
In the ever-evolving landscape of technology and business, the importance of data management has reached unprecedented heights. The accelerating value and capabilities that can be extracted from good data are reshaping industries and driving innovation. However, a significant challenge persists: the majority of data is not inherently good.
In this blog, we’ll explore how modern data management fosters the crucial components of good data, why it matters, and how we can ensure its quality throughout the data management lifecycle.
How do we define good data?
 Good data, bad data, ugly data? It all depends on the context in which it is used.
Good data, bad data, ugly data? It all depends on the context in which it is used.
Understanding the context in which data operates is paramount. Good data is not a one-size-fits-all concept; it varies based on the specific use cases. Despite the diversity, certain common themes define good data:
- Availability: Data must be accessible when and where it’s needed. It must be tangible.
- Accurate and Correct: The core foundation of trust in data, ensuring decisions are based on reliable information.
- Discoverable: In addition to being available, it must be easy to find and retrieve by all types of users..
- Understandable: When put in context, must create clarity in the interpretation
- Reliable: It should be consistent over a period of time and provide dependable results upon regeneration.
- Currency: Data must be up-to-date and relevant.
It’s important to note that these aspects don’t need to be perfect individually but collectively must be “good enough” to be truly valuable.
It is possible to dissect and elaborate on each of the above dimensions to great lengths, but let’s stick to what it means to generate and manage data accuracy and integrity.
 Ensuring Accuracy and Correctness of data
Ensuring Accuracy and Correctness of data
In the realm of data-driven decision-making, trust is the linchpin that holds the entire process together. Trust in data implies confidence in the accuracy, reliability, and relevance of the information at hand. When decision-makers trust the data they are working with, they are more likely to make informed choices that positively impact their businesses.
Decisions based on accurate information enhance operational efficiency. When organisations operate with a clear understanding of their data, they can streamline processes, allocate resources effectively, and respond promptly to changing circumstances.
The GIGO (Garbage In, Garbage Out) principle is a fundamental concept in computing and data science, emphasising the direct correlation between the quality of input data and the quality of output.
Here’s why acknowledging this principle is essential:
It is to be noted that GIGO extends beyond individual decisions; it has systemic implications for the overall functioning of an organisation. Flawed data can lead to cascading errors, affecting multiple facets of operations and hindering long-term success.
Data can be as simple as Base data – the fundamental and raw information and Derived Data – the data that is processed/transformed and analysed for specific purposes.
So how is modern data management ensuring data accuracy?
All types of data (Base data more so) go through rigorous validation processes that are implemented both during design/generation time, and also during the run time, as it moves along the data life cycle.
Organisations are also implementing different strategies for real-time streaming data vs batch data. Certain types of accuracy checks are implemented in micro-batches for streaming data, whilst more holistic data quality checks are implemented in predefined windows or batches.
Data quality for real-time streaming data is crucial for making accurate and timely decisions in real time. That’s why it is important to make data quality visible along the data management cycle.
Shifting Left as much as possible
We have heard of Shift-Left testing, but the same concept applies to data quality at source.
Organisations are now implementing strategies to make data quality apparent as close to the source as possible, rather than being treated as an afterthought in the downstream part of the cycle.
With observability tools rife in the market, it becomes paramount to manage data quality incidents proactively, by identifying and addressing issues before they impact operations further down the data stream.
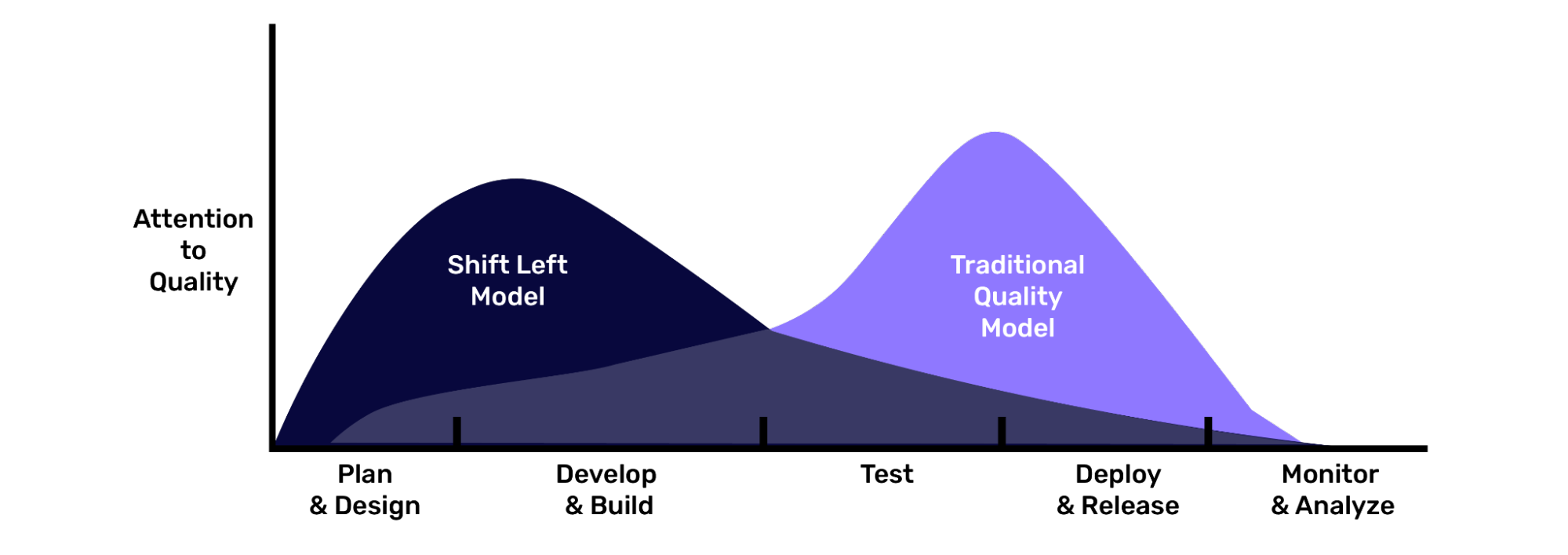 Implementing data quality as early as possible, by nipping data quality issues in the bud, helps in:
Implementing data quality as early as possible, by nipping data quality issues in the bud, helps in:
- reducing the likelihood of downstream errors, and minimising the impact on business processes.
- reducing the overall cost of data quality management, by preventing issues from propagating through the system and requiring more extensive corrective actions.
- creating shared understanding of data quality requirements, and encouraging a proactive approach to maintaining data integrity; and
- increasing the trustworthiness of the data throughout its lifecycle, making it more reliable for downstream analytics, reporting, and decision-making.
In addition to the above, data quality enforcement should be carried out as often as possible, to aid in continuous monitoring and improvement. This will ensure data quality, from the source, to transformations, all the way through to reports and metrics.
In the digital age, where data is hailed as the new oil, managing it effectively is not just a choice, but a necessity.
Accurate and correct data is the bedrock of organisations, and understanding the broader context of good data is crucial for its effective management. Shifting data quality checks in the data management lifecycle is one of the tried-and-tested techniques to improve trust in data, which is necessary to ascend the data pyramid into the realms of advanced analytics.
In subsequent posts, we will delve into each aspect of good data, unravelling the intricacies that make data a true asset in the digital era. Stay tuned for a deep dive into the world of ‘modern data management’!
