
Let’s clear up one thing: we’re not building the Terminator. AI isn’t a magic spark that will spontaneously occur once you’ve collected enough data. And it’s not something that only people with seven PhDs in machine learning can figure out.
AI isn’t new either. A lot of the techniques date back to World War II, and the first AI conference occurred in Dartmouth in 1956.
We tend to think of AI as a daunting new prospect, that only the most technologically-savvy software engineers could possibly understand. But AI is actually more accessible than we often perceive it to be.
If you’ve ever:
- Modelled a complex situation in excel
- Dealt with large amounts of information
- Systematically solved a logic puzzle
- Thoughtfully criticized a performance indicator
Then you likely have most of the skills you need to build AI.
To start, let’s review some of the tasks that we’ve been able to get computers to perform using AI:
- Recognising handwritten digits
- Converting speech to text
- Designing efficient electronic circuits
- Walking on four legs in a forest
- Holding an inverted pendulum upright
- Playing chess
- Efficient targeting of advertisements
- Predicting stock prices and pricing financial derivatives
- Scheduling and planning
- Playing Super Mario Brothers
- Discovering new mathematical proofs
- Translating documents
I believe there is something that unifies all these examples. To explain what it is, let’s start by reviewing the Richard Feynman technique for solving problems:
- Write down the problem.
- Think very hard.
- Write down the answer.
Compare and contrast with the data scientist’s problem-solving technique:
- Write down the problem.
- Let the computer think very hard.
- Write down the answer.
So what does the computer need to “think very hard”?
- Representation: What does the problem look like? What would a solution look like?
- Evaluation: How do you tell how good a solution is?
- Optimisation: How do we efficiently move from one possibility to the next in order to discover the best one?
Every breakthrough in AI has discovered a new method of doing one of the above.
Representation
Moravec’s Paradox illustrates this nicely. “The hard things are easy, and the easy things are hard.” Tasks, like beating a grandmaster in chess or discovering novel mathematical proofs were achieved by AI before a task like “recognize the number seven when it’s written down.”
A big reason for this is representation.
It’s relatively straightforward to represent the state of a chess board and encode the rules for checkmate. A formal (i.e. programmable) definition of a mathematical proof was proposed in 1910.
But there are billions of different ways to write down the number 7. Everybody has their own unique handwriting.
An example of an effective representation in chess and other board games is the “game tree”. This consists of representing the state of the board, and all of the possible moves you and your opponent can play, with a score attached to each board state.
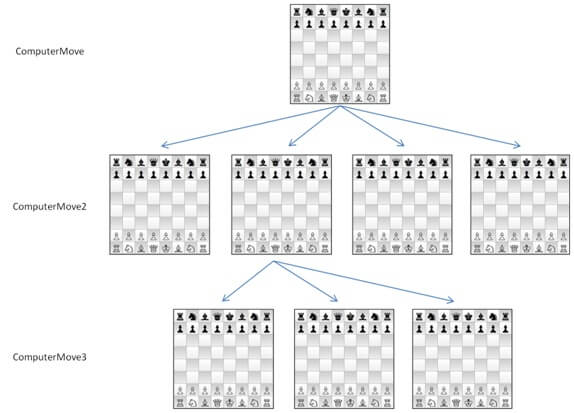
Source: codeproject.com
This is why deep learning is exciting. It provides new techniques for representing the problem. Rather than come up with a representation ourselves, we can use deep learning to find the best way of representing an image automatically.
Evaluation
Antoine de Saint-Exupéry said:
“If you want to build a ship, don’t drum up people to collect wood and don’t assign them tasks and work, but rather teach them to long for the endless immensity of the sea.”
So it is with people, so it is with computers. We can tell computers precisely what to do and they’ll carry it out without question. Or, we can lead them more effectively by telling them what a good solution looks like, and let them figure out how best to achieve it.
So why doesn’t everyone use this method? Why are people so tempted to micromanage and program every last detail? I think there are two reasons:
1. Coming up with evaluation measures is really hard!
We can say “I know it when I see it”, but giving an actionable definition of good and bad can be incredibly demanding. It requires a great deal of clarity of thought. Every programmer has experienced this when the time comes to write unit tests for their code. Invariably some corner case comes up which they never thought of.
This is one reason why “Big Data” is a big deal. The data provides unit tests for us, and this leads to an evaluation measure. We just compare the expected results in the data with the results generated by the algorithm.
2. Perverse optimisation
You get what you measure. There are endless stories about how rewarding the wrong thing gives horrible results. One example comes from the time of British rule of colonial India. The British government was concerned about the number of venomous cobra snakes in Delhi. The government, therefore, offered a bounty for every dead cobra. Initially, this was a successful strategy as large numbers of snakes were killed for the reward. Eventually, however, enterprising people began to breed cobras for the income. This happens in AI as well.
A common problem in machine learning is biased data sets. An example of this is the application of machine learning to police work. Some neighbourhoods have higher arrest rates than others. This leads the algorithm to recommend sending more police to ‘hotspots’. Once the police are there, they can make more arrests, leading to more data indicating arrest rates in these ‘hotspots’, and hence more police should be sent. This vicious feedback loop can occur even if the initial disparity in arrest rate was due to chance. Cathy O’Neil outlines the damage this sort of bias can do in her book “Weapons of Math Destruction”.
Optimisation
After we can represent and evaluate solutions, we just have to find the best one. However, we can’t try them all. This is because of the problem of Combinatorial Explosion. The number of solutions increases exponentially with the complexity of the problem.
Consider the table below for the game of Sudoku.
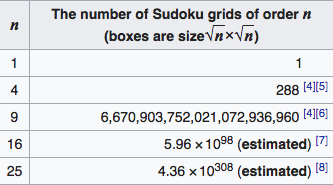
For comparison, the number of electrons in the universe is estimated to be 10^80.
On the bright side, the amount of computation available is increasing exponentially as well. This is because of Moore’s law: the amount of computation available doubles every 18 months. A similar law applies to the amount of storage available.
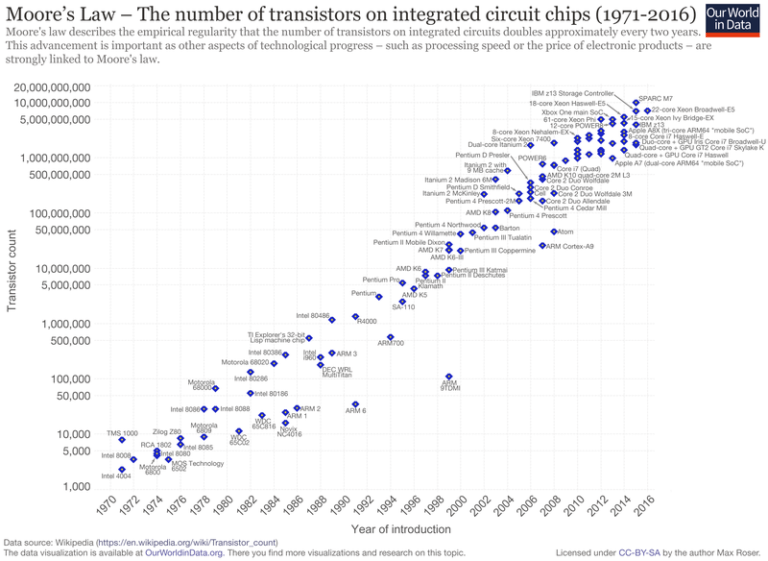
A lot of research in AI involves coming up with optimisation algorithms, techniques for finding the best solution, without examining all possibilities.
An example of this is gradient descent. Suppose we want to measure the influence of experience on performance by finding a line of best fit to some data. Rather than try every possible parameter (there are infinitely many), we can use a little bit of calculus to choose the next parameter that fits the data better. Here’s an example.
Optimisation is a beautiful science because it’s so varied. There are optimisation algorithms inspired by metallurgy (simulated annealing), biology (genetic programming, ant colony optimisation), and theoretical physics (Hamiltonian monte carlo). It’s a wonderfully rich mathematical area, combining rigour and extreme practical application.
AI: The ongoing puzzle
These problems of representation, evaluation and optimisation are deep and touch on a lot of different areas. You’ve probably dealt with your own problems in these areas. And some might not be solved yet, we’re solving them as we go along.
Unfortunately, there’s no comprehensive checklist or process for doing AI well that we can teach. But as the examples in the beginning illustrate, there are some well-solved problems using AI which we’d love to discuss with you.
I hope you’ll want to try your own hand at AI. To get started, you can get in touch and enquire about training, consulting, and intern programs, or try your hand at a kaggle competition.
Happy problem-solving!
