
Written by Danny Wong (Senior Solutions Architect Databricks), Petr Andreev (Senior Databricks Engineer, Mantel Group), Nicholas Anile (Senior Data Scientist, Mantel Group)
Introduction
At a time when groundbreaking technological advances are landing each week, data quality has never been more in focus or more prominent on organisations radar. Testing plays a significant role within the software development lifecycle and while it’s broadly recognised as important within data, data quality testing presents unique challenges. Data-driven decision making requires reliable and trustworthy data, prompting data engineering teams to interrogate data integrity (accuracy, completeness etc). Some teams rely heavily on manual test development and testing approaches which are impractical as datasets grow in complexity and size. For instance, imagine churning through terabytes of data in your lakehouse, painstakingly checking for duplicates and inconsistencies across 100s of tables… manually.
In this blog, we’ll walk through some of the journey that we see team’s travelling, discussing some of the key pain points of manual testing approaches and how you can embrace the power of Databricks through the structure of native metadata driven framework; demonstrate the flexibility this approach offers and the range of data quality tests that can be harnessed. Ultimately, enabling technical teams to focus on adding more value to organisations rather than putting fires out and empowering stakeholders with trusted data.
The pain point of manual testing
Manual testing has been the cornerstone of data quality assessments in recent years, however, it does come with limitations – let’s dig into some of them and why it’s time to consider a more comprehensive approach to data quality assessment.
Comprehensive Coverage
The immediate roadblock that most manual tests encounter is being unable to test datasets completely and ending up with limited test coverage. This can be fine when identifying large scale issues, for example invalid type casting, which would affect the majority of rows in the dataset. However, having limited test coverage will often fail to identify edge cases in data quality issues, such as failed conversions of uncommon specific date/time values or data truncation of floating point numbers . Additionally when working with unreliable datasets with data quality issues in the source data (e.g. typos), limited test coverage just does not give you assurances that your data is clean.
Custom Notebooks and Ad-Hoc Testing
Suppose that you write tests in a notebook to automate their execution and achieve full coverage. While this brings you one step closer to your desired outcome, you would still need to address the remaining limitations that this introduces.
Creating individual custom notebooks for each dataset in your lakehouse will quickly result in a lot of ad-hoc created notebooks, which do not adhere to any standard (consistency being key when operating at scale). These notebooks are likely to test similar things resulting in a lot of different code doing the same job, violating the “Don’t Repeat Yourself (DRY)” principle. Such ad-hoc development will lead to a set of dependencies which are unlikely to be maintained, wasting developers’ time and cluttering repositories (First Law of Kipple). As a consequence, this approach incurs a hidden cost in the form of technical debt, where the initial convenience of rapid development transforms into long-term challenges in maintenance and efficiency.
These kinds of custom testing notebooks can be more challenging to incorporate within CI/CD processes, require significant additional documentation, and necessitate additional development time to scale out to suit all the tables within a dataset or even need more performance optimisations to run on certain tables fast enough.
Transforming Towards Automation
Regression Testing and Data Quality Trends
Suppose now we have a set of standardised notebooks that adhere to the same principles and are developed in the same style. Now when we introduce any changes to our code, we will have to rerun these notebooks to get the new test results. We also want to be able to log the results so we can access that information in the future (or isolate when we might need to time travel too). Hence a testing framework needs to be able to execute testing notebooks repeatedly and reliably such that we can perform regression testing and include logging information so we can monitor data quality tests.
Proactive Monitoring – Alerting and Dashboards
The ability to review test results is an important aspect of the framework, however we want to avoid having data engineers or DataOps team actively monitoring data quality instead of focusing on other deliverables. Therefore, we want to send alerts proactively in case our testing has gone wrong and data quality expectations are not being achieved. This also drives the need for a dashboard which can be reviewed by users upon receiving the alert, in order to understand the significance and cause of test failures, with tools such as Databricks it’s possible to implement alerts at various levels or build dashboards to proactively monitor the testing framework.
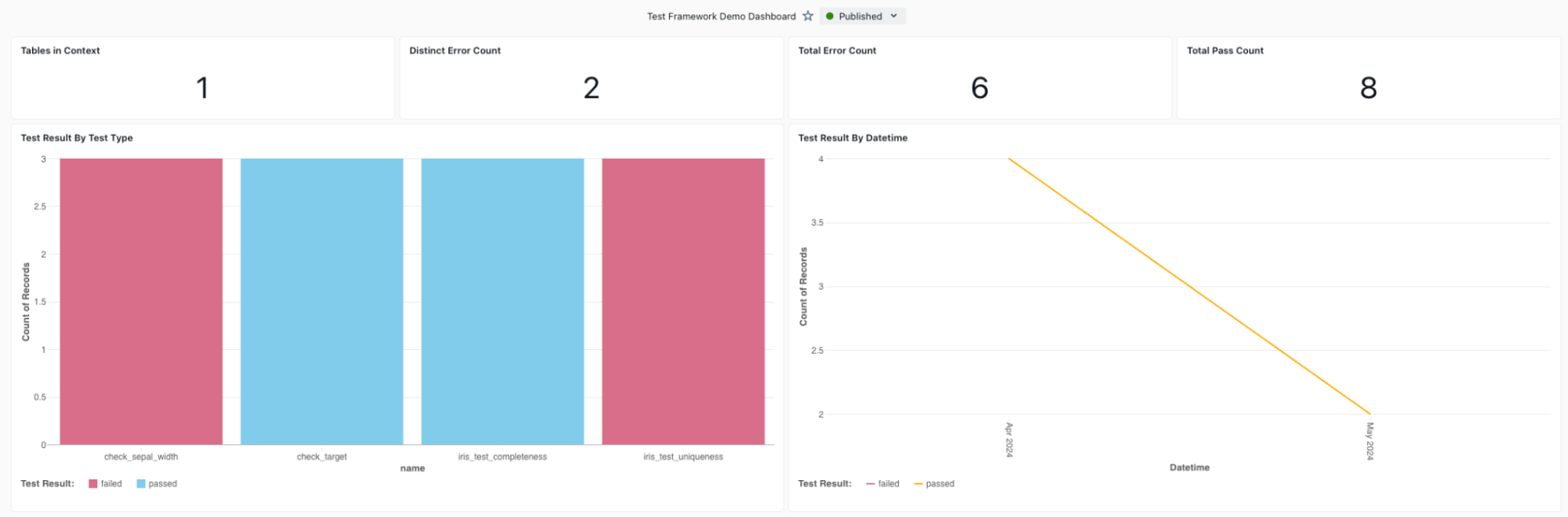 (An Example Dashboard showcasing Test Results)
(An Example Dashboard showcasing Test Results)
Testing Across Environments
Another aspect of testing that is crucial to factor into a testing strategy is handling multiple environments in the lakehouse. For example, we want to be able to create tests in a test environment to validate that they work in the way we expect them to, but we want to be able to push the same tests to production and have continuous testing being performed on productionized datasets. Hence the testing framework must include pipelines for CI/CD automation and deployment of tests across environments and workspaces.
Time consuming and unsustainable workloads
The final key problem with any kind of testing is the unsustainable workload that falls on data engineers trying to test the ever growing number of datasets. When designing the framework it’s important to ensure that addition of new tests and integration of new datasets into the framework is easy and quick. Otherwise, if it is time consuming, it is unlikely that the practice of testing will be well maintained and might become more of a hindrance to the development process (slowing the momentum of onboarding sources). This is where metadata driven automated frameworks come in. Defining tests through metadata reduces new dataset onboarding timings and the maintenance overhead for data engineers.
The Solution: Metadata-Driven Testing with Databricks
While there are many existing testing frameworks available as packages or commercial software, we have created a Databricks native framework which can be an excellent starting point for your testing solution. The framework is designed to be straightforward and simple to use, while being highly customisable. It’s intended to provide users with a starting point for testing which they can later iterate and improve upon. Alternatively, even if the framework itself is not enough, using it will give our team enough perspective to understand the requirements for more complicated testing solutions in certain scenarios.
Metadata Driven Approach
The idea of a metadata driven approach consists of developing a set of functions that manage testing and having users specify metadata such that the functions can perform the tests.
We have created an implementation of a metadata driven framework which is available for use here. In the paragraphs below we will walk through the key aspects of the framework.
We divide the tests into two distinct subgroups:
- Standardised tests – these are the tests that are so commonly used that they are worth the additional effort of developing a standardised function.
For example, if your team always tests for unique primary keys in the data. Then you could write a function that given metadata about a table the key column will be tested for whether or not the keys are actually unique. - Custom tests – These are the tests that might be relevant to a specific table or column, and developing a standardised function for them would just add additional non repeatable code into the main repository. For example, if you have a business rule for table X that if column Y is True then column Z needs to be an integer between 1.6 and 2.
Having these two types of tests will accelerate the testing team’s workflow as they’re able to reuse the standardised functions and only need to write minimal code to create custom tests that can be executed as part of the framework.
Test Structure
Every test is defined through an entry inside a .yaml file. Each .yaml file should contain a list of tests. Each test must containing the following information:
- name – The test name that gives users an idea of what the test is actually trying to accomplish (this is only used for reporting)
- dataset – name of the dataset that test belongs to (only used for reporting)
- table – name of table that is being tested. Must correspond to the Unity Catalog naming conventions of a three part namespace: <catalog>.<schema>.<table_name> and is used as an input to the testing functions.
- function – name of the function that will be executed to perform the test. Must correspond exactly to a function name in utils.py.
All the additional metadata specific to the standardised and custom tests should be provided after the above variables are defined. A few sample files can be found inside /test_config_files/ folder in the repository.
How To Define Standard Tests
To define a standard test, you will first have to write the test function inside utils.py file. The function should ingest a dictionary of metadata and return the same dictionary with updated values. This function will rely on some standardised but test specific metadata, such metadata should be specified in the function docstring and be provided in every test definition in .yml files.
For example, let’s consider a sample uniqueness test that we have provided in the repo. We have defined a test_uniqueness() function inside utils.py file. The function intakes metadata dictionary as an argument and expects table and columns_to_test keys to be present in the dictionary. It then makes use of these to query the right table in spark and subset columns for testing.
Below is an example yml script snippet (from test_config_files/test_set_standardized.yml file), that we would use to define a test for uniqueness:
- name: iris_test_uniqueness dataset: iris table: hive_metastore.sample_data.iris_data function: test_uniqueness columns_to_test: - sepal_length - sepal_width - petal_length - petal_width - target
How to Define Custom Tests
All custom tests are run through the same test_custom() function located inside utils.py file. This means that all custom tests must have the same metadata structure. Each test must contain select and assert values.
- select – is a valid string of SQL of any complexity that selects data from one or more tables.
- assert – is a valid string of python code which tests the df object (data selected using SQL in the select query) against a condition and always results in a True or False value.
Let’s take a look at a sample custom test we have defined inside test_config_files/test_set_custom.yml. This test checks that there are no negative values inside column sepal_width.
Here the select statement is defined as select sepal_width from hive_metastore.sample_data.iris_data where sepal_width < 0 which selects any rows in the column that are negative.
The assert statement then tests the condition df.count() > 0 and fails the test if it is true, meaning that there is at least one negative record.
Below is an example of how the test would be defined in the .yml file. Here “>” allows us to write multi-line strings in YAML.
- name: check_sepal_width dataset: iris table: hive_metastore.sample_data.iris_data function: test_custom select: > select sepal_width from hive_metastore.sample_data.iris_data where sepal_width < 0 assert: df.count() > 0
Test Orchestration
All testing orchestration is conducted via the power of Databricks Workflows, the testing_executor notebook defines all the parameters for the testing framework run, reads the specified .yml files and runs test executions.
The notebook expects the following parameters:
- config_filepath – should be the filepath/directory containing all the yml files defining the tests you want to run.
- results_table – should be the name of the table where all the results will be pushed to provided in a three part namespace <catalog>.<schema>.<table_name>
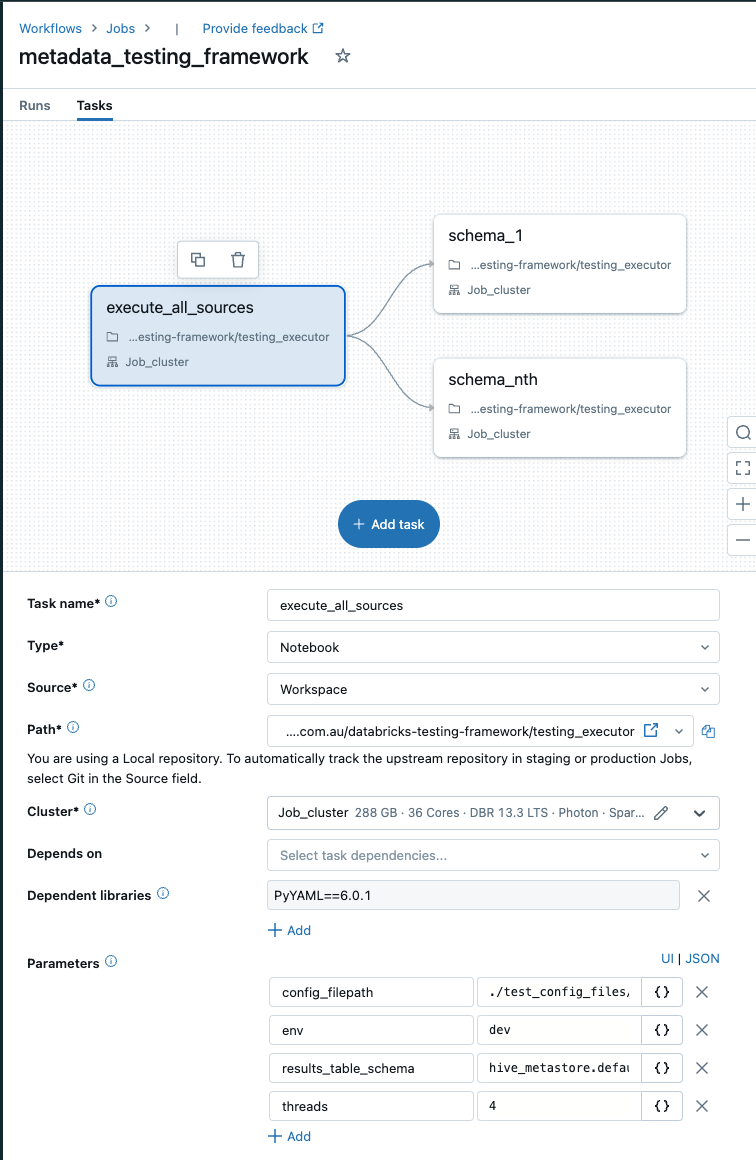
(Example Framework Workflow Configuration)
Try It Yourself
To have a feel for how the framework runs, you can clone the repo, generate some sample data using the code in sample_data/get_sample_data notebook. And then run the testing_executor notebook to see the results.
Results
Overall the introduction of automated testing framework to your development pipeline creates several key improvements in your environment:
- Improves data quality and reduces errors that could have been overlooked in manual testing.
- Accelerates time to production for your pipelines as it automates the testing step of the deployment process. Thus improving efficiency and productivity of the data engineering team.
- Enhances trust and confidence in pipeline changes, allowing teams to work in an agile manner with incremental improvements to the pipelines.
For example:
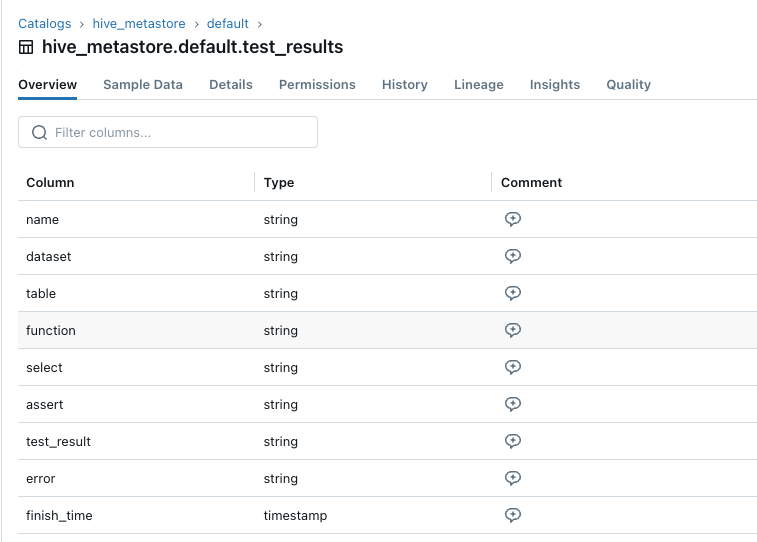
(Test_results table schema)

(Test_results example tests)
Impact
The testing framework we have discussed above has been implemented for the Department of Transport and Planning Victoria (DTP) in Australia and has provided them with tangible benefits over manual testing. The key success factors are outlined in the table below:
| Factor | Automated Testing Framework | Manual Testing Approach |
| Development Time | Automated testing suite for a new data source system takes between 1 and 3 days of development depending on the number of customisations | Creating a manual testing report for a data source system can take up to 1 week |
| Test Coverage | Automated testing covers 100% of total data volume | Manual testing covers less than 1% of total data volume. |
| Repeatability | Regression testing can be completed with a click of a button and is orders of magnitude faster. | Any changes to data at the source / data pipeline will require manual testing to be completed again. |
| Agile | Teams can deliver in agile ways, providing flexibility and incremental value. | Teams can only use waterfall delivery methods due to testing being very time consuming. |
Conclusion
An automated testing framework offers numerous advantages that significantly enhance data engineering development and quality assurance processes. Through automating repetitive and time-consuming tasks, data engineers are enabled to work on more value driving activities. The potential human error involved in significant manual testing is also heavily reduced. Overall, automation results in faster feedback cycles, enabling early detection of data quality issues and allowing for relatively small immediate corrections rather than the significant uplift of a source littered with years worth of issues that were never detected. Ultimately, the automated approach to testing data quality introduces consistency and scalability into the process for data engineers and increases the trust and reliability of data for all downstream users.
The native metadata framework also created the advantage of a low barrier to entry for Business Stakeholders getting in on the action when conducting User Acceptance Testing, we found that this increased collaboration and co-creation of tests had the best outcomes.
It’s time to take action! Launching your testing efforts won’t take long now, get moving now to reap the rewards.
A quick word
A number of testing solutions exist within the market such as Soda, Great Expectations, and testing within dbt (if you’re using it), each of which possess a great deal of functionality and some pros & cons. The framework was developed to simplify the tooling stack and remain Databricks native when the framework of Delta Live Table (DLT) is not being actively developed.
