever tools you like and not forcing customers to work with a certain vendor.
Guess what! This can be done. Delta lake has a standalone offering which is a Java library to interact with delta from any JVM app. That’s one option but the other option we will explore in this post is delta-rs which is a native Rust interface to delta lake. Rust is a systems programming language designed for memory safety and performance. Python has dominated the data and AI landscape but Rust seems to be a future major player specially with consistent developer love for Rust.
Unfortunately, delta-rs does not have super friendly documentation or tutorials to get you started. This post is a baby step to help data engineers get started using Rust with delta lake.
Enough marketing fluff and let’s get our hands dirty with some code.
Setup
First, we need a bit of familiarity with Rust. You don’t have to be an expert but at least should be comfortable with the syntax and basic concepts.
The setup we need is:
- VS Code (the latest the version the better)
- rust-analyzer extension for VS Code
- Rust compiler/tooling version 1.66.0 or later
Hello delta using Rust
In the first exercise, we will create an empty delta lake table on the local file system.
Let’s kick off by opening any empty folder in VS Code and opening the terminal.
Inside the terminal run cargo new rusty-delta to initialise a Rust program. A new folder named rusty-delta will be created, navigate to that folder in the terminal.
If you run cargo run , VS Code should compile the project and print a hello worlds message.
Now you have a working bootstrapped application in Rust. Run the following commands in terminal:
- cargo add deltalake@0.6.0
- cargo add tokio@1.23.0
- mkdir /tmp/delta (if you are on Windows, adjust the path to something like c:\temp or something)
deltalake is the published Rust crate for delta-rs. tokio is a dependency for multi-threading and async programming. Many delta-rs APIs are asynchronous and we have to have a runtime to call them hence including tokio. Also the versions are pinned for reproducibility.
Now edit main.rs file in rusty-delta/src folder and replace its contents with the following:
Now, if you run cargo build it will take a few seconds to compile things and should finish without warnings or errors. The below screenshot reminds me of compiling C++ in Visual Studio.
Compiling delta Rust starter app.
Now run cargo run in the terminal to execute the current Rust program.
If all goes well, you should have an empty delta table created on the local file system. The table will have a single commit with version zero and a _delta_log log folder with a single JSON file with information about table schema and other bits of metadata. Feel free to open the file and have a look.

We will discuss the program shortly but let’s first celebrate our achievement. If you have a PySpark local installation, you can fire up a delta enabled PySpark shell and inspect table schema and contents.

The table is empty which is not super exciting but at least it is a readable delta table and it has the right schema.
Cool, let’s explain what the program does to create an empty delta table using Rust:
- The first two lines import some structs from deltalake Rust library
- Next an async function called create_table is defined that takes location to create table at and returns a DeltaTable instance
- The function starts by defining a delta table builder, which sounds very similar to the Spark session builder used in Spark apps
- The builder continues with a group of chained calls to define where to create the table and what are the columns inside it
- Then we will call await on that builder instance to trigger the chain (async stuff similar to Spark lazy evaluation) and create the table
- The return value of the await call should be unwrapped to get the expected DeltaTable instance wrapped in an Result enum (have a look here for details about this approach)
- Now the main function is simply a couple of lines to call the above defined function using a specific table location and display the table version after creation which should be zero
That’s a fair chunk of code to write just to create a table but bear in mind it’s a plain Rust application which means you can run it from something like an Azure function and there is no dependency on Spark or JVM at all.
Let’s do stuff on Azure
It’s fine to play with things locally but eventually almost all workloads will be running in the cloud. Let’s start with Azure basically for two reasons. It is much simpler to configure authentication to the storage location on Azure rather than AWS at least for demo purposes. Also AWS S3 requires much more sophisticated setup to allow concurrent writers.
To prepare an Azure storage location for our delta table, head over to Azure portal and follow these steps:
- Create an Azure blob storage account with hierarchical namespace enabled (yay ADLS Gen2)
- Create a container inside the storage account, you can call it delta for example
- Take a note of the primary access key of the account (key1 or key2)
- Take a note of the expected table location. It should be in the format of abfs://<container>@<account-name>.dfs.core.windows.net/<table-folder>
Now back to VS Code and follow these steps:
- Open Cargo.toml file and replace the deltalake dependency line with deltalake={ version=”0.6.0″, features = [“azure”]}
- The above change in cargo file is to include (turn on) specific features in the Rust delta lake dependency. Azure dependency is required to write blobs to Azure storage. Those cargo file features are somehow similar to Python extras.
- Also it is better to stick with a specific version for the demo for reproducibility reasons
- Still in terminal create two environment variables as follows (use relevant commands on Windows)
export azure_storage_location=”<Azure table path as explained above>”
export azure_storage_access_key=”<Storage account access key>”
Edit main.rs file and replace all contents with following snippet:
The major changes we have in current program are:
- Grab table location and storage account access key from environment variables (common pattern in serverless functions, but not strictly the only way)
- Extend the table create builder with storage configuration options hashmap
- This configuration can be any combination of settings to enable authentication to the table storage location
- It can be the storage account access key (simple for demo/PoCs) or other options like service principals
- For a list of all config options, have a look on this file
Now in the terminal run cargo build and make sure the program compiles successfully.
Then run cargo run to execute the new code which should create the same empty table on Azure ADLS Gen2 account. The table should be created and you can inspect folder contents in the browser or via Azure Storage Explorer if you prefer fat clients.
The table can be queried from any tool that can read delta tables (Databricks/ Synapse Spark/ Synapse Serverless / you name it).

Adding some data to table
Empty tables are not so exciting, let’s add some records to the table we created on Azure.
- First modify deltalake dependency in cargo file to be deltalake = { version=”0.6.0″, features = [“azure”, “arrow”, “parquet”, “datafusion-ext”]}
- Also in same file add an arrow dependency in dependencies section, append a new line after deltalake line as : arrow = “28”
- Arrow, parquet and data fusion are needed to write parquet files and query them.
- Now edit main.rs file and replace its contents with below snippet
Let’s explain the main program now:
- The first few lines are a group of imports . The important ones are DeltaOps which will allow us to write to the table. Also there are many Arrow related types imported.
- Next there is a function called “get_data_to_write” that creates some dummy data. The function creates some sort of an Arrow data frame in memory which has to contain schema information plus column values. Think about Arrow like parquet but in-memory.
- The function returns a RecordBatch object that will be written to the delta table shortly. In normal use cases, the dummy data should be replaced with real data.
- Next there is a function called “append_to_table“. The function takes table location, storage access keys and batch of records to write as parameters.
- Table location and storage account access key are required to create a table builder (similar to the CreateBuilder before) but this time the builder connects us directly to an existing table.
- Next a DeltaOps object is created out of the delta table instance. DeltaOps has functions to read and write (append) to the delta table.
- The next line just calls the write method of DeltaOps which takes an iterator of RecordBatches.
- The function returns a DeltaTable object which can be queried to see latest version/metadata after the write operation.
- The final piece of code is main function which calls the function to create the dummy data to be inserted and then calls append_to_table function and prints latest version after the write operation.
Cool, let’s try the new program.
- Run cargo build to compile it.
- If all goes well, run cargo run to execute it.
- It should print a success message with the version of latest commit to the table (should be version 1)

Now check your Azure storage account, you should see a new parquet file created in the table root folder (plus an additional JSON file in log folder).
Let’s have a look on the table to verify records have been inserted. This time we will query the table using Synapse serverless SQL.
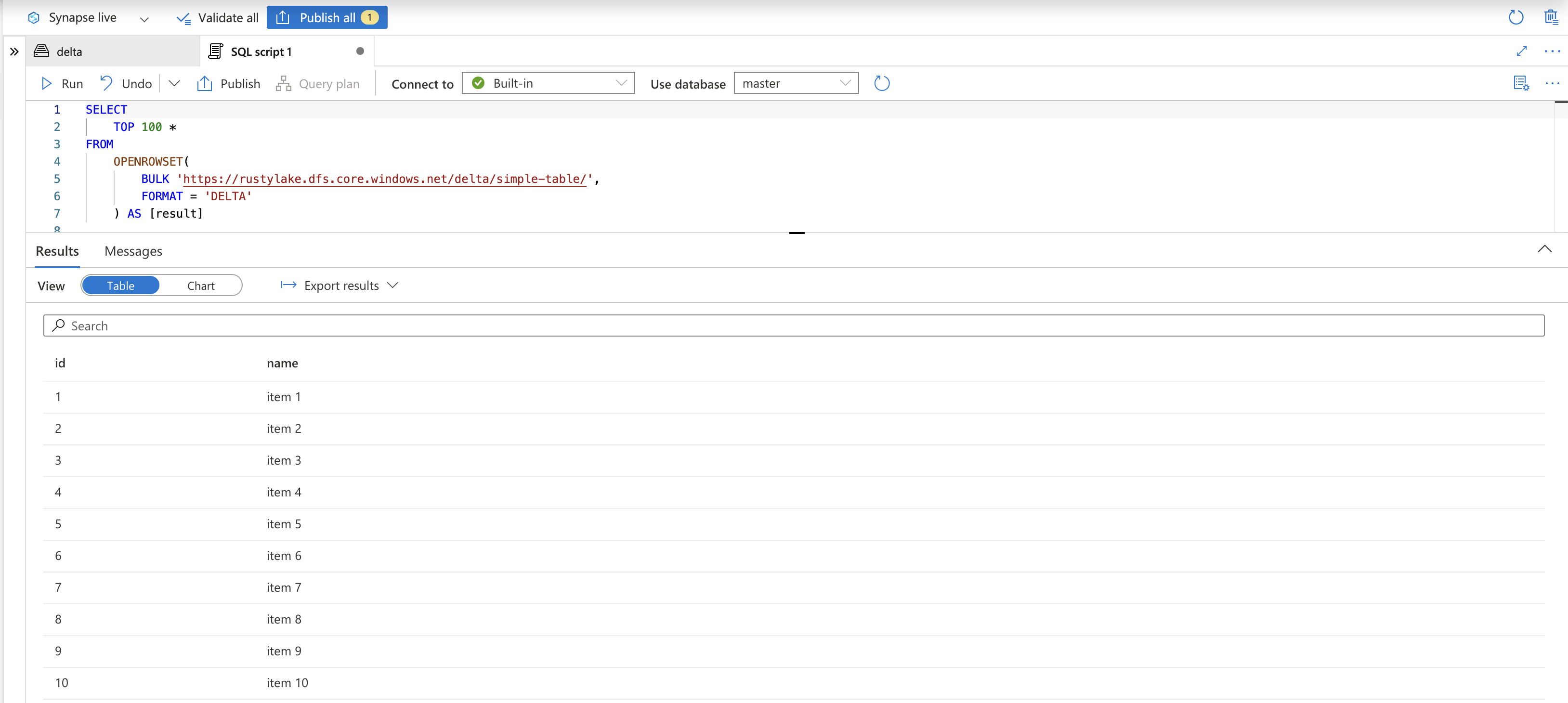
Sweet, we have a basic Rust application that can run locally or in the cloud to write data to a delta table. We can also read from delta tables using DeltaOps but I will skip that to continue with some more exciting write use cases.
What would happen for multiple writers
Let’s assume the program we have right now will be used as an Azure function that listens to changes in a blob storage container and pulls some JSON or CSV files dropped there to be loaded into a delta table. It is quite obvious that multiple files can be written to the storage account in parallel hence there could be a case where multiple instances of Azure function running at the same time. Let’s simulate this kind of pattern by triggering the current program we have multiple times.
- In VS Code terminal, navigate to the parent of the current program folder by typing cd ..
- Run cargo new runner then cd runner
- Runner folder will have a hello world Rust program and you can verify that by running cargo run
- VS Code workspace should contain two folders now (rusty-delta and runner)
- In runner folder, edit cargo.toml file and add this to dependencies list tokio = { version = “1”, features = [“full”] }
- Edit runner main.rs file to have the following snippet
- In a nutshell, the code above simulates multiple parallel executions of the rusty-delta app writing to delta lake table.
- Still in the same file, modify <writer-executable-path> to point to the delta writer executable. It should be located in rusty-delta folder then target/debug/rusty-delta.
- The path should be “../rusty-delta/target/debug/rusty-delta” but I will leave it to you to plug in the right location in case you used different folder names or something
In the terminal and still in the runner folder, run cargo run
Make sure that the current terminal session for the runner also has the same Azure environment variables used by the rusty-delta application (in case you fire up a new terminal or restart VS Code).
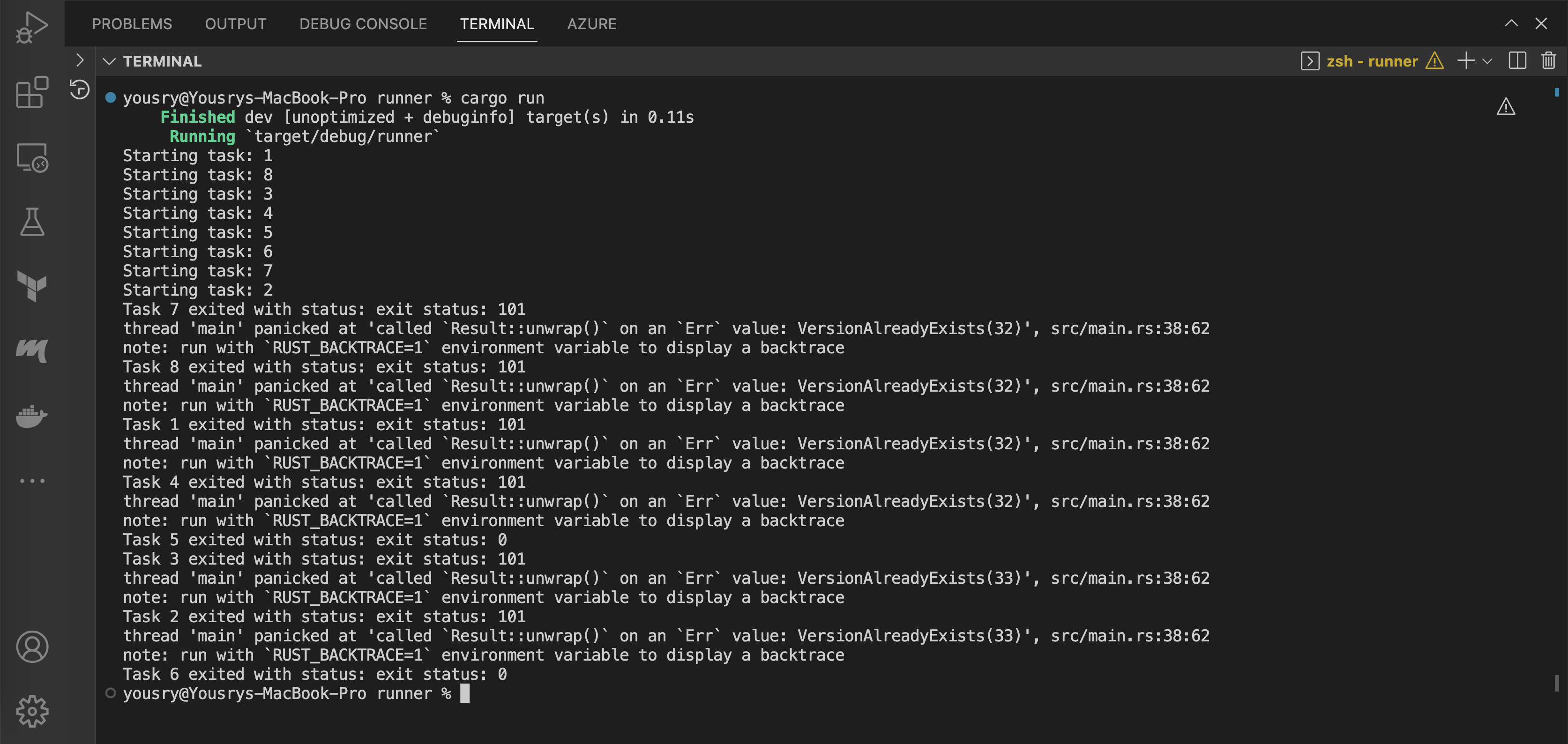
What happened here is that most instances of the writer application failed and a few of them succeeded. The failed ones appear to fail due to attempting to write the same version to the delta table. The is the classic behaviour of optimistic concurrency control approach employed by delta protocol. The idea is to follow an optimistic approach which assumes that in most cases there will be only one writer to a delta table at a time. If multiple writers happen to try to write to the table at the same time, the first one that can write the transaction log JSON file wins and other writers fail and have to retry. Azure and GCP have storage APIs that help guarantee a single writer can atomically write or rename a file. AWS has limitations regarding this aspect and has to have some special treatment.
Have a look on Delta Lake white paper for more details about how the protocol is designed. As of Jan 2023, there is still ongoing work in delta-rs to improve things like schema checking and commit loop and eventually make DeltaOps::write more user friendly.
In the case above we had 8 parallel writers where two of them managed to get their writes done and the rest failed. To allow multiple writers to work smoothly, delta-rs has the option to retry the transaction for the writers failing due to conflicting with another writer. Let’s have a look on that. Actually what we will do next is to go a bit deeper by preparing a transaction object which gives us more flexibility to control whatever actions will be part of the transaction.
Solving parallelism problem
To allow multiple writers, we need to switch from writing using DeltaOps to DeltaTransaction.
- Edit the main file for the rusty-delta application not the runner application.
- Remove the DeltaOps using line to make compiler happy use deltalake::operations::DeltaOps;
- Add the following group of use statements
Add the below function on top of append_to_table function
- Inside append_to_table function, change the line let table to let mut table
- Replace lines starting let ops till end of function with the below snippet
- In the terminal, change directory to the rusty-delta folder and run cargo build then cargo run
- You should still get a successful write to the destination delta table
Let’s explain briefly the changes above:
- Other then the use section differences, we added a new function accepting delta table reference and RecordBatch.
- The function defines a RecordBatchWriter which writes data to parquet files (it does not do transaction management).
- Based on the written parquet file(s), a group of actions can be extracted defining what file-level additions/removals are to be applied to transaction log.
- Then a transaction for the current table is defined and the above actions are added to it.
- A commit function is called on the transaction instance to commit the changes. Parquet files are already written but a commit JSON file has to be written to persist this transaction.
- The commit function implements some extra logic to retry the operation if there are some other writer(s) who just persisted a transaction with same version (you remember the VersionAlreadyExists exception). See this file for details.
The above explanation does not really guarantee things will work fine. We have not yet executed the parallel writing app, we just tried the writer app itself.
Let’s give it a go.
- In VS Code terminal, navigate to the runner folder
- Run cargo run (make sure environment variables for Azure location and access key are still there)
- All the parallel writer runs should be successful this time. You can verify number of records in delta table before and after running the command to make sure that all 8 processes ran as expected.
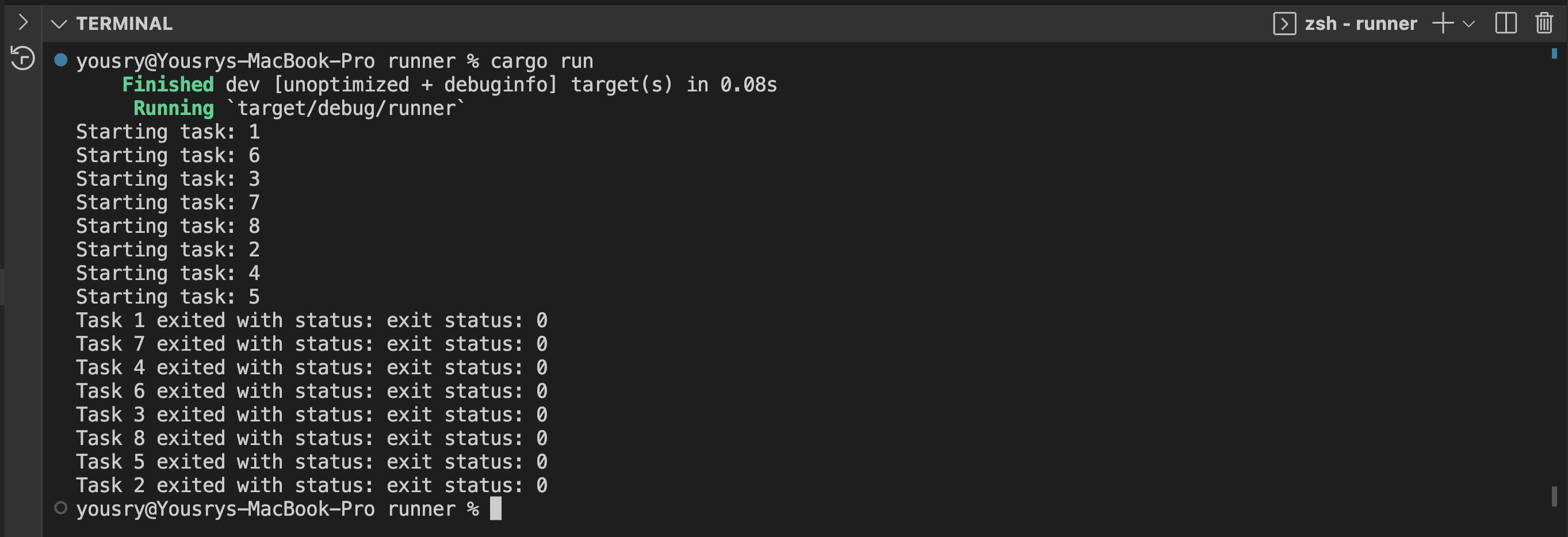
Awesome! The library can implement the optimistic concurrency protocol well provided you use the right API.
Please note that delta-rs has some WIP PRs around improving concurrent writers and properly implementing the delta protocol. So in the near future, the above approach will be probably improved or simplified. Also keep in mind that the code in this post is not production-ready code. Things like unwrapping Results should be replaced with better error handling code or fallible functions.
In this post we have seen:
- How to create an empty delta lake table using Rust
- How to add new records to the table
- How to reliably handle parallel writers
As you probably know, those blind append operations to delta table will result in tiny file problem if the number of records inserted by operation is small and the insertion frequency is high. Currently delta-rs can do a plain OPTIMIZE operation but without Z-Ordering. So an OPTIMIZE operation can be performed periodically using delta-rs and if you need Z-Ordering you have to do it via Spark. Also operations that needs a query engine like MERGE are still not there. Still, it is quite good to have a way to ingest data into a delta lake table without a Spark dependency.
Coming next
In the next part, we will explore the AWS flavour of things. It will be more complicated (ahem exciting) due to the fact that S3 needs extra logic for handling ACID guarantees of delta format specially with concurrent writers.
