The emergence of Data Scientist and Machine Learning Engineer roles
From 2013 to 2019, data science postings on Indeed’s website have skyrocketed 256%, demonstrating a growing demand for data science-related jobs. This spectacular and steady rise is attributed to the burgeoning volume of unstructured data in companies, like online clickstreams, social media texts, real-time data from IoT devices, speech and images. In addition, business owners are beginning to realise the immense potential of their data, but they don’t know where (and how) to harness it. Therefore, they hire data scientists to swim through the sea of data and hunt for valuable insights, enabling businesses to make data-driven decisions.
Fast forward a few years, the landscape of data has matured considerably – data science has grown into more than just a tool to clean data and gain insights. A subset of the data science industry – machine learning (ML) – has emerged as a valuable skill to organisations around the world, attracting data experts to develop use-cases such as forecasting churn and detecting fraud.
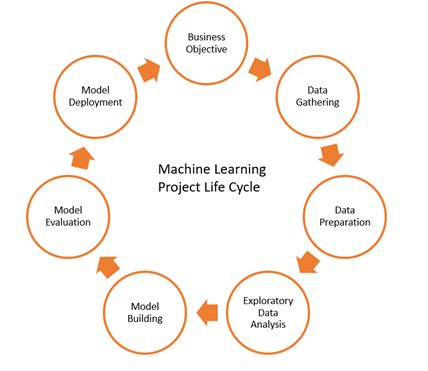
A typical Machine Learning Lifecycle
Source: https://pianalytix.com/machine-learning-project-life-cycle/
A decade ago, the assumption was that a data scientist could accomplish all the tasks in an ML project lifecycle, from interfacing with business stakeholders, gathering raw data, to deploying an ML model to production. Now, however, there has been a proliferation of related jobs to handle many of those tasks including data engineers, machine learning engineers, data analysts and product managers. This proliferation will continue to grow, especially in large companies, as there is an established process of splitting work in an ML project between the aforementioned roles. However, smaller organisations do not yet have the luxury of recruiting a large data science team, thus the first few data science hires are expected to work across these distinct functions as “full-stack” data scientists. The remainder of this article will expand on the roles of a data scientist and a machine learning engineer in the context of a large and established data science team.
This guide is brought to you by Ivan Pua, Data Scientist and Brad Jackson, Machine Learning Engineer at Eliiza. We have both worked independently and collaboratively to deliver scalable AI and data science solutions across many industries in Australia. We will discuss the following in this guide:
- Review and compare the responsibilities of a data scientist and a machine learning engineer in the machine learning industry
- Discuss the skills required by a data scientist and machine learning engineer, as well as the similarities and differences
- Explain why it is essential to ensure strong collaboration between these two roles and how
Key Responsibilities of Data Scientists and ML Engineers
Data Scientist
Dubbed the “Sexiest Job in the 21st Century”, the current demand for data scientists is higher than ever, though their responsibilities have evolved over the years. Initially, data scientists were mainly in charge of understanding business problems and providing data-driven insights using statistical modelling. With the renaissance of machine learning and deep learning, nowadays they have an additional task – building machine learning algorithms that solve problems. They are also typically the trailblazers in an ML lifecycle. Of course, no two data scientists are the same; the job scope depends heavily on the size and nature of the company.
Nevertheless, their typical duties could be boiled down into the following:
- Identifying business requirements and managing stakeholders relationships:
- Understanding the pain points and challenges in a business
- Brainstorming data science use-cases and prioritising them based on desirability, viability and feasibility
- Defining success criteria with business stakeholders (e.g. increased sales, decreased churn rate)
- Presenting the initial scope of data science solution, as well as the final outcome.
- Gathering data
- Hypothesis generation – developing an educated guess on the “factors” that impact a business problem, and then validating with stakeholders. This step helps in selecting useful features in training a model.
- Identifying data sources in the business, and defining the labels based on a logic
- Performing Exploratory Data Analysis (EDA) on a dataset to assess the data quality
- Preprocessing data
- Transforming the data using techniques such as normalising numerical features, handling outliers, combining multiple features and more.
- Imputing missing values in a dataset
- Encoding categorical features into numerical values
- Model training and inference
- Researching and building a custom machine learning and deep learning models, or use a pre-trained model
- Training the model, then evaluating it on an unseen dataset
- Optimising a machine learning model based on the pre-defined metric (e.g. recall, precision) by tuning the hyperparameters of the model
- Visualising data
- Displaying model performance and any business insights from data on a dashboard
Machine Learning Engineer
According to Gartner’s report, the ML engineer role is forecasted to be the fastest-growing role in the data science space in 2023 – for every 10 data scientists, they will likely be between 5 and 10 ML engineers. The chief responsibility of ML engineers is to take the ML models that are built by data scientists and scale them out into production while adhering to business Service Level Agreements (SLAs). ML engineers will often apply MLOps – a set of practices and patterns for managing the ML lifecycle, ranging from data sourcing to model deployment & monitoring.
The main responsibilities of an ML engineer are:
- Initial scoping of production requirements, which can shape a Data Scientist’s solution. During a project, an ML engineer may ask:
- What is the required scale and performance criteria of the ML solution?
- In what form, and at what speed is the input data arriving?
- What is the best-fit architecture for both the solution, and the business?
- Productionisation
- Uplifting models from notebooks into production-ready code – making them scalable, testable and maintainable.
- Abstracting & automating repeatable tasks.
- Optimising the underlying codebase & technologies to ensure the ML models meet required criteria outlined by both the business and data science teams.
- (which hold cleaned & curated data, often reusable, for training and evaluating models) and orchestration tasks (e.g. run X pipeline upon either Y trigger, or at Z o’clock).
- Deployment
- Serving models for live querying (which may extend to developing the APIs serving the model, API security & front-end user interfaces)
- Batch inference of models – getting trained models to process large amounts of data in-bulk, and return corresponding results.
- The ongoing maintenance, monitoring and debugging of ML models and data quality.
- Governance & version control of ML lifecycle artefacts, which extend to:
- Models
- Features
- Hyperparameters
- Pipelines
- Evaluation metrics
- Operational performance metrics
- Logs
Key Differences in Responsibilities of Data Scientist and a Machine Learning Engineer
A data scientist is focused on understanding the business problem, sourcing and preprocessing data, and building machine-learning models to solve the problem. On the other hand, an ML engineer optimises these ML models based on a pre-defined success criteria (e.g. better performance and speed), deploys them to production, as well as monitors the model’s performance.

A machine learning project is like a car manufacturing plant.
Let’s take a real-world example – you can think of an ML project as a process of manufacturing cars. Data scientists would be involved in developing the blueprint of a car; and conducting research to ensure it is aerodynamic, durable, and contains essential components like engine, brakes and chassis.
ML Engineers, on the other hand, take the final blueprint off the hands of the data scientists and build the infrastructure (i.e. factory) to mass produce the cars. ML Engineers also ensure that there are minimal disruptions in the entire production process, and continually refine the infrastructure involved in the production. A matured factory would be capable of mass producing multiple different blueprints at any single moment.
Skills Required for Data Scientists and Machine Learning Engineers
| Skills | Data Scientist | Machine Learning engineer |
| Programming Languages | Python, R, SQL | Python, C++, Scala, Java |
| Version Control | Git | Git |
| Common IDE | Jupyter Notebook (Local and Cloud-based e.g. Google Colab) | Preferred code editors, CLI tools |
| Cloud Platforms | AWS, Azure, GCP | AWS, Azure, GCP |
| Background | Statistics | Software Engineering, Cloud Engineering |
| Machine Learning and Deep Learning Algorithms | Deep knowledge of PyTorch, Tensorflow, Scikit-learn | Conceptual Knowledge Required |
| Hyperparameter Tuning | Optuna, Scikit-Optimize, Hyperopt, Ray | – |
| Data Visualisation | Tableau, PowerBI, Bokeh | – |
| Feature Engineering Tools | Scikit-learn, Cloud Tools (Sagemaker, Vertex AI, Azure ML), dbt | Spark, Cloud Tools (Sagemaker, Vertex AI, Azure ML) |
| Model Deployment | – | Docker, Kubernetes, TFServing, TensorRT, TorchServe, Cloud Tools (Sagemaker, Vertex AI, Azure ML) |
| Model Orchestration | – | MLFlow, Airflow, Cloud Tools, Argo |
| Model Monitoring | – | Cloud Tools (Azure Monitor, Sagemaker Model Monitor, Vertex AI Monitoring ), Grafana + Prometheus, Neptune |
| MLOps Frameworks | – | MLFlow, Kubeflow |
From the table above, one of the major skill differences between data scientists and ML engineers is the code they write. Data scientists usually write higher-level code with Python or R to analyse data and develop machine-learning models. In contrast, ML engineers may occasionally leverage lower-level code like C++, or utilise Spark to handle computationally-heavy workloads, in order to improve the training, testing and query performance of large-scale ML models.
Furthermore, data scientists are often required to be more creative in their day-to-day as their goal is to use data to tell a story, hence they would craft beautiful visualisations to present their ideas and insights. ML engineers, on the other hand, are more technical, and sit at the crossroads of data science and IT. They require a stronger foundation in software engineering, DevOps and cloud engineering.
However, data scientists and ML engineers aren’t exactly two worlds apart; they both enjoy some overlap in skills and experiences. One of them is effective communication skills, albeit for different purposes. Data scientists are typically the ones who liaise with stakeholders directly, so they will need to have a strong business acumen to identify the pain points of the business and brainstorm strategies to solve them. On the other hand, although ML engineers don’t necessarily need to develop business use cases, they also have to heavily engage with technical teams to integrate the ML platform with existing business infrastructure.
In addition, as observed from the table, both roles have to be well-versed in major cloud providers such as AWS, Azure and Google Cloud, because more and more organisations migrate their data to the cloud. Moreover, collaborative coding with Git is necessary for both roles, in order to peer review each other’s codes whilst improving efficiency.
How Data Scientists and ML Engineers work together and collaborate
The collaboration between ML engineers and data scientists is not linear, whereby a data scientist hands over a ML model to the ML engineer and moves on. Instead, it is continuous and iterative from the beginning of a project. When engaging with stakeholders, both parties have to scope out the requirements together and propose an initial solution, including the ML frameworks and path to production.
During the model building phase, ML engineers should also assist data scientists in setting up reusable model development pipelines or platforms. This not only makes experimentation of different ML models more efficient, it also enables outputs to be productionized easily.
Once the data scientist has developed one or more candidate machine learning models, these models can then be handed to the ML engineers. Then, the data scientist would provide an ML engineer with the specifications of candidate models and both of them would agree on the metric to be optimised (e.g. latency, memory).
The specifications that a data scientist should provide to an ML engineer may include:
- Training, validation and test datasets, including ground labels
- Model Predictions
- Model performance (e.g. precision, sensitivity, F1-score)
- Latency
- Memory
- Machine Learning or Deep Learning Framework used
- Model Versions
- Number of Parameters
With this information, ML engineers can further optimise and experiment with the ML model, subsequently deploying the best-performing model into production. After this handover, the data scientists can then concentrate on the next machine learning use case.
Even post-deployment, the collaboration between data scientists and ML engineers continues. Data scientists should continuously refine the machine learning model based on the live feedback while the model is in production. Moreover, it is common for a newly productionalised model to encounter issues while in production. In that case, both data scientists and ML engineers should both investigate it, however, the person that troubleshoots it depends on the problem. For example, if an ML model is performing poorly out of the blue, data scientists are best poised to debug it as they have a deeper understanding of the model. Conversely, if the break is caused by a bug in the underlying infrastructure that serves the ML model, then it falls within the ML engineer’s remit.
TL;DR What is the difference between a data scientist and Machine learning engineer?
A data scientist’s key responsibility is to understand business problems and develop one or more machine learning algorithms to solve them. Then, the specification of the ML models is handed over to ML engineers to be optimised and deployed to a large scale. In terms of skill set, both roles share many similarities such as communicating with confidence, version control and being proficient with cloud services. Conversely, both roles require vastly different domain knowledge; data scientists should be strong in statistics and business acumen, whereas ML engineers should be proficient in fundamental software engineering skills.
Written by Ivan Pua and Brad Jackson
